You might also like
- Homework8 Solutions EE131ADocument3 pagesHomework8 Solutions EE131AJohn TNo ratings yet
- HandbookDocument154 pagesHandbookTrisphere Media TechnologiesNo ratings yet
- Stimation: StatisticDocument46 pagesStimation: Statisticمحمد بركاتNo ratings yet
- Simple random sampling varianceDocument23 pagesSimple random sampling varianceShreyas SatardekarNo ratings yet
- FORMULA SHEET and The TABLESDocument10 pagesFORMULA SHEET and The TABLESWiSeVirGoNo ratings yet
- Lecture 13 NPTEL SAMPLING THEORYDocument8 pagesLecture 13 NPTEL SAMPLING THEORYNARENDRANo ratings yet
- ANOVA Test for Fabric StrengthDocument59 pagesANOVA Test for Fabric StrengthmadhavNo ratings yet
- Systematic Sampling: N N N K N NKDocument17 pagesSystematic Sampling: N N N K N NKDwi Satria FirmansyahNo ratings yet
- Simple Random SamplingDocument18 pagesSimple Random Samplinghimanshu pachouriNo ratings yet
- Stat 400, Section 6.1b Point Estimates of Mean and VarianceDocument3 pagesStat 400, Section 6.1b Point Estimates of Mean and VarianceDRizky Aziz SyaifudinNo ratings yet
- Recursive Estimation of Mean and VarianceDocument53 pagesRecursive Estimation of Mean and VarianceAmanifadia GarroudjiNo ratings yet
- Unbiased EstimatorDocument70 pagesUnbiased EstimatorSergioNo ratings yet
- Bijective Proof Problems: August 18, 2009Document70 pagesBijective Proof Problems: August 18, 2009nou channarith0% (1)
- Probable Error of a MeanDocument24 pagesProbable Error of a MeanMartin McflinNo ratings yet
- Chapter2 Sampling Simple Random SamplingDocument23 pagesChapter2 Sampling Simple Random SamplinghermitserbotNo ratings yet
- Central Limit Theorem ExplainedDocument8 pagesCentral Limit Theorem ExplainedRobert ManeaNo ratings yet
- Chapter2 Sampling Simple Random SamplingDocument24 pagesChapter2 Sampling Simple Random SamplingDr Swati RajNo ratings yet
- Sharp Bounds on Variance in Randomized Experiments (≤40 charsDocument30 pagesSharp Bounds on Variance in Randomized Experiments (≤40 chars何沛予No ratings yet
- Variance EstimationDocument2 pagesVariance EstimationMalkin DivyaNo ratings yet
- Synthetic Estimators Using AuxiliarDocument14 pagesSynthetic Estimators Using AuxiliarShamsNo ratings yet
- 2.1 The Wishart DistributionDocument4 pages2.1 The Wishart DistributionThrilling MeherabNo ratings yet
- Stat 5002 Final Exam Formulas W 21Document7 pagesStat 5002 Final Exam Formulas W 21PaolaCastelwhiteNo ratings yet
- 5 BSM214 Lecture5 Fall2023Document25 pages5 BSM214 Lecture5 Fall2023mf7059708No ratings yet
- Stratified Randon SamplingDocument32 pagesStratified Randon Samplinghimanshu pachouriNo ratings yet
- Formulas for statistical testsDocument15 pagesFormulas for statistical testsSaroj patelNo ratings yet
- Modulo 2 Congruences For Partitions With Initial RDocument16 pagesModulo 2 Congruences For Partitions With Initial RJames MlotshwaNo ratings yet
- Examination of The Proof of Riemann's HypothesisDocument71 pagesExamination of The Proof of Riemann's HypothesisNikos MantzakourasNo ratings yet
- Two Examples On Linear and Circular Convolution of Signals.: Example 1Document2 pagesTwo Examples On Linear and Circular Convolution of Signals.: Example 1Bharath RamNo ratings yet
- Sampling DistributionsDocument9 pagesSampling DistributionsjayNo ratings yet
- Summary of Topics For Midterm Exam #2: STA 371G, Fall 2017Document6 pagesSummary of Topics For Midterm Exam #2: STA 371G, Fall 2017amt801No ratings yet
- Probability and Statistics ch7Document19 pagesProbability and Statistics ch7digiy40095No ratings yet
- Theorem 5.3.1.: 1 N 2 N I 2 IDocument18 pagesTheorem 5.3.1.: 1 N 2 N I 2 IBenNo ratings yet
- Statistics 514 Design of Experiments Topic 2 OverviewDocument14 pagesStatistics 514 Design of Experiments Topic 2 OverviewVedha ThangavelNo ratings yet
- 11377-PDF File-44402-1-10-20230329Document10 pages11377-PDF File-44402-1-10-20230329Harold Hardy GodfreyNo ratings yet
- BQQ6214 STATISTICAL FORMULAE (1)Document3 pagesBQQ6214 STATISTICAL FORMULAE (1)Robert OoNo ratings yet
- Linear Regression via Maximization of the LikelihoodDocument6 pagesLinear Regression via Maximization of the LikelihoodAkansha KalraNo ratings yet
- Chapter 7Document30 pagesChapter 7Umer SharazNo ratings yet
- Week1 PDFDocument22 pagesWeek1 PDFJohana Coen JanssenNo ratings yet
- Stat171 NotesDocument82 pagesStat171 NotesnigerianhacksNo ratings yet
- Small Sample - T TestDocument4 pagesSmall Sample - T TestKarthick VNo ratings yet
- Simple Linear Regression Model and EstimatorsDocument1 pageSimple Linear Regression Model and EstimatorsInês CabralNo ratings yet
- Calculating variance and covariance: methods and formulasDocument3 pagesCalculating variance and covariance: methods and formulasGiorgia 1709No ratings yet
- The Probable Error of a Mean from Small SamplesDocument26 pagesThe Probable Error of a Mean from Small SamplesMistuEquisNo ratings yet
- Lecture Notes On Random Walks and Semiflexible Polymers Part (I) : StaticsDocument24 pagesLecture Notes On Random Walks and Semiflexible Polymers Part (I) : StaticsBJI ALUMNINo ratings yet
- Chapter 7 Systematic Sampling CompletedDocument14 pagesChapter 7 Systematic Sampling CompletedIshan ShethNo ratings yet
- Lect 3Document7 pagesLect 3Pratyush GuptaNo ratings yet
- Measures of Dispersion ExplainedDocument7 pagesMeasures of Dispersion ExplainedBloody Gamer Of BDNo ratings yet
- Student's T Distribution - Supplement To Chap-Ter 3Document3 pagesStudent's T Distribution - Supplement To Chap-Ter 3AYU JANNATULNo ratings yet
- Formula Sheet and Statistical TablesDocument19 pagesFormula Sheet and Statistical TablesArun ChowdaryNo ratings yet
- STAT 3008 Applied Regression Analysis Tutorial 1 - Term 2, 2019 20Document2 pagesSTAT 3008 Applied Regression Analysis Tutorial 1 - Term 2, 2019 20MingyanNo ratings yet
- Handout: Two Sample Hypothesis Testing and Inference ForDocument5 pagesHandout: Two Sample Hypothesis Testing and Inference Forsumanta1234No ratings yet
- Measures of Dispersion or Measures of VariabilityDocument6 pagesMeasures of Dispersion or Measures of Variabilitytasnimsamiha785No ratings yet
- Statistics: SampleDocument12 pagesStatistics: SampleDorian GreyNo ratings yet
- Digital Signal Processing FundamentalsDocument72 pagesDigital Signal Processing Fundamentalsblaze emberNo ratings yet
- Sample Size Estimation For Longitudinal Studies Don Hedeker University of Illinois at Chicago WWW - Uic.edu/ HedekerDocument58 pagesSample Size Estimation For Longitudinal Studies Don Hedeker University of Illinois at Chicago WWW - Uic.edu/ HedekerSamar AhmadNo ratings yet
- Mechanical MeasurementsDocument3 pagesMechanical MeasurementscaptainhassNo ratings yet
- Chapter12 Sampling Successive OccasionsDocument11 pagesChapter12 Sampling Successive OccasionsAbebe NegaNo ratings yet
- Statistics NotesDocument15 pagesStatistics NotesMarcus Pang Yi ShengNo ratings yet
- List of FormulaDocument3 pagesList of FormulaaqaazNo ratings yet
- Application of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsFrom EverandApplication of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsRating: 5 out of 5 stars5/5 (1)
- Random Fourier Series with Applications to Harmonic Analysis. (AM-101), Volume 101From EverandRandom Fourier Series with Applications to Harmonic Analysis. (AM-101), Volume 101No ratings yet
- ComputertraningbasicsDocument89 pagesComputertraningbasicsbldhaka100% (1)
- MCQ FungiDocument10 pagesMCQ Fungikrishna chandra100% (2)
- Mcqs-Business CommunicationDocument30 pagesMcqs-Business CommunicationAvii MukherjiNo ratings yet
- 5000 MCQs in BiochemistryDocument301 pages5000 MCQs in BiochemistryZia Ashraf Chaudhary94% (17)
- (A) Oilseed Shells (B) Groundnut Shells (C) Husk (D) Bagasse (E) AllDocument41 pages(A) Oilseed Shells (B) Groundnut Shells (C) Husk (D) Bagasse (E) AllbldhakaNo ratings yet
- (A) Oilseed Shells (B) Groundnut Shells (C) Husk (D) Bagasse (E) AllDocument41 pages(A) Oilseed Shells (B) Groundnut Shells (C) Husk (D) Bagasse (E) AllbldhakaNo ratings yet
- 48 EnterpreneurshipDocument274 pages48 Enterpreneurshiptamannaagarwal87No ratings yet
- Lec 05Document2 pagesLec 05bldhakaNo ratings yet
- Introduction To Computer Applications PDFDocument151 pagesIntroduction To Computer Applications PDFAngelNo ratings yet
- Unit Extension Education AN: StructureDocument17 pagesUnit Extension Education AN: StructurebldhakaNo ratings yet
- Expert System - ReviewDocument13 pagesExpert System - ReviewbldhakaNo ratings yet
- E AgriDocument13 pagesE AgribldhakaNo ratings yet
- Comparing Models of Information Seeking BehaviourDocument14 pagesComparing Models of Information Seeking BehaviourbldhakaNo ratings yet
- Social Process-IDocument13 pagesSocial Process-IbldhakaNo ratings yet
- Training EvaluationDocument49 pagesTraining EvaluationMuhammad Saqib AsifNo ratings yet
- Development Programmes of Post-Independence EraDocument2 pagesDevelopment Programmes of Post-Independence ErabldhakaNo ratings yet
- Leadership StylesiDocument3 pagesLeadership Stylesisnow807No ratings yet
- Agriculture Journalism: The Craft and IssuesDocument1 pageAgriculture Journalism: The Craft and IssuesbldhakaNo ratings yet
- Crash Course CHPT 1 PDFDocument20 pagesCrash Course CHPT 1 PDFKing KohliNo ratings yet
- Anatomy of a Digital Computer: Key Components and FunctionsDocument24 pagesAnatomy of a Digital Computer: Key Components and FunctionsanilkumarosmeNo ratings yet
- Intro To CommunicationDocument34 pagesIntro To CommunicationSONU0% (1)
- Growth of Agricultural Journalism and Agricultural Research Information Centre at ICARDocument10 pagesGrowth of Agricultural Journalism and Agricultural Research Information Centre at ICARbldhakaNo ratings yet
- 3 Common Latin Abbreviations PDFDocument2 pages3 Common Latin Abbreviations PDFBhanwar DhakaNo ratings yet
- Unit 9 Statistical Packages: 9.0 ObjectivesDocument16 pagesUnit 9 Statistical Packages: 9.0 ObjectivesbldhakaNo ratings yet
- Introduction To Research MethodsDocument78 pagesIntroduction To Research MethodsMarutiNo ratings yet
- Ba Sociology Essential SociologyDocument17 pagesBa Sociology Essential SociologyMark Diez100% (1)
- Tathapi: Agricultural Journalism: An Effective Tool For Agriculture DevelopmentDocument8 pagesTathapi: Agricultural Journalism: An Effective Tool For Agriculture DevelopmentbldhakaNo ratings yet
- IJAS - Yield Gap - Wheat PDFDocument3 pagesIJAS - Yield Gap - Wheat PDFbldhakaNo ratings yet
- Cbse Ix-X Social Science 2022-23 PisDocument52 pagesCbse Ix-X Social Science 2022-23 PisAditi JaniNo ratings yet
- Lecture 3Document10 pagesLecture 3Dr. Saad Saffah HresheeNo ratings yet
- Guidelines For Conducting Condition Assessment of Education FacilitiesDocument200 pagesGuidelines For Conducting Condition Assessment of Education FacilitiesMichael MatshonaNo ratings yet
- D4643Document5 pagesD4643Ruddy EspejoNo ratings yet
- WorkbookDocument7 pagesWorkbookᜃᜋᜒᜎ᜔ ᜀᜂᜇᜒᜈᜓ ᜋᜓᜆ᜔ᜑNo ratings yet
- Élan VitalDocument3 pagesÉlan Vitalleclub IntelligenteNo ratings yet
- Innatek BCST-50 BarCode Scanner Supplementary ManualDocument25 pagesInnatek BCST-50 BarCode Scanner Supplementary ManualBruno MagneNo ratings yet
- Nadia Ahmadieh CVDocument3 pagesNadia Ahmadieh CVNadia Ahmadieh-AboulmonaNo ratings yet
- PK Mitomycin C in LCMSDocument13 pagesPK Mitomycin C in LCMSRuthNo ratings yet
- Procurement of Land in Indonesia: Challenges and Solutions in the Legal Sociological PerspectiveDocument12 pagesProcurement of Land in Indonesia: Challenges and Solutions in the Legal Sociological PerspectiveFrans OleyNo ratings yet
- UntitledDocument76 pagesUntitledjaiNo ratings yet
- MECHATRONICSSYSTEMSDocument12 pagesMECHATRONICSSYSTEMSAbolaji MuazNo ratings yet
- IE423 PS1 Probability and Statistics Review QuestionsDocument5 pagesIE423 PS1 Probability and Statistics Review QuestionsYasemin YücebilgenNo ratings yet
- Research Leadership As A Predictor of Research CompetenceDocument7 pagesResearch Leadership As A Predictor of Research CompetenceMonika GuptaNo ratings yet
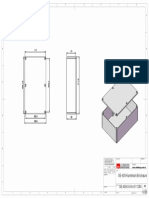
- SE-409 Aluminium Enclosure SE-409-0-0-A-0-11284: RevisionDocument1 pageSE-409 Aluminium Enclosure SE-409-0-0-A-0-11284: RevisionAhmet MehmetNo ratings yet
- Ratio & Proport-WPS OfficeDocument43 pagesRatio & Proport-WPS OfficeRovelyn Sangalang CabreraNo ratings yet
- BC846WDocument8 pagesBC846WBrunoNo ratings yet
- Unit SpaceDocument7 pagesUnit SpaceEnglish DepNo ratings yet
- Questions of Reliability Centered MaintenanceDocument15 pagesQuestions of Reliability Centered Maintenancemariana100% (1)
- Comparing Male and Female Reproductive SystemsDocument11 pagesComparing Male and Female Reproductive SystemsRia Biong TaripeNo ratings yet
- Leadership and Management ModuleDocument6 pagesLeadership and Management ModuleMichael AngelesNo ratings yet
- Phonons 1-D Linear Chain of AtomsDocument12 pagesPhonons 1-D Linear Chain of Atomsمؤيد العليNo ratings yet
- Environmental Considerations For Pipeline Abandonment - A Case Study From Abandonment of A Southern Alberta PipelineDocument7 pagesEnvironmental Considerations For Pipeline Abandonment - A Case Study From Abandonment of A Southern Alberta PipelineRUSSEL SAHDA MALAKANo ratings yet
- CAEN A2518 Rev16Document18 pagesCAEN A2518 Rev16Arnaud RomainNo ratings yet
- Catholic High School of Pilar Brix James DoralDocument3 pagesCatholic High School of Pilar Brix James DoralMarlon James TobiasNo ratings yet
- Pragmatics Kel 2Document10 pagesPragmatics Kel 2i iNo ratings yet
- Chapter 2 Soil-Water-PlantDocument44 pagesChapter 2 Soil-Water-PlantReffisa JiruNo ratings yet
- Zhao Et Al 2012Document10 pagesZhao Et Al 2012Mohd Sofiyan Bin SulaimanNo ratings yet
- Formulating Rules in Finding The NTH TermDocument17 pagesFormulating Rules in Finding The NTH TermMaximino Eduardo SibayanNo ratings yet