You might also like
- Spark RDD Dataframes SQLDocument3 pagesSpark RDD Dataframes SQLleongladxtonNo ratings yet
- Hive CommandsDocument3 pagesHive CommandspkumarssNo ratings yet
- Hadoop Realtime IssuesDocument3 pagesHadoop Realtime Issuesjey011851No ratings yet
- Essential HDFS Commands for Managing Files and DirectoriesDocument15 pagesEssential HDFS Commands for Managing Files and DirectoriespawanNo ratings yet
- Unix - Day 1: Intermediate LevelDocument46 pagesUnix - Day 1: Intermediate LevelPraveen KumarNo ratings yet
- JavascriptDocument145 pagesJavascriptsarthak pasrichaNo ratings yet
- Java Servlets: M. L. LiuDocument31 pagesJava Servlets: M. L. LiuOm Bala100% (1)
- Apache Spark TutorialsDocument9 pagesApache Spark Tutorialsronics123No ratings yet
- Sqoop Commands - LatestDocument4 pagesSqoop Commands - LatestH S Manju NathNo ratings yet
- Report SQL PDFDocument21 pagesReport SQL PDFRambabu AlokamNo ratings yet
- JavascriptDocument113 pagesJavascriptNiranjanNo ratings yet
- Sqoop DemoDocument7 pagesSqoop DemoJyotirmay SahuNo ratings yet
- Hands On Exercises 2013Document51 pagesHands On Exercises 2013Manish JainNo ratings yet
- HadoopDocument30 pagesHadoopSAM7028No ratings yet
- Sqoop CheatsheetDocument3 pagesSqoop CheatsheetPremKumar SivanandanNo ratings yet
- Hadoop Installation Step by StepDocument6 pagesHadoop Installation Step by StepUmesh NagarNo ratings yet
- HDFSDocument6 pagesHDFSSiddharth Bubbul100% (2)
- Guided By:: Miss. Rupali ZambreDocument20 pagesGuided By:: Miss. Rupali ZambrejohnNo ratings yet
- HadoopDocument7 pagesHadoopAmaleswarNo ratings yet
- ResumeDocument4 pagesResumeshekharNo ratings yet
- SqoopTutorial Ver 2.0Document51 pagesSqoopTutorial Ver 2.0bujjijulyNo ratings yet
- HDFS Interview Questions - Top 15 HDFS Questions AnsweredDocument29 pagesHDFS Interview Questions - Top 15 HDFS Questions Answeredanuja shindeNo ratings yet
- MySQL and Postgres command equivalents cheat sheetDocument7 pagesMySQL and Postgres command equivalents cheat sheetkishore_m_kNo ratings yet
- Top 100 Hadoop Interview QuestionsDocument17 pagesTop 100 Hadoop Interview QuestionspatriciaNo ratings yet
- 049 Hadoop Commands Reference Guide.Document3 pages049 Hadoop Commands Reference Guide.vaasu1No ratings yet
- Bootstrap 4Document376 pagesBootstrap 4Amazing DALVINo ratings yet
- New Informatica Concepts - DayDocument98 pagesNew Informatica Concepts - DayChanukya Reddy MekalaNo ratings yet
- HiveDocument17 pagesHivepruphiphisNo ratings yet
- (Amazon Web Services) : Training OnDocument5 pages(Amazon Web Services) : Training Onrakesh manuNo ratings yet
- Final Practice SetDocument31 pagesFinal Practice SetswagatNo ratings yet
- Hive Commands SimplinDocument5 pagesHive Commands Simplinmarina duttaNo ratings yet
- Web Tech & Python Questionnaire AnswersDocument53 pagesWeb Tech & Python Questionnaire AnswersRahul SharmaNo ratings yet
- Ashok 2+Document4 pagesAshok 2+Ram RamarajuNo ratings yet
- 18 Months With ScalaDocument38 pages18 Months With Scalablue.remix3959No ratings yet
- Terminal: The Basics: General InformationDocument7 pagesTerminal: The Basics: General Informationjoannaa_castilloNo ratings yet
- CSS3 Skill Test Top 20Document28 pagesCSS3 Skill Test Top 20ShalabhNo ratings yet
- Module10 BigData PDFDocument4 pagesModule10 BigData PDFsrinubasaniNo ratings yet
- Spark Summit East 2015 - Adv Dev Ops - Student SlidesDocument219 pagesSpark Summit East 2015 - Adv Dev Ops - Student SlidesChánh LêNo ratings yet
- Unix Training by DhanabalDocument340 pagesUnix Training by DhanabalLeo ThomasNo ratings yet
- BIG DATA WITH HADOOP, HDFS & MAPREDUCE (Hands On Training)Document35 pagesBIG DATA WITH HADOOP, HDFS & MAPREDUCE (Hands On Training)D.KESAVARAJANo ratings yet
- ADO.netDocument64 pagesADO.netKumar AnupamNo ratings yet
- HOL HiveDocument85 pagesHOL HiveKishore KumarNo ratings yet
- HiveDocument3 pagesHiveudNo ratings yet
- Pyspark FuncamentalsDocument10 pagesPyspark FuncamentalsmamathaNo ratings yet
- Linux Command ListDocument8 pagesLinux Command ListhkneptuneNo ratings yet
- Hive For SQL Users: Cheat SheetDocument3 pagesHive For SQL Users: Cheat Sheetsrikanth07balusuNo ratings yet
- Hadoop and Spark Developer ResumeDocument3 pagesHadoop and Spark Developer Resumessinha122No ratings yet
- File Watcher For Control-MDocument12 pagesFile Watcher For Control-MSaurabh TandonNo ratings yet
- How To Install JDK 8 (On Windows, Mac OS, Ubuntu)Document11 pagesHow To Install JDK 8 (On Windows, Mac OS, Ubuntu)MSHAIKHAXNo ratings yet
- Informatic 8-Training-BISP PDFDocument271 pagesInformatic 8-Training-BISP PDFahmed_sftNo ratings yet
- 24 Hadoop Interview Questions & AnswersDocument7 pages24 Hadoop Interview Questions & AnswersnalinbhattNo ratings yet
- Bigdata NotesDocument26 pagesBigdata NotesAnil YarlagaddaNo ratings yet
- Query array elements in MongoDBDocument16 pagesQuery array elements in MongoDBchrisNo ratings yet
- Taking An Exam: ProctoringDocument55 pagesTaking An Exam: ProctoringJahikoNo ratings yet
- Modern Web Applications with Next.JS: Learn Advanced Techniques to Build and Deploy Modern, Scalable and Production Ready React Applications with Next.JSFrom EverandModern Web Applications with Next.JS: Learn Advanced Techniques to Build and Deploy Modern, Scalable and Production Ready React Applications with Next.JSNo ratings yet
- Assignment Day 10: Task 1Document8 pagesAssignment Day 10: Task 1marina duttaNo ratings yet
- TelevisionDocument1 pageTelevisionmarina duttaNo ratings yet
- Assignment 10Document9 pagesAssignment 10marina duttaNo ratings yet
- Setting Up Spark 2.0 With Intellij Community EditionDocument12 pagesSetting Up Spark 2.0 With Intellij Community Editionamitkm21No ratings yet
- Hive Commands Acadgild BucketingDocument2 pagesHive Commands Acadgild Bucketingmarina duttaNo ratings yet
- Assignment Day 10: Task 1Document8 pagesAssignment Day 10: Task 1marina duttaNo ratings yet
- Hive Commands SimplinDocument5 pagesHive Commands Simplinmarina duttaNo ratings yet
- Sqoop Commands AG PDFDocument2 pagesSqoop Commands AG PDFmarina duttaNo ratings yet
- Assignment 10Document9 pagesAssignment 10marina duttaNo ratings yet
- Assignment Day 10: Task 1Document8 pagesAssignment Day 10: Task 1marina duttaNo ratings yet
- Assignment 10Document9 pagesAssignment 10marina duttaNo ratings yet
- Kafka2 PDFDocument3 pagesKafka2 PDFmarina duttaNo ratings yet
- FileDocument1 pageFilemarina duttaNo ratings yet
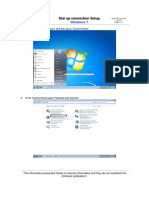
- Windows 7 Dial-Up Connection Setup GuideDocument7 pagesWindows 7 Dial-Up Connection Setup GuideMikeNo ratings yet
- A Case Study On Strategies To Deal With The Impacts of COVID-19 Pandemic in The Food and Beverage IndustryDocument13 pagesA Case Study On Strategies To Deal With The Impacts of COVID-19 Pandemic in The Food and Beverage IndustryPeyman KazemianhaddadiNo ratings yet
- Incremental Analysis Decision MakingDocument4 pagesIncremental Analysis Decision MakingMa Teresa B. CerezoNo ratings yet
- GDRatingDocument13 pagesGDRatingdgzaquinojcNo ratings yet
- Aluminio 2024-T3Document2 pagesAluminio 2024-T3IbsonhNo ratings yet
- KETRACO Clarifies Technical Queries for 400kV Transmission ProjectDocument5 pagesKETRACO Clarifies Technical Queries for 400kV Transmission Projectahmadove1No ratings yet
- bài tập ôn MA1Document34 pagesbài tập ôn MA1Thái DươngNo ratings yet
- Study On Intel 80386 MicroprocessorDocument3 pagesStudy On Intel 80386 MicroprocessorInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Digital Marketing - Scope Opportunities and Challenges - IntechOpen PDFDocument31 pagesDigital Marketing - Scope Opportunities and Challenges - IntechOpen PDFPratsNo ratings yet
- CriticalAppraisalWorksheetTherapy EffectSizeDocument2 pagesCriticalAppraisalWorksheetTherapy EffectSizeFitriArdiningsihNo ratings yet
- Calculus (Solution To Assignment Iv) : February 12, 2012Document4 pagesCalculus (Solution To Assignment Iv) : February 12, 2012Mawuena MelomeyNo ratings yet
- Collateral Asset DefinitionsDocument116 pagesCollateral Asset Definitionsapi-3748391100% (2)
- Hantavirus Epi AlertDocument4 pagesHantavirus Epi AlertSutirtho MukherjiNo ratings yet
- Update ResumeDocument3 pagesUpdate ResumeSubbareddy NvNo ratings yet
- CH 6 SandwichesDocument10 pagesCH 6 SandwichesKrishna ChaudharyNo ratings yet
- Product Information: Automotive Sensor UMRR-96 TYPE 153Document18 pagesProduct Information: Automotive Sensor UMRR-96 TYPE 153CORAL ALONSONo ratings yet
- KK 080711 HancockDocument1 pageKK 080711 HancockkatehasablogNo ratings yet
- Breaking Into Software Defined Radio: Presented by Kelly AlbrinkDocument40 pagesBreaking Into Software Defined Radio: Presented by Kelly AlbrinkChris Guarin100% (1)
- Dryspell+ ManualDocument71 pagesDryspell+ ManualAldo D'AndreaNo ratings yet
- Finite Element and Analytical Modelling of PVC-confined Concrete Columns Under Axial CompressionDocument23 pagesFinite Element and Analytical Modelling of PVC-confined Concrete Columns Under Axial CompressionShaker QaidiNo ratings yet
- Nanosafety Exam QuestionsDocument4 pagesNanosafety Exam QuestionsMulugetaNo ratings yet
- Tunisia - Country Profile: 1 Background 2 2 Population 2Document18 pagesTunisia - Country Profile: 1 Background 2 2 Population 2stand4xNo ratings yet
- Statistical Theory and Analysis in Bioassay OverviewDocument11 pagesStatistical Theory and Analysis in Bioassay OverviewEgbuna ChukwuebukaNo ratings yet
- 2022-2023 Enoch Calendar: Northern HemisphereDocument14 pages2022-2023 Enoch Calendar: Northern HemisphereThakuma YuchiiNo ratings yet
- 5 Harms of Excessive Use of Electronic GamesDocument3 pages5 Harms of Excessive Use of Electronic GamesPierre MarucciNo ratings yet
- SMEDA (Small and Medium Enterprises Development Authority)Document29 pagesSMEDA (Small and Medium Enterprises Development Authority)Salwa buriroNo ratings yet
- Bridal Boutique Business Plan SummaryDocument35 pagesBridal Boutique Business Plan Summarykira5729No ratings yet
- Reg0000007635187Document2 pagesReg0000007635187Amal JimmyNo ratings yet
- Java Layout ManagersDocument16 pagesJava Layout ManagersVijaya Kumar VadladiNo ratings yet
- AshfaqDocument9 pagesAshfaqAnonymous m29snusNo ratings yet