You might also like
- ch07 PDFDocument85 pagesch07 PDFNadya Azzan100% (2)
- 3.multiple Linear Regression - Jupyter NotebookDocument5 pages3.multiple Linear Regression - Jupyter NotebookAnuvidyaKarthiNo ratings yet
- Bachelor of Computer Applications (BCA) (Revised) Term-End Examination June, 2021 Bcs-040: Statistical TechniquesDocument5 pagesBachelor of Computer Applications (BCA) (Revised) Term-End Examination June, 2021 Bcs-040: Statistical TechniquesDilbagh SinghNo ratings yet
- Sat QPDocument4 pagesSat QPjesimayasminj131No ratings yet
- Practice QuestionsDocument3 pagesPractice QuestionsOsama bin adnanNo ratings yet
- CSCI 4707 - Written Submission 3 Solutions: Question# Sections Max Score Details ScoreDocument16 pagesCSCI 4707 - Written Submission 3 Solutions: Question# Sections Max Score Details ScoreKHUSHI MAHESHWARINo ratings yet
- 08 Chapter 5Document48 pages08 Chapter 5Surbhi MahendruNo ratings yet
- TIE6111201412 Design, Analysis and Control of Manufacturing SystemsDocument5 pagesTIE6111201412 Design, Analysis and Control of Manufacturing Systemstafara mundereNo ratings yet
- TRE - Pavement Design - GRP 5Document25 pagesTRE - Pavement Design - GRP 5Ayush TripathiNo ratings yet
- Rayalaseema Institute of Information and Management Sciences (RIMS)Document1 pageRayalaseema Institute of Information and Management Sciences (RIMS)Pallamala Kalyan PKNo ratings yet
- Bond Index PCA ReplicacionDocument58 pagesBond Index PCA ReplicacionricardeusNo ratings yet
- Introduction To SubjectDocument2 pagesIntroduction To SubjectsarmadaliaquariusNo ratings yet
- SyllabusDocument8 pagesSyllabuselsonpaul100% (1)
- DS AssignmentDocument4 pagesDS Assignment19202199No ratings yet
- CS2 CMP Upgrade 2022Document128 pagesCS2 CMP Upgrade 2022ChahelNo ratings yet
- Statistical Quality Control 7Th Edition Montgomery Solutions Manual Full Chapter PDFDocument67 pagesStatistical Quality Control 7Th Edition Montgomery Solutions Manual Full Chapter PDFMrsSydneyBennettMDjnkc100% (9)
- K.S. School of Engineering and Management, Bangalore - 560109Document2 pagesK.S. School of Engineering and Management, Bangalore - 560109Pradeep BiradarNo ratings yet
- Function Point Manual CalculationDocument2 pagesFunction Point Manual CalculationRubak Daniel WNo ratings yet
- Report On Experiment 05: Design Using Frequency Domain MethodsDocument2 pagesReport On Experiment 05: Design Using Frequency Domain MethodsRahul SinghNo ratings yet
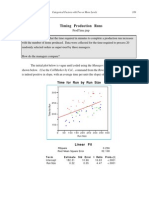
- Timing Production Runs: Class 7 Categorical Factors With Two or More Levels 189Document9 pagesTiming Production Runs: Class 7 Categorical Factors With Two or More Levels 189tomk2220No ratings yet
- Oct 2018Document487 pagesOct 2018udayNo ratings yet
- Activity - Location DecisionsDocument2 pagesActivity - Location DecisionsMarissa C BautistaNo ratings yet
- Mba Zc417 Ec-2r First Sem 2022-2023 Revised PaperDocument2 pagesMba Zc417 Ec-2r First Sem 2022-2023 Revised PaperRavi KaviNo ratings yet
- Mba ZC417 Ec-2r First Sem 2022-2023 Revised PaperDocument2 pagesMba ZC417 Ec-2r First Sem 2022-2023 Revised PaperEswar ReddyNo ratings yet
- New Stats QUETIONSDocument2 pagesNew Stats QUETIONSbaranidharan .kNo ratings yet
- Industrial ManAgementDocument3 pagesIndustrial ManAgementSayantan DexNo ratings yet
- Structure of MIS: Lai PrabhakarDocument45 pagesStructure of MIS: Lai PrabhakarJenifer Oinam100% (1)
- B.Tech - CSE and CS Syllabus of 3rd Year July 2020Document36 pagesB.Tech - CSE and CS Syllabus of 3rd Year July 2020Durgesh MauryaNo ratings yet
- Kanban at SAPDocument46 pagesKanban at SAPJorge LuisNo ratings yet
- B.Tech - CS - Design 3rd Year Year 2023-24Document33 pagesB.Tech - CS - Design 3rd Year Year 2023-24Aashik HussainNo ratings yet
- Lahore School of EconomicsDocument10 pagesLahore School of EconomicsMahnoorNo ratings yet
- QF 2 PP 2015Document9 pagesQF 2 PP 2015Revatee HurilNo ratings yet
- Demand Forecasting in A Railway Revenue Management SystemDocument87 pagesDemand Forecasting in A Railway Revenue Management SystemPablo DoalloNo ratings yet
- AssigmentDocument5 pagesAssigmentSamar QadirNo ratings yet
- Reliability Evaluation of Composite System With Aging FailureDocument8 pagesReliability Evaluation of Composite System With Aging FailureIJAR JOURNALNo ratings yet
- ReliabilityDocument27 pagesReliabilityJessie Radaza Tutor100% (2)
- Routing and Switching Midter sp21Document12 pagesRouting and Switching Midter sp21Bachkana GarmentsNo ratings yet
- Iem 2103 (2022-2015)Document13 pagesIem 2103 (2022-2015)ahnafmahbub05No ratings yet
- Eco Assignment NDocument8 pagesEco Assignment NshambelNo ratings yet
- CAF3 GridDocument1 pageCAF3 Gridahmaddanyal480No ratings yet
- GB MockexamDocument24 pagesGB MockexamAnonymous 7K9pzvziNo ratings yet
- Rayleigh ModelDocument9 pagesRayleigh ModelKaran GuptaNo ratings yet
- StatisticsDocument7 pagesStatisticsbellecat2011No ratings yet
- Routing and Switching MidterDocument10 pagesRouting and Switching MidterBachkana GarmentsNo ratings yet
- 15ecsc704 576 Kle54-Ecsc704Document5 pages15ecsc704 576 Kle54-Ecsc704Aniket AmbekarNo ratings yet
- Quantrivanhanh-Chuong 7 Tieng AnhDocument69 pagesQuantrivanhanh-Chuong 7 Tieng Anh21132138No ratings yet
- 1424QuantitativeMethodsBusinessII SepOct2022Document3 pages1424QuantitativeMethodsBusinessII SepOct2022supritha724No ratings yet
- Final DocumentDocument73 pagesFinal DocumentAjay DakuriNo ratings yet
- Michael Pidd PDFDocument331 pagesMichael Pidd PDFFadhiil AkmalNo ratings yet
- May Jun 2018Document3 pagesMay Jun 2018Nimbalkar KaustubhNo ratings yet
- ME 2008 PaperDocument949 pagesME 2008 PaperPRAMOD KESHAV KOLASENo ratings yet
- Scheme Syllabus 5 6 - 2018 2022Document58 pagesScheme Syllabus 5 6 - 2018 2022Ashish laldwaniNo ratings yet
- Problem Set Ee8205 PDFDocument4 pagesProblem Set Ee8205 PDFksajjNo ratings yet
- Industrial ManagementDocument2 pagesIndustrial ManagementSayantan DexNo ratings yet
- MINI PROJECT REPORT (Centrifugal Pump)Document54 pagesMINI PROJECT REPORT (Centrifugal Pump)HEMANT SONINo ratings yet
- Btech Oe 8 Sem Quality Management Koe 085 2023Document2 pagesBtech Oe 8 Sem Quality Management Koe 085 2023Suraj kumarNo ratings yet
- BSCN5 - 01 - I - Marking GuideDocument3 pagesBSCN5 - 01 - I - Marking GuidetinashemambarizaNo ratings yet
- CAInter - COSTING - Paper Analysis... .Document8 pagesCAInter - COSTING - Paper Analysis... .babuvenkatesh566No ratings yet
- Impact of Corruption On EconomyDocument9 pagesImpact of Corruption On EconomyHi RaNo ratings yet
- University of Gujrat Research Methodology Bs-Software Engineering Assignment - 2 SE-6-B Submitted byDocument3 pagesUniversity of Gujrat Research Methodology Bs-Software Engineering Assignment - 2 SE-6-B Submitted byHi RaNo ratings yet
- Impect of CurruptionDocument6 pagesImpect of CurruptionHi RaNo ratings yet
- Research Methodology: University of GujratDocument3 pagesResearch Methodology: University of GujratHi RaNo ratings yet
- Software Development and Application: University of GujratDocument6 pagesSoftware Development and Application: University of GujratHi RaNo ratings yet
- Course Outline of STAT-205: Probability and StatisticsDocument1 pageCourse Outline of STAT-205: Probability and StatisticsHi RaNo ratings yet
- Assignment 01 - OOSE PDFDocument1 pageAssignment 01 - OOSE PDFHi Ra0% (1)
- Blomberg FNT 9670 and FNT 9670 X (No ''FNT 9670 T'') (English + Hebrew)Document55 pagesBlomberg FNT 9670 and FNT 9670 X (No ''FNT 9670 T'') (English + Hebrew)TalNo ratings yet
- Insider TradingDocument14 pagesInsider TradingSyed Nabeel Ahmed WarsiNo ratings yet
- MadTech - A Revolution Between Martech and AdtechDocument7 pagesMadTech - A Revolution Between Martech and AdtechDigitalkites OfficialNo ratings yet
- HVR WhitePaper Continuous Data IntegrationDocument8 pagesHVR WhitePaper Continuous Data Integrationrobin69hNo ratings yet
- Blade Shape Optimization of The Savonius Wind Turbine Using A GeneticDocument10 pagesBlade Shape Optimization of The Savonius Wind Turbine Using A GeneticMedy SitorusNo ratings yet
- Sipat - 660 MW Super Critical Boiler PresentationDocument55 pagesSipat - 660 MW Super Critical Boiler PresentationParveen NakwalNo ratings yet
- Diagramas Electricos Ka 2012 EuroDocument42 pagesDiagramas Electricos Ka 2012 EuroleitopilotoNo ratings yet
- GU-612 - v3.1 - Guidelines - Incident Investigation and Reporting v1Document185 pagesGU-612 - v3.1 - Guidelines - Incident Investigation and Reporting v1rwerwerw100% (3)
- New Approach To Arc Resistance CalculationDocument7 pagesNew Approach To Arc Resistance Calculationyannick.pratte8709No ratings yet
- Ultem 1010 PyrogenicityDocument26 pagesUltem 1010 Pyrogenicitystalker akoNo ratings yet
- Mtech SyllabusDocument55 pagesMtech SyllabusNithya MohanNo ratings yet
- Mang Kanor Trading Blueprint (10!19!15)Document237 pagesMang Kanor Trading Blueprint (10!19!15)Getto Pangandoyon0% (1)
- Financial Management - MGT201: 7 Week of LecturesDocument10 pagesFinancial Management - MGT201: 7 Week of LecturesSyed Abdul Mussaver ShahNo ratings yet
- Company Analysis Of: Prof. Nikhil Ranjan Barat Dr. Kaustav GhoshDocument17 pagesCompany Analysis Of: Prof. Nikhil Ranjan Barat Dr. Kaustav GhoshPiyali BhattacharjeeNo ratings yet
- Computation OF Dead Loads: Surigao State College of TechnologyDocument26 pagesComputation OF Dead Loads: Surigao State College of TechnologyRbcabajes ButalonNo ratings yet
- Operating Instructions Flexi Classic Modular Safety Controller en IM0019092Document124 pagesOperating Instructions Flexi Classic Modular Safety Controller en IM0019092Bruno EvaristoNo ratings yet
- 1 s2.0 S0038092X12002150 MainA Cell To Module To Array Detailed Model For Photovoltaic PanelsDocument12 pages1 s2.0 S0038092X12002150 MainA Cell To Module To Array Detailed Model For Photovoltaic PanelsRendy Adhi RachmantoNo ratings yet
- Particularly Sensitive Sea Areas (Pssas) and Marine Environmentally High Risk Areas (Mehras)Document10 pagesParticularly Sensitive Sea Areas (Pssas) and Marine Environmentally High Risk Areas (Mehras)Polaris BridgemanNo ratings yet
- Secugrid Range: No Limits With TheDocument4 pagesSecugrid Range: No Limits With TheDinesh PoudelNo ratings yet
- Unauthorised: Certificate of Inspection For Import of Products From Organic Production Into The European UnionDocument2 pagesUnauthorised: Certificate of Inspection For Import of Products From Organic Production Into The European UnionIndriani widya utariNo ratings yet
- Test Papers For FICODocument4 pagesTest Papers For FICOManohar G ShankarNo ratings yet
- Midterm s02 SolnsDocument13 pagesMidterm s02 SolnsMuhammad Harun Al RasyidNo ratings yet
- Ofcom Site Blocking Report With Redactions RemovedDocument56 pagesOfcom Site Blocking Report With Redactions RemovedTJ McIntyreNo ratings yet
- Documents - Pub Frankfinn Travel Assignment 55b0f8cdb266bDocument78 pagesDocuments - Pub Frankfinn Travel Assignment 55b0f8cdb266bSidhu RajputNo ratings yet
- Watermelon BoxDocument5 pagesWatermelon BoxHary Prawira DharmaNo ratings yet
- Ch6 Performance Appraisal 1Document22 pagesCh6 Performance Appraisal 1Aditi Hebli0% (1)
- OssimDocument16 pagesOssimCRICRI1985No ratings yet
- WEEDS and PestsDocument35 pagesWEEDS and PestsolawedabbeyNo ratings yet
- Ironpump PDFDocument14 pagesIronpump PDFrpicho0% (1)
- Engine: Motorcycle CatalogueDocument86 pagesEngine: Motorcycle CatalogueJulito Santa CruzNo ratings yet