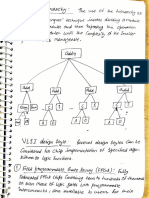
You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (844)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5811)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Dokumen - Pub - Embedded Systems 9788122434989 8122434983Document255 pagesDokumen - Pub - Embedded Systems 9788122434989 8122434983Murat Yasar ERTASNo ratings yet
- OceanStor Dorado V6 6.0.0 Differences Between Dorado V6 and Dorado V3Document47 pagesOceanStor Dorado V6 6.0.0 Differences Between Dorado V6 and Dorado V3Evgeny ElkinNo ratings yet
- Course - DBMS: Course Instructor Dr. K. Subrahmanyam Department of CSEDocument58 pagesCourse - DBMS: Course Instructor Dr. K. Subrahmanyam Department of CSEAvinash Alla100% (1)
- Database Management Systems 19CS2108Document21 pagesDatabase Management Systems 19CS2108Avinash AllaNo ratings yet
- An ER Diagram Is A Pictorial Representation of The Information That Can Be Captured by A Database. Such A "Picture" Serves Two PurposesDocument23 pagesAn ER Diagram Is A Pictorial Representation of The Information That Can Be Captured by A Database. Such A "Picture" Serves Two PurposesAvinash AllaNo ratings yet
- Database Management Systems 19CS2108Document26 pagesDatabase Management Systems 19CS2108Avinash AllaNo ratings yet
- Session 4Document26 pagesSession 4Avinash AllaNo ratings yet
- In E-R Model, We Have Discussed TheDocument24 pagesIn E-R Model, We Have Discussed TheAvinash AllaNo ratings yet
- Topics Covered in Todays Class: Unit 1: More Complex SQL QueriesDocument74 pagesTopics Covered in Todays Class: Unit 1: More Complex SQL QueriesAvinash AllaNo ratings yet
- 19Cs1203 - Object Oriented Programming: 10 MarksDocument1 page19Cs1203 - Object Oriented Programming: 10 MarksAvinash AllaNo ratings yet
- Order in Which Nodes Are ExpandedDocument10 pagesOrder in Which Nodes Are ExpandedAvinash AllaNo ratings yet
- Artificial Intelligence Lab-2Document8 pagesArtificial Intelligence Lab-2Avinash Alla100% (1)
- 19Cs1203 - Object Oriented Programming: 10 MarksDocument1 page19Cs1203 - Object Oriented Programming: 10 MarksAvinash AllaNo ratings yet
- Course - Database Management Systems (DBMS) : Course Instructor Dr. K. Subrahmanyam Department of CSE, KLUDocument92 pagesCourse - Database Management Systems (DBMS) : Course Instructor Dr. K. Subrahmanyam Department of CSE, KLUAvinash AllaNo ratings yet
- Session-5 Uninformed Search Strategies and Informed Search StrategiesDocument6 pagesSession-5 Uninformed Search Strategies and Informed Search StrategiesAvinash AllaNo ratings yet
- Session 2Document14 pagesSession 2Avinash AllaNo ratings yet
- 19ec1101 Co2 PDFDocument1 page19ec1101 Co2 PDFAvinash AllaNo ratings yet
- Session - 1 Course Hand Out Explanation & Introduction To Artificial IntelligenceDocument10 pagesSession - 1 Course Hand Out Explanation & Introduction To Artificial IntelligenceAvinash AllaNo ratings yet
- To Unix File System: Session No:4 Operating System Design @KL University, 2020Document28 pagesTo Unix File System: Session No:4 Operating System Design @KL University, 2020Avinash AllaNo ratings yet
- Session-6 A SearchDocument10 pagesSession-6 A SearchAvinash AllaNo ratings yet
- Session-4 Formulating A Given Problem As A Linear Programming Problem (LPP)Document12 pagesSession-4 Formulating A Given Problem As A Linear Programming Problem (LPP)Avinash AllaNo ratings yet
- Session-5 Simplex Method: University. All Rights ReservedDocument7 pagesSession-5 Simplex Method: University. All Rights ReservedAvinash AllaNo ratings yet
- Session-3 Finding The Optimal Solution Using Graphical Method For A Given Linear Programming Problem (LPP)Document16 pagesSession-3 Finding The Optimal Solution Using Graphical Method For A Given Linear Programming Problem (LPP)Avinash AllaNo ratings yet
- Questions AnsweredDocument20 pagesQuestions AnsweredAvinash AllaNo ratings yet
- Session-2 Mathematical Modeling of Linear Programming ProblemDocument31 pagesSession-2 Mathematical Modeling of Linear Programming ProblemAvinash AllaNo ratings yet
- Double Linked ListDocument3 pagesDouble Linked ListAvinash AllaNo ratings yet
- BEC Reading Pages - 28-51Document24 pagesBEC Reading Pages - 28-51Avinash AllaNo ratings yet
- Session - 2 - Lecture Notes - Operating-System Design Approaches PDFDocument15 pagesSession - 2 - Lecture Notes - Operating-System Design Approaches PDFAvinash AllaNo ratings yet
- K L Deemed To Be University Department of Computer Science and EngineeringDocument23 pagesK L Deemed To Be University Department of Computer Science and EngineeringAvinash AllaNo ratings yet
- Part A (Answer Both Questions 2 X 5 10)Document1 pagePart A (Answer Both Questions 2 X 5 10)Avinash AllaNo ratings yet
- Operating Systems Design: Session 3: OS InterfaceDocument21 pagesOperating Systems Design: Session 3: OS InterfaceAvinash AllaNo ratings yet
- 19ec1101 Co1 PDFDocument1 page19ec1101 Co1 PDFAvinash AllaNo ratings yet
- Entire HLON Fault (ERR - ALL - HALL) : Point of Detection ApplicationDocument1 pageEntire HLON Fault (ERR - ALL - HALL) : Point of Detection ApplicationDaniel GatdulaNo ratings yet
- Computer Graphics: DEP 5844 4 Semesters 1800 HoursDocument2 pagesComputer Graphics: DEP 5844 4 Semesters 1800 Hoursstephany pulidoNo ratings yet
- Final Revision LogicDocument66 pagesFinal Revision LogicKirillus MaherNo ratings yet
- Vlsi NotesDocument9 pagesVlsi NotesVipin RajputNo ratings yet
- Device Type Brand Model Version FCCID Availability Supported Current Rel Unsupported Functions BootloaderDocument56 pagesDevice Type Brand Model Version FCCID Availability Supported Current Rel Unsupported Functions BootloaderFelipeNo ratings yet
- HP Elitebook 8440p 8840W Compal LA-4902P UMA Rev 1.0 Schematics PDFDocument47 pagesHP Elitebook 8440p 8840W Compal LA-4902P UMA Rev 1.0 Schematics PDFJose Luis CANo ratings yet
- Stick Diagrams by S.N.bhat, Lecturer, Dept of EC Engg., M.I.T ...Document19 pagesStick Diagrams by S.N.bhat, Lecturer, Dept of EC Engg., M.I.T ...arthy_mariappan3873No ratings yet
- True Bypass With Latching Relay: Smudgerd 14 CommentsDocument8 pagesTrue Bypass With Latching Relay: Smudgerd 14 Commentsnanodocl5099No ratings yet
- DELL™ Professional P2210: 22-Inch Widescreen Flat Panel MonitorDocument2 pagesDELL™ Professional P2210: 22-Inch Widescreen Flat Panel MonitorDortmunderNo ratings yet
- Computer Arcitecture: Lecture Data Path by Engr. Saleem Afzal Dhillu Class: BS-CS The University of GujratDocument36 pagesComputer Arcitecture: Lecture Data Path by Engr. Saleem Afzal Dhillu Class: BS-CS The University of GujratRabia ChaudharyNo ratings yet
- Criteria For Choosing Line Codes in Data Communication (#116892) - 99145Document15 pagesCriteria For Choosing Line Codes in Data Communication (#116892) - 99145Lendry NormanNo ratings yet
- NURIT 8320 User Guide PDFDocument154 pagesNURIT 8320 User Guide PDFFelix CarvalhoNo ratings yet
- CQ-ES7880AZ: Am/Fm/Mpx Electronic Tuning RADIO With 6-Disc CD ChangerDocument28 pagesCQ-ES7880AZ: Am/Fm/Mpx Electronic Tuning RADIO With 6-Disc CD Changerdiablohuno100% (1)
- Berglund2718-3 InddDocument1 pageBerglund2718-3 InddsesostrisserbiusNo ratings yet
- Lista de Case Diciembre 2023Document4 pagesLista de Case Diciembre 2023cristofhersandovalrNo ratings yet
- Fortigate 100F Series: Next Generation Firewall Secure Sd-Wan Secure Web GatewayDocument6 pagesFortigate 100F Series: Next Generation Firewall Secure Sd-Wan Secure Web GatewayAnonymous W7u3qzaO0PNo ratings yet
- IEC 60870-5-103 Is An International Standard, Released by IEC (Document3 pagesIEC 60870-5-103 Is An International Standard, Released by IEC (VINOTH DURAISAMYNo ratings yet
- VE Direct Drawing With Phoenix Charger 12-50-1 Inverter 375W Li Batt SmallBMS MPPT 100 30 Orion TR SmartDocument1 pageVE Direct Drawing With Phoenix Charger 12-50-1 Inverter 375W Li Batt SmallBMS MPPT 100 30 Orion TR SmartHamed OuattaraNo ratings yet
- HP 205Document3 pagesHP 205Laboratorio de Informática ForenseNo ratings yet
- Set Problem 1Document9 pagesSet Problem 1Marvin GagarinNo ratings yet
- DCN-NG Download and License ToolDocument45 pagesDCN-NG Download and License ToolCha Lee HengNo ratings yet
- A 180 NM Low Power CMOS Operational Amplifier: Ketan J. Raut R. Kshirsagar A. BhagaliDocument4 pagesA 180 NM Low Power CMOS Operational Amplifier: Ketan J. Raut R. Kshirsagar A. BhagaliAnika TahsinNo ratings yet
- Protocol Converter For PROFIBUS-DP Slave: PKV 30-DpsDocument17 pagesProtocol Converter For PROFIBUS-DP Slave: PKV 30-DpsMoumene Djafer BeyNo ratings yet
- 002 Quotation RavichandraDocument2 pages002 Quotation RavichandraBABA SIDNo ratings yet
- STM 32 F 411 ReDocument151 pagesSTM 32 F 411 ReVictor LugoNo ratings yet
- Usbit 32Document4 pagesUsbit 32Julio SantanaNo ratings yet
- TV Tuner, UHF Mixer Applications VHF UHF Band RF Amplifier ApplicationsDocument5 pagesTV Tuner, UHF Mixer Applications VHF UHF Band RF Amplifier Applicationsyuni supriatinNo ratings yet
- Introduction To Micromaster MM420: Simatic S7Document22 pagesIntroduction To Micromaster MM420: Simatic S7Gnana DeepNo ratings yet