You might also like
- Psychology - Masters in Psychology Entrance Examination Book (Power Within Psychology, Amit Panwar) (Z-Library)Document414 pagesPsychology - Masters in Psychology Entrance Examination Book (Power Within Psychology, Amit Panwar) (Z-Library)Suraj100% (12)
- Pandas Cheatsheets 1.0.6 Web Binder PDFDocument8 pagesPandas Cheatsheets 1.0.6 Web Binder PDFginesNo ratings yet
- Grade 6 - HEALTH - Q4 Module 1 - W1Document12 pagesGrade 6 - HEALTH - Q4 Module 1 - W1Love Lei67% (3)
- 430D Backhoe LoaderDocument8 pages430D Backhoe LoaderRaul GuaninNo ratings yet
- Lexical Analyzer Synopsis FinalDocument20 pagesLexical Analyzer Synopsis FinalSourabh Nigam0% (1)
- Vat Reg. CertificateDocument1 pageVat Reg. CertificateMaaz AzadNo ratings yet
- Useful Programs in C With Aim and Algorithm and CodeDocument49 pagesUseful Programs in C With Aim and Algorithm and CodeShankar76% (21)
- Harappa - Curse of The Blood River - Vineet BajpaiDocument237 pagesHarappa - Curse of The Blood River - Vineet BajpaiArvind Yadav25% (4)
- Test Method of Flammability of Interior Materials For AutomobilesDocument17 pagesTest Method of Flammability of Interior Materials For AutomobilesKarthic BhrabuNo ratings yet
- Notes - IAE-1-CDDocument14 pagesNotes - IAE-1-CDNandhini ShanmugamNo ratings yet
- Chapter-03: What Is Lexical Analysis?Document6 pagesChapter-03: What Is Lexical Analysis?abu syedNo ratings yet
- Lexical Analysis ExamplesDocument11 pagesLexical Analysis Examplesakanksha naiduNo ratings yet
- Unit 2 Lexical AnalyzerDocument30 pagesUnit 2 Lexical AnalyzerBinay AdhikariNo ratings yet
- Cat 1Document150 pagesCat 1Meet mNo ratings yet
- UNIT 2 Compiler DesignDocument23 pagesUNIT 2 Compiler DesignShoaib SiddNo ratings yet
- Lecture 2.1 - Lexical AnalysisDocument24 pagesLecture 2.1 - Lexical AnalysisDivyanshu JainNo ratings yet
- Lecture 04 05 PDFDocument8 pagesLecture 04 05 PDFFaisal ShehzadNo ratings yet
- Chapter 2 - Lexical AnalysisDocument74 pagesChapter 2 - Lexical Analysissamlegend2217No ratings yet
- Lexical Analysis in Compiler Design With ExampleDocument8 pagesLexical Analysis in Compiler Design With ExampleAansa MalikNo ratings yet
- CC2Document6 pagesCC2Sushant ThiteNo ratings yet
- Introduction To Compiler Design-Unit IDocument30 pagesIntroduction To Compiler Design-Unit IKDCreativesNo ratings yet
- ATCD Mod 3Document46 pagesATCD Mod 3Prsgnyaban MishraNo ratings yet
- Compiler Design Mod 1Document75 pagesCompiler Design Mod 1Malu VavuNo ratings yet
- 1.1-Basics of Python PogDocument33 pages1.1-Basics of Python Pogmonish pmNo ratings yet
- Compiler Lecture 2Document16 pagesCompiler Lecture 2bokhtiarbooksNo ratings yet
- Compiler DesignDocument117 pagesCompiler DesignⲤʟᴏᴡɴᴛᴇʀ ᏀᴇɪꜱᴛNo ratings yet
- Class 11 CS Ch-7 Python FindamentalsDocument5 pagesClass 11 CS Ch-7 Python Findamentalsyajur9461No ratings yet
- 002chapter 2 - Lexical AnalysisDocument114 pages002chapter 2 - Lexical AnalysisdawodNo ratings yet
- Eex 6335 Tma 1Document12 pagesEex 6335 Tma 1vishwaNo ratings yet
- Compiler Lecture 2Document16 pagesCompiler Lecture 2ShahRiaz PolokNo ratings yet
- Lexical AnalyzerDocument5 pagesLexical Analyzerhaile barantoNo ratings yet
- CD MANUAL EditedDocument26 pagesCD MANUAL EditedRohitNo ratings yet
- System Implementation: A.The Front End LayerDocument2 pagesSystem Implementation: A.The Front End LayerAqsa TabassumNo ratings yet
- C Language Complete GuideDocument150 pagesC Language Complete GuideHunter HarshaNo ratings yet
- Compiler Design LabDocument40 pagesCompiler Design LabMohit KumarNo ratings yet
- Lexical and Syntax Analysis in Compiler Design by Vishal TrivediDocument5 pagesLexical and Syntax Analysis in Compiler Design by Vishal TrivediItiel LópezNo ratings yet
- Midterm Review NotesDocument3 pagesMidterm Review Notes2012isdabossNo ratings yet
- Program Compilation Lec 7Document18 pagesProgram Compilation Lec 7delight photostateNo ratings yet
- Lecture 3Document4 pagesLecture 3uzmaNo ratings yet
- Computer Project Work: Getting Started With C++ Guided By:-Prepared ByDocument35 pagesComputer Project Work: Getting Started With C++ Guided By:-Prepared ByNishant MittalNo ratings yet
- Phases of CompilerDocument9 pagesPhases of Compilerankita3031No ratings yet
- Phases of CompilerDocument17 pagesPhases of Compilersibananda beheraNo ratings yet
- Lecture 2 Introduction To Phases of CompilerDocument4 pagesLecture 2 Introduction To Phases of CompileruzmaNo ratings yet
- R.V. College of EngineeringDocument56 pagesR.V. College of EngineeringDanny RajNo ratings yet
- Aqsa Shamsa Hira SCD ProjectDocument11 pagesAqsa Shamsa Hira SCD ProjectAqsa TabassumNo ratings yet
- Chapter 2Document6 pagesChapter 2Antehun asefaNo ratings yet
- Chapter 2 - Lexical AnalyserDocument40 pagesChapter 2 - Lexical Analyserbekalu alemayehuNo ratings yet
- Unit 2-LEXICAL ANALYSISDocument46 pagesUnit 2-LEXICAL ANALYSISBuvana MurugaNo ratings yet
- Compiler Notes 1Document20 pagesCompiler Notes 1zakeermasNo ratings yet
- Ty Comps A 42 SPCC IaDocument3 pagesTy Comps A 42 SPCC IaDhruvNo ratings yet
- Automata Theory and Compiler DesignDocument55 pagesAutomata Theory and Compiler Designhiremathsuvarna6No ratings yet
- Introduction To Compilers: Analysis of Source Program, Phases of A Compiler, Grouping ofDocument12 pagesIntroduction To Compilers: Analysis of Source Program, Phases of A Compiler, Grouping ofKaran BajwaNo ratings yet
- Computer Project Work: Getting Started With C++ Guided By:-Prepared ByDocument35 pagesComputer Project Work: Getting Started With C++ Guided By:-Prepared ByRai HrithikNo ratings yet
- Comp 1127 AssignmentDocument5 pagesComp 1127 AssignmentÔbéèÿ RøbbÏęNo ratings yet
- Compiler Design and Construction NoteDocument97 pagesCompiler Design and Construction NoteSam MasNo ratings yet
- 2-Lexical AnalysisDocument52 pages2-Lexical AnalysisHASNAIN JANNo ratings yet
- CD - Ch.1Document28 pagesCD - Ch.1Harsha GangwaniNo ratings yet
- Compiler Overview & PhasesDocument26 pagesCompiler Overview & PhasesAadilNo ratings yet
- CD 1Document23 pagesCD 1PonnuNo ratings yet
- CPSC 388 - Compiler Design and Construction: Lecture: MWF 11:00am-12:20pm, Room 106 ColtonDocument27 pagesCPSC 388 - Compiler Design and Construction: Lecture: MWF 11:00am-12:20pm, Room 106 Coltonr_s_velNo ratings yet
- Compiler HandoutDocument48 pagesCompiler HandoutZiyad MohammedNo ratings yet
- Compiler Overview & PhasesDocument26 pagesCompiler Overview & PhasesAadilNo ratings yet
- CD AssignmentDocument16 pagesCD Assignmentadithyavinod.mecNo ratings yet
- Experiment No. 1 AIM:-To Study Phases of CompilerDocument10 pagesExperiment No. 1 AIM:-To Study Phases of CompilerLionNo ratings yet
- Chapter 1Document28 pagesChapter 1HelloNo ratings yet
- Chapter 2 - Lexical AnalyserDocument38 pagesChapter 2 - Lexical AnalyserYitbarek MurcheNo ratings yet
- Compilers Thamar Universtiy Lec1 PDFDocument21 pagesCompilers Thamar Universtiy Lec1 PDFhashem AL-shrfiNo ratings yet
- ShikhandiDocument103 pagesShikhandiMoupriya RoyNo ratings yet
- DBMS LAB Assignment-5: Q (5) : Create Following TablesDocument2 pagesDBMS LAB Assignment-5: Q (5) : Create Following TablesMoupriya RoyNo ratings yet
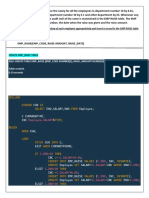
- Write A PL/SQL Block To Update The Salary of Each Employee Appropriately and Insert A Record in The EMP RAISE Table As Well Tables Are As FollowsDocument2 pagesWrite A PL/SQL Block To Update The Salary of Each Employee Appropriately and Insert A Record in The EMP RAISE Table As Well Tables Are As FollowsMoupriya RoyNo ratings yet
- 03 02Document266 pages03 02Moupriya RoyNo ratings yet
- Booktree - NG LockdownDocument364 pagesBooktree - NG LockdownMoupriya RoyNo ratings yet
- Systolic Systems - SBDocument4 pagesSystolic Systems - SBMoupriya RoyNo ratings yet
- Assignment 1Document5 pagesAssignment 1Moupriya RoyNo ratings yet
- L2 - Phases of CompilerDocument12 pagesL2 - Phases of CompilerMoupriya RoyNo ratings yet
- Lec-60 Applied Grammar PDFDocument20 pagesLec-60 Applied Grammar PDFMoupriya RoyNo ratings yet
- Lec-58 Facing Job Interviews Part II PDFDocument20 pagesLec-58 Facing Job Interviews Part II PDFMoupriya RoyNo ratings yet
- Curvature of A CurveDocument3 pagesCurvature of A Curvekumar_yogesh223881No ratings yet
- A Textbook of Engineering Mathematics (Volume I)Document30 pagesA Textbook of Engineering Mathematics (Volume I)Moupriya RoyNo ratings yet
- Assignment Math 2 PDFDocument1 pageAssignment Math 2 PDFMoupriya RoyNo ratings yet
- (Applicable From The Academic Session 2018-2019) : Syllabus For B. Tech in Computer Science & EngineeringDocument17 pages(Applicable From The Academic Session 2018-2019) : Syllabus For B. Tech in Computer Science & EngineeringSoumyaratna DebnathNo ratings yet
- 8th Sem Marksheet PDFDocument1 page8th Sem Marksheet PDFMoupriya RoyNo ratings yet
- Seven Elements of Effective NegotiationsDocument3 pagesSeven Elements of Effective NegotiationsKilik GantitNo ratings yet
- Publication PDFDocument20 pagesPublication PDFBhaumik VaidyaNo ratings yet
- MGT-01 (14.03.23) - QPDocument19 pagesMGT-01 (14.03.23) - QPSrinivas VakaNo ratings yet
- Breeding Corydoras MelanotaeniaDocument3 pagesBreeding Corydoras MelanotaeniayudispriyambodoNo ratings yet
- VISTA LAND AND LIFESCAPES INC FinalDocument9 pagesVISTA LAND AND LIFESCAPES INC Finalmarie crisNo ratings yet
- NSDADocument1 pageNSDAShallu ManchandaNo ratings yet
- Inkubator TransportDocument8 pagesInkubator TransportYassarNo ratings yet
- Okuma CL302L Parts List & ManualDocument3 pagesOkuma CL302L Parts List & Manualcoolestkiwi100% (1)
- 6.5 Tectonics and EvidencesDocument28 pages6.5 Tectonics and Evidencesbook wormNo ratings yet
- CH 7b - Shift InstructionsDocument20 pagesCH 7b - Shift Instructionsapi-237335979100% (1)
- CN Mod1 Ppt-FinalDocument56 pagesCN Mod1 Ppt-FinalkkNo ratings yet
- Gas Pressure Reduction StationDocument2 pagesGas Pressure Reduction StationMathias OnosemuodeNo ratings yet
- 08 LCD Slide Handout 1Document5 pages08 LCD Slide Handout 1Jana Gabrielle Canonigo0% (1)
- Sigma JsDocument42 pagesSigma JslakshmiescribdNo ratings yet
- Theory Best Suited For: Learning Theory Comparison ChartDocument1 pageTheory Best Suited For: Learning Theory Comparison ChartDAVE HOWARDNo ratings yet
- File Handling in Python PDFDocument25 pagesFile Handling in Python PDFNileshNo ratings yet
- Diversity of Tree Vegetation of Rajasthan, India: Tropical Ecology September 2014Document9 pagesDiversity of Tree Vegetation of Rajasthan, India: Tropical Ecology September 2014Abdul WajidNo ratings yet
- Cavinkare Private LimitedDocument4 pagesCavinkare Private LimitedRohit TrivediNo ratings yet
- Study of Causal Factors of Road Accidents On Panipat-Samalkha Section of Nh-1Document7 pagesStudy of Causal Factors of Road Accidents On Panipat-Samalkha Section of Nh-1esatjournalsNo ratings yet
- Kraft Foods Inc. in FranceDocument25 pagesKraft Foods Inc. in Francevishal211086No ratings yet
- Pressure Transducer Davs 311-1-0 Volt - XCMG PartsDocument1 pagePressure Transducer Davs 311-1-0 Volt - XCMG Partsej ejazNo ratings yet
- Cuadernillo de Ingles Grado 4 PrimariaDocument37 pagesCuadernillo de Ingles Grado 4 PrimariaMariaNo ratings yet
- Past:: Simple Indefinite Continuous Perfect Perfect ContinuousDocument12 pagesPast:: Simple Indefinite Continuous Perfect Perfect ContinuousAhmed Abd El HafeezNo ratings yet
- Certificate of Software AcceptanceDocument6 pagesCertificate of Software AcceptanceVince PepañaNo ratings yet
- AP Physics 1 Practice Test 2 Answer ExplanationsDocument14 pagesAP Physics 1 Practice Test 2 Answer Explanations장준오No ratings yet