You might also like
- Addressing Malnutrition in School-Aged Children With A Diet Recommender SystemDocument15 pagesAddressing Malnutrition in School-Aged Children With A Diet Recommender SystemInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Food Security, Poverty and Nutrition Policy Analysis: Statistical Methods and ApplicationsFrom EverandFood Security, Poverty and Nutrition Policy Analysis: Statistical Methods and ApplicationsRating: 4 out of 5 stars4/5 (1)
- Nutritional Status of Children in India and SDGSDocument7 pagesNutritional Status of Children in India and SDGSInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- 20 MedianiDocument13 pages20 MedianiSalsabila Munirah AmirNo ratings yet
- S EM 17 1 2 019 23 661 Maulina R TXDocument9 pagesS EM 17 1 2 019 23 661 Maulina R TXFahmi HidayatNo ratings yet
- Assessment of Anthropometric Failure Amongst Under Five Children in An Urbanized Village of Delhi: A Cross Sectional StudyDocument7 pagesAssessment of Anthropometric Failure Amongst Under Five Children in An Urbanized Village of Delhi: A Cross Sectional StudyIJAR JOURNALNo ratings yet
- Analysis of Factors Affecting The Prevalence of Stunting On Children Under Five Years 8429Document11 pagesAnalysis of Factors Affecting The Prevalence of Stunting On Children Under Five Years 8429Demsa SimbolonNo ratings yet
- Prevalence and Risk Factors of Congenital Disabilities in China, India, and Indonesia: A Systematic ReviewDocument10 pagesPrevalence and Risk Factors of Congenital Disabilities in China, India, and Indonesia: A Systematic ReviewGama MuchichiNo ratings yet
- Social Determinants of Health and Knowledge About Hiv/Aids Transmission Among AdolescentsFrom EverandSocial Determinants of Health and Knowledge About Hiv/Aids Transmission Among AdolescentsNo ratings yet
- Jurnal Indonesia 1Document11 pagesJurnal Indonesia 1Juli ArnithaNo ratings yet
- 10 20+Final+Paper+Russian+Law-Willya+2023Document7 pages10 20+Final+Paper+Russian+Law-Willya+2023Louie Joice MartinezNo ratings yet
- A Synopsis of Proposed Plan of Research Work of DissertationDocument4 pagesA Synopsis of Proposed Plan of Research Work of DissertationVishwani GoswamiNo ratings yet
- Estimating The Socio-Economic Factors of Food Insecurity in Pakistan: A Regional Level AnalysisDocument15 pagesEstimating The Socio-Economic Factors of Food Insecurity in Pakistan: A Regional Level AnalysisMaryam JavedNo ratings yet
- Using The Data Information Knowledge Wisdom ContinuumDocument6 pagesUsing The Data Information Knowledge Wisdom ContinuumLori A. Dixon67% (6)
- ?o file:///storage/emulated/0/Download/INDJCSE16 07 01 040Document6 pages?o file:///storage/emulated/0/Download/INDJCSE16 07 01 040Golisa RobaNo ratings yet
- Jurnal Perkembangan BalitaDocument10 pagesJurnal Perkembangan BalitaQatrunnada N KhusmithaNo ratings yet
- Pengaruh Sosial Ekonomi Dan Keanekaragaman Makanan Lokal Terhadap Stunting Pada BalitaDocument14 pagesPengaruh Sosial Ekonomi Dan Keanekaragaman Makanan Lokal Terhadap Stunting Pada BalitaRatna PermatarafaNo ratings yet
- Assessment of Growth and Global Developmental Delay: A Study Among Young Children in A Rural Community of IndiaDocument4 pagesAssessment of Growth and Global Developmental Delay: A Study Among Young Children in A Rural Community of IndiahardianNo ratings yet
- Research Paper On Healthcare in IndiaDocument8 pagesResearch Paper On Healthcare in Indiaorlfgcvkg100% (1)
- Implementasi Machine Learning Dengan Model Case Based Reasoning Dalam Mendagnosa Gizi Buruk Pada AnakDocument7 pagesImplementasi Machine Learning Dengan Model Case Based Reasoning Dalam Mendagnosa Gizi Buruk Pada AnakMuhammad SyahputraNo ratings yet
- Incorporating Bioethics Education into School CurriculumsFrom EverandIncorporating Bioethics Education into School CurriculumsNo ratings yet
- Can Children's Health Be Improved by Raising Healthcare Spending and Medical Specialization A Prospective StudyDocument5 pagesCan Children's Health Be Improved by Raising Healthcare Spending and Medical Specialization A Prospective StudyInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- 93-Article Text-440-2-10-20210531Document13 pages93-Article Text-440-2-10-20210531Ogih SugianaNo ratings yet
- Child Malnutrition in Bangladesh: An Evidence From Multiple Indicators Cluster SurveyDocument8 pagesChild Malnutrition in Bangladesh: An Evidence From Multiple Indicators Cluster Surveyijsab.comNo ratings yet
- A Review of Child Stunting Determinants in IndonesiaDocument10 pagesA Review of Child Stunting Determinants in IndonesiaPutri SaripaneNo ratings yet
- IEM Data - APDocument2 pagesIEM Data - APavijitcu2007No ratings yet
- 451 1378 1 PBDocument11 pages451 1378 1 PBprawira heroNo ratings yet
- 04 - Concept Paper ExampleDocument5 pages04 - Concept Paper ExampleGusti RamadhanNo ratings yet
- Effectiveness of The Father Alert Android Application On Father's Knowledge and Support in Stunting Prevention in 2023Document6 pagesEffectiveness of The Father Alert Android Application On Father's Knowledge and Support in Stunting Prevention in 2023International Journal of Innovative Science and Research TechnologyNo ratings yet
- 2.jurnal Kepkel4Document7 pages2.jurnal Kepkel4Himatul AliyahNo ratings yet
- Comparison-of-Indonesian-Growth-Reference-Chart-and-World-Health-Organization-Child-Growth-Standard-in-Detecting-Stunting-A-Systematic-Review-and-Metaanalysis-of-15874-ChildrenJCRPE-Journal-of-Clinical-Research-in-Document6 pagesComparison-of-Indonesian-Growth-Reference-Chart-and-World-Health-Organization-Child-Growth-Standard-in-Detecting-Stunting-A-Systematic-Review-and-Metaanalysis-of-15874-ChildrenJCRPE-Journal-of-Clinical-Research-in-tariNo ratings yet
- Knowledge Attitude and Practice Towards MalnutritierDocument6 pagesKnowledge Attitude and Practice Towards MalnutritierEmiru MerdassaNo ratings yet
- Running Head: HEALTH ECONOMICS 1Document4 pagesRunning Head: HEALTH ECONOMICS 1Imani ImaniNo ratings yet
- JR - Anak - Impact of Stunting On Early Childhood Cognitive Development in Benin Evidence From Demographic and Health SurvDocument11 pagesJR - Anak - Impact of Stunting On Early Childhood Cognitive Development in Benin Evidence From Demographic and Health SurvKELOMPOK DUANo ratings yet
- Modelling Number of Stunting Binominal RegressionDocument16 pagesModelling Number of Stunting Binominal RegressionFikran Ahmad Ahmad Al-HadiNo ratings yet
- Determinan Faktor JurnalDocument7 pagesDeterminan Faktor Jurnalhilan sasewaNo ratings yet
- Malnutrition Among Under Five Children in UttarakhandDocument5 pagesMalnutrition Among Under Five Children in UttarakhandEditor IJTSRDNo ratings yet
- 6 PonumDocument9 pages6 PonumSalsabila Munirah AmirNo ratings yet
- E Health LiteracyDocument7 pagesE Health LiteracyNathalia TolentinoNo ratings yet
- Chapter One 1.1 Background To The StudyDocument33 pagesChapter One 1.1 Background To The StudyTajudeen AdegbenroNo ratings yet
- Gender Disparity in Nutritional Status Among Under Five Children in Rajshahi City, BangladeshDocument10 pagesGender Disparity in Nutritional Status Among Under Five Children in Rajshahi City, BangladeshMilu CyriacNo ratings yet
- Aluko AdeniyietcDocument14 pagesAluko Adeniyietczahfira edwardNo ratings yet
- The Dominant Factors of Stunting Incidence in Toddlers (0 - 59 Months) in East Lombok Regency A Riskesdas Data Analysis 2018Document11 pagesThe Dominant Factors of Stunting Incidence in Toddlers (0 - 59 Months) in East Lombok Regency A Riskesdas Data Analysis 2018International Journal of Innovative Science and Research Technology100% (1)
- Association of Perinatal FactorsDocument11 pagesAssociation of Perinatal FactorsMuseNo ratings yet
- 7.ConsequencesofUnintendedPregnancy Singhetal.Document9 pages7.ConsequencesofUnintendedPregnancy Singhetal.mia widiastutiNo ratings yet
- 41-Article Text-159-1-10-20230316Document9 pages41-Article Text-159-1-10-20230316Ara ciNo ratings yet
- ASI Dan Stunting - Izza 2019Document6 pagesASI Dan Stunting - Izza 2019Emmy KwonNo ratings yet
- SCIENTISTS Dea (45-52)Document8 pagesSCIENTISTS Dea (45-52)susi triyuanaNo ratings yet
- Jurnal Internasional 2Document4 pagesJurnal Internasional 2Ria SaputriNo ratings yet
- Composite Index of Anthropometric Failure ReportDocument12 pagesComposite Index of Anthropometric Failure Reportmanali.9054No ratings yet
- Jurnal KasmaDocument13 pagesJurnal KasmaAhmad ZahirNo ratings yet
- Preventive Medicine ReportsDocument6 pagesPreventive Medicine ReportsDedi IrawandiNo ratings yet
- Estimates of Malnutrition and Risk of Malnutrition Among The Elderly in IndiaDocument12 pagesEstimates of Malnutrition and Risk of Malnutrition Among The Elderly in IndiaAtulNo ratings yet
- Inequity in India: The Case of Maternal and Reproductive HealthDocument31 pagesInequity in India: The Case of Maternal and Reproductive HealthPankaj PatilNo ratings yet
- Maternal Health Care in India Access and Demand DeterminantsDocument21 pagesMaternal Health Care in India Access and Demand Determinantspat.medicinanatural Panapane NaturologiaNo ratings yet
- Ijcp 5729oDocument6 pagesIjcp 5729opuneetsbarcNo ratings yet
- 4717 21831 1 PBDocument10 pages4717 21831 1 PBizaamutiaaNo ratings yet
- International Journal of Information Management: A A B C D A A e ADocument11 pagesInternational Journal of Information Management: A A B C D A A e AAhmed KNo ratings yet
- Aguayo Et Al-2016-Maternal & Child NutritionDocument20 pagesAguayo Et Al-2016-Maternal & Child NutritionKomala SariNo ratings yet
- MITS Alliance INCLEN Research Proposal HMSCDocument20 pagesMITS Alliance INCLEN Research Proposal HMSCgunjan.guptaNo ratings yet
- Risks: Applications of Clustering With Mixed Type Data in Life InsuranceDocument19 pagesRisks: Applications of Clustering With Mixed Type Data in Life InsuranceShaifuru AnamuNo ratings yet
- (BUKU PANDUAN) Riset-Inovasi Diaspora IndonesiaDocument26 pages(BUKU PANDUAN) Riset-Inovasi Diaspora IndonesiaShaifuru AnamuNo ratings yet
- Research Article Analysis of DNA Sequence Classification Using CNN and Hybrid ModelsDocument12 pagesResearch Article Analysis of DNA Sequence Classification Using CNN and Hybrid ModelsShaifuru AnamuNo ratings yet
- Segmenting Bank Customers Via RFM Model and Unsupervised Machine LearningDocument6 pagesSegmenting Bank Customers Via RFM Model and Unsupervised Machine LearningShaifuru AnamuNo ratings yet
- 01 IntroDocument54 pages01 IntroShaifuru AnamuNo ratings yet
- Fuzzy Clustering ToolboxDocument77 pagesFuzzy Clustering ToolboxraphthewizardNo ratings yet
- Fuzzy Clustering ToolboxDocument77 pagesFuzzy Clustering ToolboxraphthewizardNo ratings yet
- 1709 02840 PDFDocument237 pages1709 02840 PDFShaifuru AnamuNo ratings yet
- Fuzzy Clustering ToolboxDocument77 pagesFuzzy Clustering ToolboxraphthewizardNo ratings yet
- Template Abstract SnmsaDocument70 pagesTemplate Abstract SnmsaShaifuru AnamuNo ratings yet
- INTRODUCTION To Machine LearningDocument188 pagesINTRODUCTION To Machine LearningGeorgios GropetisNo ratings yet
- P286 PDFDocument9 pagesP286 PDFShaifuru AnamuNo ratings yet
- Jadwal Genap 2018-2019Document31 pagesJadwal Genap 2018-2019Shaifuru AnamuNo ratings yet
- Weickert ReviewDocument27 pagesWeickert ReviewShaifuru AnamuNo ratings yet
- KDI Prentasic Pavle PDFDocument8 pagesKDI Prentasic Pavle PDFShaifuru AnamuNo ratings yet
- Book GADocument2 pagesBook GAShaifuru AnamuNo ratings yet
- 2011-2012 Doctoral Application Procedure Engineering & Science Yamaguchi UniversityDocument40 pages2011-2012 Doctoral Application Procedure Engineering & Science Yamaguchi UniversityShaifuru AnamuNo ratings yet
- Book GADocument2 pagesBook GAShaifuru AnamuNo ratings yet
- KDI Prentasic Pavle PDFDocument8 pagesKDI Prentasic Pavle PDFShaifuru AnamuNo ratings yet
- Global Schedule PDFDocument40 pagesGlobal Schedule PDFShaifuru AnamuNo ratings yet
- Window SlideDocument1 pageWindow SlideShaifuru AnamuNo ratings yet
- De Thi Chon HSGDocument10 pagesDe Thi Chon HSGKiều TrangNo ratings yet
- Open Courses Myanmar Strategic English Week 4: U Yan Naing Se NyuntDocument24 pagesOpen Courses Myanmar Strategic English Week 4: U Yan Naing Se NyuntYan Naing Soe NyuntNo ratings yet
- SPKT Thiet Ke Co Khi 1Document33 pagesSPKT Thiet Ke Co Khi 1Chiến PhanNo ratings yet
- Case Study of Flixborough UK DisasterDocument52 pagesCase Study of Flixborough UK Disasteraman shaikhNo ratings yet
- Protection Solutions: Above-the-NeckDocument42 pagesProtection Solutions: Above-the-NeckMatt DeganNo ratings yet
- Fitness Program: Save On Health Club Memberships, Exercise Equipment and More!Document1 pageFitness Program: Save On Health Club Memberships, Exercise Equipment and More!KALAI TIFYNo ratings yet
- Respiratory Examination - Protected 1Document4 pagesRespiratory Examination - Protected 1anirudh811100% (1)
- Emergency War Surgery Nato HandbookDocument384 pagesEmergency War Surgery Nato Handbookboubiyou100% (1)
- Differential Partitioning of Betacyanins and Betaxanthins Employing Aqueous Two Phase ExtractionDocument8 pagesDifferential Partitioning of Betacyanins and Betaxanthins Employing Aqueous Two Phase ExtractionPaul Jefferson Flores HurtadoNo ratings yet
- VedasUktimAlA Sanskrit Hindi EnglishDocument47 pagesVedasUktimAlA Sanskrit Hindi EnglishAnantha Krishna K SNo ratings yet
- CNA Candidate HandbookDocument57 pagesCNA Candidate HandbookSummerNo ratings yet
- Babok Framework Overview: BA Planning & MonitoringDocument1 pageBabok Framework Overview: BA Planning & MonitoringJuan100% (1)
- A-V300!1!6-L-GP General Purpose Potable Water Commercial Industrial Hi-Flo Series JuDocument2 pagesA-V300!1!6-L-GP General Purpose Potable Water Commercial Industrial Hi-Flo Series JuwillgendemannNo ratings yet
- NFPA 25 2011 Sprinkler Inspection TableDocument2 pagesNFPA 25 2011 Sprinkler Inspection TableHermes VacaNo ratings yet
- BATES CH 6 The Thorax and LungsDocument2 pagesBATES CH 6 The Thorax and LungsAngelica Mae Dela CruzNo ratings yet
- Final PR 2 CheckedDocument23 pagesFinal PR 2 CheckedCindy PalenNo ratings yet
- Ivon Neil Adams Form IV RedactedDocument3 pagesIvon Neil Adams Form IV Redactedkc wildmoonNo ratings yet
- Date SissyDocument5 pagesDate SissyFletcher Irvine50% (2)
- 168 Visual Perceptual SkillsDocument3 pages168 Visual Perceptual Skillskonna4539No ratings yet
- The Mystique of The Dominant WomanDocument8 pagesThe Mystique of The Dominant WomanDorothy HaydenNo ratings yet
- Gut Health Elimination Diet Meal Plan FINALDocument9 pagesGut Health Elimination Diet Meal Plan FINALKimmy BathamNo ratings yet
- Msds SilverDocument5 pagesMsds SilverSteppenwolf2012No ratings yet
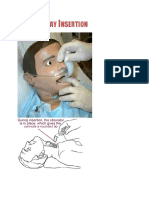
- Oral Airway InsertionDocument3 pagesOral Airway InsertionSajid HolyNo ratings yet
- 36 Petroland PD Serie DKDocument7 pages36 Petroland PD Serie DKBayu RahmansyahNo ratings yet
- WP DeltaV Software Update Deployment PDFDocument8 pagesWP DeltaV Software Update Deployment PDFevbaruNo ratings yet
- Health Module 6 g7Document26 pagesHealth Module 6 g7Richelle PamintuanNo ratings yet
- Crude TBP Country United Arab Emirates Distillation: MurbanDocument2 pagesCrude TBP Country United Arab Emirates Distillation: MurbanHaris ShahidNo ratings yet
- Thesis Report KapilDocument66 pagesThesis Report Kapilkapilsharma2686100% (1)
- Secrets of Sexual ExstasyDocument63 pagesSecrets of Sexual Exstasy19LucianNo ratings yet
- Bleeding in A NeonateDocument36 pagesBleeding in A NeonateDrBibek AgarwalNo ratings yet