You might also like
- Design of Machine Learning Framework ForDocument7 pagesDesign of Machine Learning Framework ForJehan Marie GiananNo ratings yet
- The Strategy Machine (Review and Analysis of Downes' Book)From EverandThe Strategy Machine (Review and Analysis of Downes' Book)No ratings yet
- The Long Tail Theory for Business: Find your niche and future-proof your businessFrom EverandThe Long Tail Theory for Business: Find your niche and future-proof your businessNo ratings yet
- Efficient Sales Performance: Open Learning for Sales ProfessionalsFrom EverandEfficient Sales Performance: Open Learning for Sales ProfessionalsSally VinceNo ratings yet
- SCM AssignmentDocument8 pagesSCM AssignmentDe BuNo ratings yet
- Summary: Creating Value in the Network Economy: Review and Analysis of Tapscott's BookFrom EverandSummary: Creating Value in the Network Economy: Review and Analysis of Tapscott's BookNo ratings yet
- Group Assignment 2 PDFDocument4 pagesGroup Assignment 2 PDFAisha Frost0% (1)
- s11042-021-11837-5Document28 pagess11042-021-11837-5Lizbeth YmanNo ratings yet
- Summary of Clayton M. Christensen, Jerome H. Grossman & Jason Hwang's The Innovator's PrescriptionFrom EverandSummary of Clayton M. Christensen, Jerome H. Grossman & Jason Hwang's The Innovator's PrescriptionNo ratings yet
- Category Management - A Pervasive, New Vertical/ Horizontal FormatDocument5 pagesCategory Management - A Pervasive, New Vertical/ Horizontal FormatbooklandNo ratings yet
- Strategic Capability Response Analysis: The Convergence of Industrié 4.0, Value Chain Network Management 2.0 and Stakeholder Value-Led ManagementFrom EverandStrategic Capability Response Analysis: The Convergence of Industrié 4.0, Value Chain Network Management 2.0 and Stakeholder Value-Led ManagementNo ratings yet
- BSBMKG433 Student Assessment Tasks 04-03-21Document4 pagesBSBMKG433 Student Assessment Tasks 04-03-21S RNo ratings yet
- Mining Association Rule by Multilevel Relationship Algorithm: An Innovative Approach For Cooperative LearningDocument8 pagesMining Association Rule by Multilevel Relationship Algorithm: An Innovative Approach For Cooperative LearningInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Data-Driven Business Strategies: Understanding and Harnessing the Power of Big DataFrom EverandData-Driven Business Strategies: Understanding and Harnessing the Power of Big DataNo ratings yet
- Market Basket Analysis Using Apriori and FP Growth AlgorithmDocument7 pagesMarket Basket Analysis Using Apriori and FP Growth Algorithmcendy oktariNo ratings yet
- Performance Management in Retail and the Consumer Goods Industry: Best Practices and Case StudiesFrom EverandPerformance Management in Retail and the Consumer Goods Industry: Best Practices and Case StudiesMichael ButtkusNo ratings yet
- Predicting Buying Behavior Using CPT+: A Case Study of An E-Commerce CompanyDocument8 pagesPredicting Buying Behavior Using CPT+: A Case Study of An E-Commerce CompanyPhương Hoàng Thị ThanhNo ratings yet
- Customers Rule! (Review and Analysis of Blackwell and Stephan's Book)From EverandCustomers Rule! (Review and Analysis of Blackwell and Stephan's Book)No ratings yet
- Implementation of Association Rules With Apriori Algorithm For Increasing The Quality of PromotionDocument5 pagesImplementation of Association Rules With Apriori Algorithm For Increasing The Quality of PromotionArun MozhiNo ratings yet
- E-commerce Data Mining for Personalization and Pattern DetectionDocument22 pagesE-commerce Data Mining for Personalization and Pattern DetectionmalhanrakeshNo ratings yet
- From Business Intelligence To Competitive Intelligence: Inferring Competitive Measures Using Augmented Site-Centric DataDocument48 pagesFrom Business Intelligence To Competitive Intelligence: Inferring Competitive Measures Using Augmented Site-Centric DataAdina AnghelusNo ratings yet
- Retail Supply Chain Concept & CasesDocument21 pagesRetail Supply Chain Concept & CasesAbdul Hanan NasirNo ratings yet
- Sample Report 1Document4 pagesSample Report 1Roshan atulNo ratings yet
- Benchmarking for Businesses: Measure and improve your company's performanceFrom EverandBenchmarking for Businesses: Measure and improve your company's performanceNo ratings yet
- The Profit Zone (Review and Analysis of Slywotzky and Morrison's Book)From EverandThe Profit Zone (Review and Analysis of Slywotzky and Morrison's Book)No ratings yet
- !. Definition of Category Management: RetailerDocument6 pages!. Definition of Category Management: Retailerchand2sekhNo ratings yet
- Using Information Systems To Achieve Competitive AdvantageDocument7 pagesUsing Information Systems To Achieve Competitive Advantageعمران ساجيلNo ratings yet
- Enterprise Supply Chain Management: Integrating Best in Class ProcessesFrom EverandEnterprise Supply Chain Management: Integrating Best in Class ProcessesNo ratings yet
- MKSC 2018 1084Document16 pagesMKSC 2018 1084Private AccountNo ratings yet
- B14750882S819 PDFDocument5 pagesB14750882S819 PDFShubhamNo ratings yet
- Andiyappillai 2020 Ijais 451896Document5 pagesAndiyappillai 2020 Ijais 451896Christian CardiñoNo ratings yet
- Category ManagementDocument9 pagesCategory ManagementMadhu Mahesh RajNo ratings yet
- Conception for Procurement Excellence: The performance profile and degree of digitalization of procurementFrom EverandConception for Procurement Excellence: The performance profile and degree of digitalization of procurementNo ratings yet
- Retail Supply Chain ManagementDocument9 pagesRetail Supply Chain ManagementShivatiNo ratings yet
- duyetDocument26 pagesduyetLê Thị Hồng TràNo ratings yet
- Chapter 6 Economics of OrganizationDocument9 pagesChapter 6 Economics of OrganizationJecil MondranoNo ratings yet
- Efficient Consumer Response PDFDocument5 pagesEfficient Consumer Response PDFSafijo AlphonsNo ratings yet
- Supply Chain Management The Supply Chain E-Marketplaces Why The Internet? 1 3 5 7Document13 pagesSupply Chain Management The Supply Chain E-Marketplaces Why The Internet? 1 3 5 7spiro40No ratings yet
- Market Basket Analysis Across Multiple Stores and Time PeriodsDocument16 pagesMarket Basket Analysis Across Multiple Stores and Time PeriodsZain AamirNo ratings yet
- Challenges For Automatic Home SupplyDocument5 pagesChallenges For Automatic Home SupplyAngara SaxenaNo ratings yet
- By H. Jefferson Smith: Do Data Warehouses Challenge Fair Play?Document2 pagesBy H. Jefferson Smith: Do Data Warehouses Challenge Fair Play?Jagadeesh Padaki100% (1)
- ch14 Min Assoc RulesDocument12 pagesch14 Min Assoc Rulesrohitmultani153No ratings yet
- Market Basket AnalysisDocument86 pagesMarket Basket AnalysisMonu KoshtiNo ratings yet
- Michael Porter's Value Chain: Unlock your company's competitive advantageFrom EverandMichael Porter's Value Chain: Unlock your company's competitive advantageRating: 4 out of 5 stars4/5 (1)
- FinalAssignmentDocument5 pagesFinalAssignmentAB BANo ratings yet
- Predicting Missing Items in Shopping Carts Using Fast AlgorithmDocument7 pagesPredicting Missing Items in Shopping Carts Using Fast AlgorithmAmal PrasadNo ratings yet
- Qisman 2021 J. Phys. Conf. Ser. 1722 012020Document14 pagesQisman 2021 J. Phys. Conf. Ser. 1722 012020Omotayo Samuel VictorNo ratings yet
- Bricks and clicks business model optimized for SEODocument10 pagesBricks and clicks business model optimized for SEODev TiwariNo ratings yet
- Enticing Online Consumers: An Extended Technology Acceptance PerspectiveDocument15 pagesEnticing Online Consumers: An Extended Technology Acceptance PerspectiveSumit SinghNo ratings yet
- Clustering Retail Products Based On Customer BehaviourDocument11 pagesClustering Retail Products Based On Customer BehaviourMarian MarcuNo ratings yet
- SCM Module 2 NotesDocument7 pagesSCM Module 2 NotesRaveen MJNo ratings yet
- The Vertical Boundaries of The Firm: Chapter ContentsDocument14 pagesThe Vertical Boundaries of The Firm: Chapter ContentsOscar CardenasNo ratings yet
- 20373ijertv13n11 44Document13 pages20373ijertv13n11 44IH RamayNo ratings yet
- C (C CCCC CCDocument7 pagesC (C CCCC CCAditya WaghNo ratings yet
- File 8 Aggregation - Carry Forward - 31jul20Document71 pagesFile 8 Aggregation - Carry Forward - 31jul20AlexCooksNo ratings yet
- File 4 Business Income - 17jul20Document101 pagesFile 4 Business Income - 17jul20AlexCooksNo ratings yet
- DW Dimensional ModelingDocument27 pagesDW Dimensional ModelingAlexCooksNo ratings yet
- Valuation With Market Multiples Avoid Pitfalls in The Use of Relative ValuationDocument15 pagesValuation With Market Multiples Avoid Pitfalls in The Use of Relative ValuationAlexCooks100% (1)
- File 3 Business Income - 16jul20Document91 pagesFile 3 Business Income - 16jul20AlexCooksNo ratings yet
- Cost of Quality Trend AnalysisDocument5 pagesCost of Quality Trend AnalysisAlexCooksNo ratings yet
- RMD - S2 MR ApplicationsDocument28 pagesRMD - S2 MR ApplicationsAyush MathurNo ratings yet
- Dewdrop Soap - BRMDocument1 pageDewdrop Soap - BRMAlexCooksNo ratings yet
- Association Rule Mining - Part IDocument21 pagesAssociation Rule Mining - Part IAlexCooksNo ratings yet
- Ob2 Xyz 2019Document1 pageOb2 Xyz 2019AlexCooksNo ratings yet
- Government Systems and PolicyDocument42 pagesGovernment Systems and PolicyAlexCooksNo ratings yet
- GDP Modeling and Forecasting Using ARIMADocument33 pagesGDP Modeling and Forecasting Using ARIMAAlexCooks0% (1)
- Joule Thomson Expansion J TDocument6 pagesJoule Thomson Expansion J TISLAM I. Fekry100% (2)
- Planned Questions 2020Document98 pagesPlanned Questions 2020Ivan HerreraNo ratings yet
- Order Qty. When Demand Is Approx. Level - Dr. RonDocument42 pagesOrder Qty. When Demand Is Approx. Level - Dr. RonAlexCooksNo ratings yet
- Segmentation, Targeting and Positioning ModelDocument4 pagesSegmentation, Targeting and Positioning ModelAlexCooksNo ratings yet
- BRM (For Class)Document18 pagesBRM (For Class)AlexCooksNo ratings yet
- Effects of Light On Molecular Orientation of Liquid Crystals - F Simoni, O FrancescangeliDocument50 pagesEffects of Light On Molecular Orientation of Liquid Crystals - F Simoni, O FrancescangeliAlexCooksNo ratings yet
- Material Equilibrium LectureDocument14 pagesMaterial Equilibrium LectureAlexCooksNo ratings yet
- TOPOLOGICAL DEFECTS IN NEMATIC AND SMECTIC LIQUID CRYSTALS - Bryan Gin-Ge ChenDocument132 pagesTOPOLOGICAL DEFECTS IN NEMATIC AND SMECTIC LIQUID CRYSTALS - Bryan Gin-Ge ChenAlexCooksNo ratings yet
- Sales, Marketing & Advertising Management StrategiesDocument31 pagesSales, Marketing & Advertising Management StrategiesAlexCooksNo ratings yet
- Defects in Liquid Crystals - Maurice KlemanDocument101 pagesDefects in Liquid Crystals - Maurice KlemanAlexCooksNo ratings yet
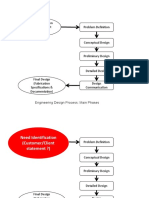
- Need Identification (Customer/Client Statement ?) Problem DefinitionDocument15 pagesNeed Identification (Customer/Client Statement ?) Problem DefinitionAlexCooksNo ratings yet
- Four Product DWC - ChE Research and Design PDFDocument13 pagesFour Product DWC - ChE Research and Design PDFAlexCooksNo ratings yet
- Effects of Light On Molecular Orientation of Liquid Crystals - F Simoni, O FrancescangeliDocument50 pagesEffects of Light On Molecular Orientation of Liquid Crystals - F Simoni, O FrancescangeliAlexCooksNo ratings yet
- Surface Forces: Surface Roughness in Theory and Experiment - Drew F. Parsons, Rick B. Walsh, Vincent S. J. CraigDocument11 pagesSurface Forces: Surface Roughness in Theory and Experiment - Drew F. Parsons, Rick B. Walsh, Vincent S. J. CraigAlexCooksNo ratings yet
- Dividwall PDFDocument8 pagesDividwall PDFZewdu TsegayeNo ratings yet
- Modelling: Ethanol-Water Pressure Swing Distillation in An Structured Packed Bed ColumnDocument10 pagesModelling: Ethanol-Water Pressure Swing Distillation in An Structured Packed Bed ColumnAlexCooksNo ratings yet
- Sustainability 04 00092Document14 pagesSustainability 04 00092Hansel Sterling SeverinoNo ratings yet
- Final IBF (Numerical) Chapter 2, 5 & 15Document13 pagesFinal IBF (Numerical) Chapter 2, 5 & 15Imtiaz SultanNo ratings yet
- You Exec - MECE Principle FreeDocument6 pagesYou Exec - MECE Principle FreefullaNo ratings yet
- Customs Valuation SystemDocument3 pagesCustoms Valuation SystemJehiel CastilloNo ratings yet
- 1 Eli Lilly Case StudyDocument5 pages1 Eli Lilly Case Studytiiworks50% (2)
- Mba-Mk4 2023Document6 pagesMba-Mk4 2023Lalit SinghNo ratings yet
- Domino's India Logistics Management: By: Sudipta Dutta (10Dr006) Sonalisha Das (10Dr010) Samiran Goswami (10Dr017)Document12 pagesDomino's India Logistics Management: By: Sudipta Dutta (10Dr006) Sonalisha Das (10Dr010) Samiran Goswami (10Dr017)Samiran GoswamiNo ratings yet
- Ocobee River Rafting Company profit analysisDocument4 pagesOcobee River Rafting Company profit analysiskristine torresNo ratings yet
- Tax InvoiceDocument2 pagesTax Invoiceriteshv077777No ratings yet
- WA 6 NPV, IRR and PaybackDocument7 pagesWA 6 NPV, IRR and PaybackUbong AkpekongNo ratings yet
- Mechanical Engg. Market SurveyDocument6 pagesMechanical Engg. Market SurveyDhaval GamechiNo ratings yet
- 4Ms OPERATIONS ENTREPRENEURSHIPDocument42 pages4Ms OPERATIONS ENTREPRENEURSHIPKniwt AdarecrohNo ratings yet
- Walt Disney Case Analysis PDFDocument10 pagesWalt Disney Case Analysis PDFDominic LeeNo ratings yet
- Reliance Retail Limited: Total Amount (In Words) Four Hundred Seventy Rupees and Eighty Two Paise OnlyDocument2 pagesReliance Retail Limited: Total Amount (In Words) Four Hundred Seventy Rupees and Eighty Two Paise OnlymohitahirNo ratings yet
- Business Ethics and Social Responsibility: The Core Principles of Good Corporate GovernanceDocument16 pagesBusiness Ethics and Social Responsibility: The Core Principles of Good Corporate GovernanceRecy Beth EscopelNo ratings yet
- Services MarketingDocument5 pagesServices MarketingSharmaNo ratings yet
- Von Thünen Model Exercise: Prepared by Spinlab Vrije Universiteit AmsterdamDocument6 pagesVon Thünen Model Exercise: Prepared by Spinlab Vrije Universiteit AmsterdamHải Vũ100% (1)
- Ita Imia 2023 BDDocument28 pagesIta Imia 2023 BDKishor YenepalliNo ratings yet
- Impulse Technical, Nifty Algo Performance Sheet 50000Document17 pagesImpulse Technical, Nifty Algo Performance Sheet 50000Video JunctionNo ratings yet
- NPA - SITXWHS007 Assessment 2 - Project FinalDocument25 pagesNPA - SITXWHS007 Assessment 2 - Project FinalJoshua Estrada AbellaNo ratings yet
- Account Reconciliation Policy - Sample 2Document5 pagesAccount Reconciliation Policy - Sample 2Muri EmJayNo ratings yet
- SBI Seeks Insolvency of Western Refrigeration over GuaranteeDocument16 pagesSBI Seeks Insolvency of Western Refrigeration over Guaranteeveer vikramNo ratings yet
- Questionnaire Marketing MixDocument12 pagesQuestionnaire Marketing MixPushpa Barua100% (3)
- 04 PM-Tricks - CostDocument27 pages04 PM-Tricks - CostMahmoud HagagNo ratings yet
- Resume of Omar JadallahDocument1 pageResume of Omar JadallahOmar Jamal 5799No ratings yet
- Copia de SustainableFashionandTextilesDesignJourneysbyKateFletcherEarthscan2008Document6 pagesCopia de SustainableFashionandTextilesDesignJourneysbyKateFletcherEarthscan2008martina torresNo ratings yet
- Lifts Service Lifts: Et EtDocument17 pagesLifts Service Lifts: Et EtPERVEZ AHMAD KHANNo ratings yet
- Business Toolkit For Biogas Construction EnterprisesDocument24 pagesBusiness Toolkit For Biogas Construction EnterprisesSpring MiaNo ratings yet
- MCQS Chapter 8 Company Law 2017Document14 pagesMCQS Chapter 8 Company Law 2017BablooNo ratings yet
- Valuation Report For 2 Storey BuildingDocument3 pagesValuation Report For 2 Storey BuildingAtnapaz JodNo ratings yet
- Wallstreetjournal 20160125 The Wall Street JournalDocument40 pagesWallstreetjournal 20160125 The Wall Street JournalstefanoNo ratings yet