You might also like
- Silberschatz - Galvin - Sistemi Operativi - Concetti Ed EsempiDocument478 pagesSilberschatz - Galvin - Sistemi Operativi - Concetti Ed EsempiErald A. Deliu86% (7)
- Radulescu - Piano Sonata No. 4 Op. 92 PDFDocument38 pagesRadulescu - Piano Sonata No. 4 Op. 92 PDFJoan Bagés Rubí100% (1)
- Real-Time Corpus-Based Concatenative Synthesis With Catart: Diemo Schwarz, GR Egory Beller, Bruno Verbrugghe, Sam BrittonDocument7 pagesReal-Time Corpus-Based Concatenative Synthesis With Catart: Diemo Schwarz, GR Egory Beller, Bruno Verbrugghe, Sam Britton姚熙No ratings yet
- Real-Time Sound Similarity Synthesis by PDFDocument6 pagesReal-Time Sound Similarity Synthesis by PDFStefano FranceschiniNo ratings yet
- Descriptor-Based Sound Texture SamplingDocument8 pagesDescriptor-Based Sound Texture SamplingHakan HakanNo ratings yet
- Icmc 2023 TemplateDocument9 pagesIcmc 2023 TemplatebellNo ratings yet
- IEEETASLP200609goto PDFDocument12 pagesIEEETASLP200609goto PDFGreat ShareNo ratings yet
- Chord Detection Using Deep LearningDocument7 pagesChord Detection Using Deep LearningD Ban ChoNo ratings yet
- UCL IcmcDocument9 pagesUCL IcmcbellNo ratings yet
- Carpentier 2016 OLOFONIA EN Holophonic Sound in Ircam's Concert HallDocument21 pagesCarpentier 2016 OLOFONIA EN Holophonic Sound in Ircam's Concert HallsammarcoNo ratings yet
- Bell ShortenedDocument12 pagesBell ShortenedbellNo ratings yet
- Jurnal - 2Document6 pagesJurnal - 2farizallawi24No ratings yet
- A System For Data-Driven Concatenative Sound SynthesisDocument6 pagesA System For Data-Driven Concatenative Sound SynthesisGiovanni IacovellaNo ratings yet
- WIMP2017 Martinez-RamirezReissDocument4 pagesWIMP2017 Martinez-RamirezReissśūnyatāNo ratings yet
- A Concept Based System For The Live DiffDocument5 pagesA Concept Based System For The Live DiffFinlay McDermidNo ratings yet
- Miron Et Al. - 2013 - An Open-Source Drum Transcription System For Pure Data and Max MSPDocument5 pagesMiron Et Al. - 2013 - An Open-Source Drum Transcription System For Pure Data and Max MSPAlessandro RatociNo ratings yet
- Using Exact Locality Sensitive Mapping To Group and Detect Audio-Based Cover SongsDocument8 pagesUsing Exact Locality Sensitive Mapping To Group and Detect Audio-Based Cover SongsjelushaNo ratings yet
- Towards A Relative-Pitch Neural Network System For Chorale Composition and HarmonizationDocument28 pagesTowards A Relative-Pitch Neural Network System For Chorale Composition and HarmonizationAndrew LiebermannNo ratings yet
- 006 Iccc20Document6 pages006 Iccc20sanyafull0No ratings yet
- Realtime and Accurate Musical Control ofDocument9 pagesRealtime and Accurate Musical Control ofgerardo7martinez-13No ratings yet
- Laden 1989Document16 pagesLaden 1989CaractacusFigulus100% (1)
- CoE 121 Project ProposalDocument1 pageCoE 121 Project ProposalAkinoTenshiNo ratings yet
- Untitled 203Document9 pagesUntitled 203JamesNo ratings yet
- Ambisonics Spatialization Tools For Max/MSP: January 2006Document5 pagesAmbisonics Spatialization Tools For Max/MSP: January 2006PenhaGNo ratings yet
- Spazializzazione PDFDocument5 pagesSpazializzazione PDFStefano FranceschiniNo ratings yet
- Algorithmic Clustering of MusicDocument8 pagesAlgorithmic Clustering of MusicMuhja MufidahNo ratings yet
- The Murmurator: A Flocking Simulation-Driven Multi-Channel Software Instrument For Collaborative ImprovisationDocument6 pagesThe Murmurator: A Flocking Simulation-Driven Multi-Channel Software Instrument For Collaborative ImprovisationEli StineNo ratings yet
- Heittola Et Al. - MUSICAL INSTRUMENT RECOGNITION IN POLYPHONIC AUDIO USING SOURCE-FILTER MODEL FOR SOUND SEPARATIONDocument6 pagesHeittola Et Al. - MUSICAL INSTRUMENT RECOGNITION IN POLYPHONIC AUDIO USING SOURCE-FILTER MODEL FOR SOUND SEPARATIONAlessandro RatociNo ratings yet
- Music Transformer - Generating Music With Long-Term StructureDocument14 pagesMusic Transformer - Generating Music With Long-Term Structureyue123000666No ratings yet
- Exploring Phase Information in Sound Source SeparaDocument9 pagesExploring Phase Information in Sound Source SeparaPaulo FeijãoNo ratings yet
- Gestural Control of Sonic SwarmsDocument4 pagesGestural Control of Sonic SwarmsVictor-Jan GoemansNo ratings yet
- Timbre Space As A Musical Control Structure by David L. Wessel PDFDocument8 pagesTimbre Space As A Musical Control Structure by David L. Wessel PDFSama PiaNo ratings yet
- Music Modeling and Music GenerationDocument8 pagesMusic Modeling and Music Generationconsistent thoughtsNo ratings yet
- LL: Listening and Learning in An Interactive Improvisation SystemDocument7 pagesLL: Listening and Learning in An Interactive Improvisation SystemDANANo ratings yet
- Incze 2018Document6 pagesIncze 2018Prasad HiwarkarNo ratings yet
- Third-Order Ambisonic Extensions For Max/MSP With Musical ApplicationsDocument5 pagesThird-Order Ambisonic Extensions For Max/MSP With Musical ApplicationsPenhaGNo ratings yet
- COMPOSING SOUND OBJECTS IN KYMA - Carla ScalettiDocument29 pagesCOMPOSING SOUND OBJECTS IN KYMA - Carla ScalettiBernardo González CastroNo ratings yet
- Gmu, A Flexible Granular Synthesis Environment in Max:MspDocument6 pagesGmu, A Flexible Granular Synthesis Environment in Max:MspSaaj Alfred JarryNo ratings yet
- Ss Augmented ExpDocument4 pagesSs Augmented ExpAdithyaLingisettyNo ratings yet
- The Timbre Toolbox: Extracting Audio Descriptors From Musical SignalsDocument15 pagesThe Timbre Toolbox: Extracting Audio Descriptors From Musical SignalsAlisa KobzarNo ratings yet
- The Reactive Accompanist Adaptation and Behavior Decomposition in A Music SystemDocument13 pagesThe Reactive Accompanist Adaptation and Behavior Decomposition in A Music SystemCacau Ricardo FerrariNo ratings yet
- Efficient and Robust Music Identification With Weighted Finite-State TransducersDocument12 pagesEfficient and Robust Music Identification With Weighted Finite-State Transducersfadfdafade uohdajufadNo ratings yet
- Optimized Decoders For Mixed-Order AmbisonicsDocument9 pagesOptimized Decoders For Mixed-Order AmbisonicsEric BenjaminNo ratings yet
- (Machine) Learning The Sound of Violins: F.Antonacci, M. ZanoniDocument7 pages(Machine) Learning The Sound of Violins: F.Antonacci, M. ZanoniAdriano AngelicoNo ratings yet
- Bresson 2008 OpenMusicDocument17 pagesBresson 2008 OpenMusicaribezasNo ratings yet
- Separación de Instrumentos MusicalesDocument4 pagesSeparación de Instrumentos MusicalesLino García MoralesNo ratings yet
- Ambisonics Comes of AgeDocument5 pagesAmbisonics Comes of AgeRichard HallumNo ratings yet
- 2012 Spatosc Icmc FinalDocument7 pages2012 Spatosc Icmc FinalPAULO FREITASNo ratings yet
- ANTESCOFO Anticipatory Synchronization andDocument9 pagesANTESCOFO Anticipatory Synchronization andCésar Baracho Dos SantosNo ratings yet
- Dynamic Notation - A Solution To The Conundrum of Non-Standard Music PracticeDocument8 pagesDynamic Notation - A Solution To The Conundrum of Non-Standard Music PracticeXXXXNo ratings yet
- Composing Music With Neural Networks and Probabilistic Finite-State MachinesDocument6 pagesComposing Music With Neural Networks and Probabilistic Finite-State MachinesIoana GrozavNo ratings yet
- Jnam Taslp2010 PDFDocument13 pagesJnam Taslp2010 PDFKai AhoNo ratings yet
- Perceptual Soundfield Reconstruction in Three Dimensions Via Sound Field ExtrapolationDocument5 pagesPerceptual Soundfield Reconstruction in Three Dimensions Via Sound Field ExtrapolationelsieduNo ratings yet
- Chord Detection Using Deep LearningDocument8 pagesChord Detection Using Deep LearningEugene QuahNo ratings yet
- Music Transcription Modelling and Composition Using Deep LearningDocument16 pagesMusic Transcription Modelling and Composition Using Deep LearningIoana GrozavNo ratings yet
- A Scalable Framework For Joint Clustering and Synchronizing Multi-Camera VideosDocument6 pagesA Scalable Framework For Joint Clustering and Synchronizing Multi-Camera Videostravelwonder123No ratings yet
- Structured Additive Synthesis: Towards A Model of Sound Timbre and Electroacoustic Music FormsDocument4 pagesStructured Additive Synthesis: Towards A Model of Sound Timbre and Electroacoustic Music FormsJuan Ignacio Isgro100% (1)
- Vibrato Extraction and Parameterization PDFDocument5 pagesVibrato Extraction and Parameterization PDFGreyce OrnelasNo ratings yet
- OM Sound ProcessingDocument6 pagesOM Sound ProcessingjerikleshNo ratings yet
- Towards The Digital Music Library: Tune Retrieval From Acoustic InputDocument8 pagesTowards The Digital Music Library: Tune Retrieval From Acoustic InputRamesh_Vadali_1123No ratings yet
- Designing Quiet Structures: A Sound Power Minimization ApproachFrom EverandDesigning Quiet Structures: A Sound Power Minimization ApproachNo ratings yet
- Audio Source Separation and Speech EnhancementFrom EverandAudio Source Separation and Speech EnhancementEmmanuel VincentNo ratings yet
- PhD2005 Sjorda PDFDocument531 pagesPhD2005 Sjorda PDFJoan Bagés RubíNo ratings yet
- Gesture Overview PDFDocument89 pagesGesture Overview PDFJoan Bagés RubíNo ratings yet
- Fathers and Spaces - Salzburger Festspiele 97Document3 pagesFathers and Spaces - Salzburger Festspiele 97Joan Bagés RubíNo ratings yet
- Algorithmic Composition (2007)Document3 pagesAlgorithmic Composition (2007)Joan Bagés RubíNo ratings yet
- Sequitur V: Karlheinz EsslDocument6 pagesSequitur V: Karlheinz EsslJoan Bagés RubíNo ratings yet
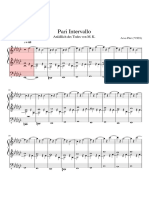
- Pari IntervaloDocument3 pagesPari IntervaloJoan Bagés RubíNo ratings yet
- Unit 1: The Database Environment: Topic 1: Basic Concepts and Terminologies Data vs. Information - DataDocument27 pagesUnit 1: The Database Environment: Topic 1: Basic Concepts and Terminologies Data vs. Information - DataVance GonzalesNo ratings yet
- Hobby: Jawaban QuizDocument3 pagesHobby: Jawaban QuizHarry Iswanto SimanjuntakNo ratings yet
- File Management: Paths and Trees and FoldersDocument29 pagesFile Management: Paths and Trees and FoldersArpit KumarNo ratings yet
- Veritas - Testking.vcs 278.v2019!11!24.by .Philip.75qDocument38 pagesVeritas - Testking.vcs 278.v2019!11!24.by .Philip.75qMustapha ASSILANo ratings yet
- Leetcode DSA Sheet by FrazDocument23 pagesLeetcode DSA Sheet by FrazAbhijit MaliNo ratings yet
- Computer Applications SoftwareDocument1 pageComputer Applications Softwarereymilyn zuluetaNo ratings yet
- Disk Space Is Not Released After Deleting Many FilesDocument3 pagesDisk Space Is Not Released After Deleting Many Fileselcaso34No ratings yet
- Unit-1 Question BankDocument4 pagesUnit-1 Question BankIndigoNo ratings yet
- SQL Commands : Create The Database Loans. Use Database LoansDocument9 pagesSQL Commands : Create The Database Loans. Use Database LoansShivam SharmaNo ratings yet
- Case StudyDocument3 pagesCase StudyNoona FreeNo ratings yet
- Doc-20240125-Wa0000 11 12 13 14 15Document4 pagesDoc-20240125-Wa0000 11 12 13 14 15alfaqihabdallah89No ratings yet
- Tabele Do ĆwiczeńDocument4 pagesTabele Do ĆwiczeńYessserNo ratings yet
- Extract PDF Metadata LinuxDocument2 pagesExtract PDF Metadata LinuxKaylaNo ratings yet
- Beginner's Guide To Delphi Database ProgrammingDocument27 pagesBeginner's Guide To Delphi Database ProgrammingLiviuNo ratings yet
- Budgeting Process and Pitching Ppt-Module-1,2Document52 pagesBudgeting Process and Pitching Ppt-Module-1,2Abhishek RainaNo ratings yet
- Rdbms File 2nd SemDocument53 pagesRdbms File 2nd SemAnmol SharmaNo ratings yet
- nORMALIZATION EXTRANOTESDocument5 pagesnORMALIZATION EXTRANOTESMohamed Luffycero Ahmed100% (1)
- SubbaChary SQL DBA 4 YrsDocument4 pagesSubbaChary SQL DBA 4 YrspraveenmpkNo ratings yet
- 1 Getting Started Power Bi m1 Slides PDFDocument13 pages1 Getting Started Power Bi m1 Slides PDFGowrinath ChennuruNo ratings yet
- SAS® 9.1 OLAP Server Security: Table 1: Summary of Permissions Required For OLAP-related TasksDocument9 pagesSAS® 9.1 OLAP Server Security: Table 1: Summary of Permissions Required For OLAP-related TasksJoydeep LahiriNo ratings yet
- MySQL Server Variable TuningDocument24 pagesMySQL Server Variable TuningOli SennhauserNo ratings yet
- Final Updated DBIS Record 2Document72 pagesFinal Updated DBIS Record 2shruthihasinineeratiNo ratings yet
- 28224lab 3Document6 pages28224lab 3aman singhNo ratings yet
- ResumeDocument4 pagesResumeSandeep LakkumdasNo ratings yet
- Distributed File SystemsDocument38 pagesDistributed File SystemsManziniLeeNo ratings yet
- Cheat Exam OracleDocument18 pagesCheat Exam OracleOana StoicaNo ratings yet
- #Procedure To Find Square of A Given NoDocument10 pages#Procedure To Find Square of A Given NoShivaniNo ratings yet
- SOP-CIT-005.01 Backup and Restore Management - (Effective)Document14 pagesSOP-CIT-005.01 Backup and Restore Management - (Effective)Andre WirawanNo ratings yet
- OData UI5 and CDSDocument15 pagesOData UI5 and CDSIonel CalinNo ratings yet