You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- DNA Replication - LabelingDocument2 pagesDNA Replication - Labelingนายโรจนศักดิ์ สุขเรืองNo ratings yet
- PMLSP 1st Yr 1st SemDocument34 pagesPMLSP 1st Yr 1st SemKhaye Dela CruzNo ratings yet
- Chapter 7. Proteins and AminoacidsDocument37 pagesChapter 7. Proteins and AminoacidsMuhammad Adil Farhan Bin Ramlan E19A0157No ratings yet
- Traditional Dance in The Philippines: 4. TiniklingDocument2 pagesTraditional Dance in The Philippines: 4. TiniklingKhaye Dela CruzNo ratings yet
- Poxviridae Adenoviruses Papovaviridae PapovaviridaeDocument9 pagesPoxviridae Adenoviruses Papovaviridae PapovaviridaeKhaye Dela CruzNo ratings yet
- Walther Flemming: Cytogenetics Prelim NotesDocument11 pagesWalther Flemming: Cytogenetics Prelim NotesGilbert Reyes MendozaNo ratings yet
- Tinikling Folk Dance: What Is The History of The Tinikling Dance?Document3 pagesTinikling Folk Dance: What Is The History of The Tinikling Dance?Khaye Dela CruzNo ratings yet
- Rizal ControversyDocument3 pagesRizal ControversyKhaye Dela CruzNo ratings yet
- Time Monday Tuesday Wednesday Thursday Friday SaturdayDocument4 pagesTime Monday Tuesday Wednesday Thursday Friday SaturdayKhaye Dela CruzNo ratings yet
- Data Privacy and Anti-Cyber Bullying AgreementDocument6 pagesData Privacy and Anti-Cyber Bullying AgreementKhaye Dela CruzNo ratings yet
- (2nd Year) Orientation ProgramDocument4 pages(2nd Year) Orientation ProgramKhaye Dela CruzNo ratings yet
- SMLS First Prelim Sched FinalDocument1 pageSMLS First Prelim Sched FinalKhaye Dela CruzNo ratings yet
- How To Fill Up The Data Privacy and Anti-Cyber Bullying AgreementDocument2 pagesHow To Fill Up The Data Privacy and Anti-Cyber Bullying AgreementKhaye Dela CruzNo ratings yet
- $RVHQI2KDocument9 pages$RVHQI2KKhaye Dela CruzNo ratings yet
- Exam Reminders For StudentsDocument2 pagesExam Reminders For StudentsKhaye Dela CruzNo ratings yet
- $RUEXE8HDocument7 pages$RUEXE8HKhaye Dela CruzNo ratings yet
- $R5Q82RSDocument6 pages$R5Q82RSKhaye Dela CruzNo ratings yet
- $REG92AFDocument6 pages$REG92AFKhaye Dela CruzNo ratings yet
- R@1 NDocument2 pagesR@1 NSonny CitizenNo ratings yet
- $RU850L6Document13 pages$RU850L6Khaye Dela CruzNo ratings yet
- $RD84YIIDocument5 pages$RD84YIIKhaye Dela CruzNo ratings yet
- $RCNGC9DDocument8 pages$RCNGC9DKhaye Dela CruzNo ratings yet
- $ROTDTKZDocument1 page$ROTDTKZKhaye Dela CruzNo ratings yet
- $RTQTFX4Document5 pages$RTQTFX4Khaye Dela CruzNo ratings yet
- $RFQ5EKTDocument4 pages$RFQ5EKTKhaye Dela CruzNo ratings yet
- $R1E30MFDocument8 pages$R1E30MFKhaye Dela CruzNo ratings yet
- $ROZENJRDocument7 pages$ROZENJRKhaye Dela CruzNo ratings yet
- $RBDRTVYDocument9 pages$RBDRTVYKhaye Dela CruzNo ratings yet
- $RSTWVGIDocument2 pages$RSTWVGIKhaye Dela CruzNo ratings yet
- $RBDRTVYDocument9 pages$RBDRTVYKhaye Dela CruzNo ratings yet
- $RQ8UTUWDocument6 pages$RQ8UTUWKhaye Dela CruzNo ratings yet
- Alpha InterferonDocument7 pagesAlpha InterferonLAURA MARCELA BARRENECHE CALLENo ratings yet
- Ecoli Insulin Factory PDFDocument8 pagesEcoli Insulin Factory PDFWilliams de la Cruz0% (1)
- Concepts in Biology 14th Edition Enger Test BankDocument40 pagesConcepts in Biology 14th Edition Enger Test BankChristianBrownmisre100% (18)
- BIOCATALYSISDocument4 pagesBIOCATALYSISanis azizNo ratings yet
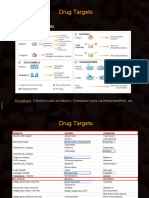
- Four Major Drug TargetsDocument34 pagesFour Major Drug TargetsFlowerNo ratings yet
- Cytokines, Cytokine Receptors and Chemokines: Sept. 11, 2014Document101 pagesCytokines, Cytokine Receptors and Chemokines: Sept. 11, 2014ANJU0709No ratings yet
- CH 3Document14 pagesCH 3Qais Bani HaniNo ratings yet
- Hsslive XI Zoology CH 9 BiomoleculesDocument13 pagesHsslive XI Zoology CH 9 Biomolecules스탠 케이팝No ratings yet
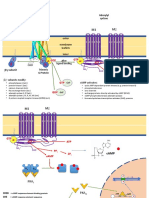
- G Protein Coupled Receptor (GPCR) Adenylyl Cyclase: Ligand BindingDocument3 pagesG Protein Coupled Receptor (GPCR) Adenylyl Cyclase: Ligand BindingPanda DaoNo ratings yet
- Nucleic AcidDocument12 pagesNucleic AcidharshitNo ratings yet
- Activity 13 DNAReplicationPupil Case StudyDocument9 pagesActivity 13 DNAReplicationPupil Case Studyavita rukmanaNo ratings yet
- Answer Questions5 1Document3 pagesAnswer Questions5 1yo-chengNo ratings yet
- RNA Editing & Alternative SplicingDocument11 pagesRNA Editing & Alternative SplicingSurya PrakashNo ratings yet
- Transcription in Prokaryotes PPTDocument50 pagesTranscription in Prokaryotes PPTKeneth CandidoNo ratings yet
- Science 10 - Module 33Document8 pagesScience 10 - Module 33Karlyn Kaye SalungaNo ratings yet
- Khan Academy DNA Technology QuestionsDocument4 pagesKhan Academy DNA Technology QuestionsLoraNo ratings yet
- Gene - Site-Directed MutagenesisDocument2 pagesGene - Site-Directed Mutagenesisapi-252004782No ratings yet
- Lesson 1.7 Learning Task WorksheetDocument6 pagesLesson 1.7 Learning Task WorksheetRayan abdallaNo ratings yet
- Protein Assay: Christa Edo G0017044Document22 pagesProtein Assay: Christa Edo G0017044Anis Sofia HarjantiNo ratings yet
- Promega HaloTag Fusion Protein GuideDocument3 pagesPromega HaloTag Fusion Protein GuideMoritz ListNo ratings yet
- Chapter 2 (Introduction To Biotechnology)Document12 pagesChapter 2 (Introduction To Biotechnology)Latif Ur RehmanNo ratings yet
- Wikipedia - Readings On Life Evolutionary History V2Document3,688 pagesWikipedia - Readings On Life Evolutionary History V2tariqamin5978No ratings yet
- Chapter 4 Protein Mind Map PDFDocument1 pageChapter 4 Protein Mind Map PDFCynthia LingNo ratings yet
- Lipid Map of The Mammalian CellDocument4 pagesLipid Map of The Mammalian Celljuan joseNo ratings yet
- Le Ch. 6.2 EnzymesDocument17 pagesLe Ch. 6.2 EnzymesAehronCatilocNo ratings yet
- Solid-Phase Indirect Assay SystemDocument4 pagesSolid-Phase Indirect Assay SystemJereco CatbaganNo ratings yet
- A Simple and Quick Method For Successful Sequencing of Difficult Genomic RegionsDocument8 pagesA Simple and Quick Method For Successful Sequencing of Difficult Genomic RegionsAsmaNo ratings yet
- Restriction Enzyme 2 1Document3 pagesRestriction Enzyme 2 1jeidre pamorcaNo ratings yet