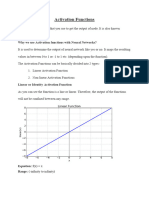
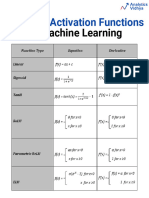
You might also like
- Multilayer Perceptron: Fundamentals and Applications for Decoding Neural NetworksFrom EverandMultilayer Perceptron: Fundamentals and Applications for Decoding Neural NetworksNo ratings yet
- Aditya Jain NN AssignmentDocument13 pagesAditya Jain NN AssignmentAditya JainNo ratings yet
- Unit 2 - Machine LearningDocument19 pagesUnit 2 - Machine LearningGauri BansalNo ratings yet
- 12 Types of Neural Network Activation FunctionsDocument38 pages12 Types of Neural Network Activation FunctionsNusrat UllahNo ratings yet
- Unit 2Document18 pagesUnit 2Nitya ShuklaNo ratings yet
- Activation FunctionsDocument8 pagesActivation FunctionsRoushan GiriNo ratings yet
- Notes On Introduction To Deep LearningDocument19 pagesNotes On Introduction To Deep Learningthumpsup1223No ratings yet
- Lecture 2.1.2activation FunctionDocument15 pagesLecture 2.1.2activation FunctionMohd YusufNo ratings yet
- Activation FunctionDocument13 pagesActivation FunctionPrincess SwethaNo ratings yet
- Unit 2 - Machine Learning - WWW - Rgpvnotes.inDocument18 pagesUnit 2 - Machine Learning - WWW - Rgpvnotes.inROHIT MISHRANo ratings yet
- DeepLearing TheoryDocument51 pagesDeepLearing TheorytharunNo ratings yet
- Functii de Activare1Document89 pagesFunctii de Activare1adrian IosifNo ratings yet
- AITools Unit-4Document25 pagesAITools Unit-4SivaNo ratings yet
- SoftComp 02Document33 pagesSoftComp 02Aditya RautNo ratings yet
- Understanding Neural NetworksDocument12 pagesUnderstanding Neural NetworksKarol SkowronskiNo ratings yet
- Deep Learning - DL-2Document44 pagesDeep Learning - DL-2Hasnain AhmadNo ratings yet
- Lec 21Document42 pagesLec 21ABHIRAJ ENo ratings yet
- Activation Functions in Neural Networks - GeeksforGeeksDocument12 pagesActivation Functions in Neural Networks - GeeksforGeekswendu felekeNo ratings yet
- Activation Function - Lect 1Document5 pagesActivation Function - Lect 1NiteshNarukaNo ratings yet
- Ann MJJ-1Document64 pagesAnn MJJ-1RohitNo ratings yet
- Growing Cosine Unit: A Novel Oscillatory Activation Function That Can Speedup Training and Reduce Parameters in Convolutional Neural NetworksDocument14 pagesGrowing Cosine Unit: A Novel Oscillatory Activation Function That Can Speedup Training and Reduce Parameters in Convolutional Neural NetworksGuru VelmathiNo ratings yet
- ML Unit-2Document141 pagesML Unit-26644 HaripriyaNo ratings yet
- Deep Learning Unit 1Document32 pagesDeep Learning Unit 1Aditya Pratap SinghNo ratings yet
- Experiment No. 1 SL-II (ANN)Document3 pagesExperiment No. 1 SL-II (ANN)RutujaNo ratings yet
- Machine Learning and Pattern Recognition Week 8 Neural Net IntroDocument3 pagesMachine Learning and Pattern Recognition Week 8 Neural Net IntrozeliawillscumbergNo ratings yet
- Introduction To Neurons and Artificial Neural NetworksDocument34 pagesIntroduction To Neurons and Artificial Neural NetworksFahim MiddyaNo ratings yet
- Unit IvDocument34 pagesUnit Ivdanmanworld443No ratings yet
- From Perceptron To Deep Neural Nets - Becoming Human - Artificial Intelligence MagazineDocument36 pagesFrom Perceptron To Deep Neural Nets - Becoming Human - Artificial Intelligence MagazineWondwesen FelekeNo ratings yet
- An Introduction To Artificial Neural Networks - by Srivignesh Rajan - Towards Data ScienceDocument11 pagesAn Introduction To Artificial Neural Networks - by Srivignesh Rajan - Towards Data ScienceRavan FarmanovNo ratings yet
- How To Choose An Activation Function For Deep LearningDocument15 pagesHow To Choose An Activation Function For Deep LearningAbdul KhaliqNo ratings yet
- Activation Functions - Ipynb - ColaboratoryDocument10 pagesActivation Functions - Ipynb - ColaboratoryGOURAV SAHOONo ratings yet
- Activation FunctionsDocument6 pagesActivation FunctionsthummalakuntasNo ratings yet
- Unit I Architecture of Neural NetworkDocument74 pagesUnit I Architecture of Neural NetworkDSYMEC224Trupti BagalNo ratings yet
- Backpropag-Relu-Grad DescentDocument2 pagesBackpropag-Relu-Grad DescentNishita VermaNo ratings yet
- ReLu Heuristics For Avoiding Local Bad MinimaDocument10 pagesReLu Heuristics For Avoiding Local Bad MinimaShanmuganathan V (RC2113003011029)100% (1)
- A Gentle Introduction To The Rectified Linear Unit (ReLU)Document17 pagesA Gentle Introduction To The Rectified Linear Unit (ReLU)21008059No ratings yet
- Module 5 AIML NotesDocument77 pagesModule 5 AIML Notesbabureddybn262003No ratings yet
- 9 - Neural Networks 1Document11 pages9 - Neural Networks 1Munam Naseer100% (1)
- Activation FunctionsDocument7 pagesActivation FunctionsTgowtham ArasuNo ratings yet
- Understanding Activation Functions in Neural NetworksDocument15 pagesUnderstanding Activation Functions in Neural Networkswendu felekeNo ratings yet
- Neural Network: BY, Deekshitha J P Rakshitha ShankarDocument27 pagesNeural Network: BY, Deekshitha J P Rakshitha ShankarDeekshitha J PNo ratings yet
- Perceptron: Single Layer Neural NetworkDocument14 pagesPerceptron: Single Layer Neural NetworkGayuNo ratings yet
- Activation FunctionDocument31 pagesActivation FunctionAnkur SharmaNo ratings yet
- Deep Learning PDFDocument55 pagesDeep Learning PDFNitesh Kumar SharmaNo ratings yet
- NNDLDocument96 pagesNNDLYogesh KrishnaNo ratings yet
- Deep Learning Algorithms Report PDFDocument11 pagesDeep Learning Algorithms Report PDFrohillaanshul12No ratings yet
- 0905 Cs 161183 VishalDocument38 pages0905 Cs 161183 VishalVishal JainNo ratings yet
- Deep Learning Unit 2Document30 pagesDeep Learning Unit 2Aditya Pratap SinghNo ratings yet
- Fundamentals Deep Learning Activation Functions When To Use ThemDocument15 pagesFundamentals Deep Learning Activation Functions When To Use ThemfaisalNo ratings yet
- A Probabilistic Theory of Deep Learning: Unit 2Document17 pagesA Probabilistic Theory of Deep Learning: Unit 2HarshitNo ratings yet
- Preparatory Presentation of Relevant ML AreasDocument8 pagesPreparatory Presentation of Relevant ML AreasSamridhi ThakurNo ratings yet
- Activation Functions in Neural NetworksDocument10 pagesActivation Functions in Neural Networksisha.kapoor.cse.2021No ratings yet
- Activation Functions in Neural Networks: What Is Activation Function?Document11 pagesActivation Functions in Neural Networks: What Is Activation Function?Navneet LalwaniNo ratings yet
- Activation Functions: Sigmoid, Tanh, Relu, Leaky Relu, Prelu, Elu, Threshold Relu and Softmax Basics For Neural Networks and Deep LearningDocument15 pagesActivation Functions: Sigmoid, Tanh, Relu, Leaky Relu, Prelu, Elu, Threshold Relu and Softmax Basics For Neural Networks and Deep LearningRMolina65No ratings yet
- Lecture Notes 3Document5 pagesLecture Notes 3fgsfgsNo ratings yet
- CC511 Week 5 - 6 - NN - BPDocument62 pagesCC511 Week 5 - 6 - NN - BPmohamed sherifNo ratings yet
- Introduction To ANNsDocument31 pagesIntroduction To ANNsanjoomNo ratings yet
- Activation Functions and Their Characteristics in Deep Neural NetworksDocument6 pagesActivation Functions and Their Characteristics in Deep Neural NetworksSatyamNo ratings yet
- Lecture-02: PGDDS 202Document15 pagesLecture-02: PGDDS 202Lony IslamNo ratings yet
- Deep MLP'sDocument44 pagesDeep MLP'sprabhakaran sridharanNo ratings yet
- Effects of Teacher Training On Secondary TeachersDocument16 pagesEffects of Teacher Training On Secondary TeachersArindam PaulNo ratings yet
- Automated Classification of A Tropical Landscape Infested by Parthenium Weed (Parthenium Hyterophorus)Document24 pagesAutomated Classification of A Tropical Landscape Infested by Parthenium Weed (Parthenium Hyterophorus)Arindam PaulNo ratings yet
- Bandwidth Management and Quality of ServiceDocument151 pagesBandwidth Management and Quality of ServiceArindam PaulNo ratings yet
- Oil Field EOR Modeling SimulationDocument14 pagesOil Field EOR Modeling SimulationArindam PaulNo ratings yet
- Modelling The Spread of COVID-19 Among Doctors From The Asymptomatic IndividualsDocument22 pagesModelling The Spread of COVID-19 Among Doctors From The Asymptomatic IndividualsArindam PaulNo ratings yet
- A Review On Weed Detection Using Image Processing: Lavanya N.R., Niharika S., Deepika C.H., Harini M. and Chetana K.SDocument3 pagesA Review On Weed Detection Using Image Processing: Lavanya N.R., Niharika S., Deepika C.H., Harini M. and Chetana K.SArindam PaulNo ratings yet
- Confusion Matrix-1Document15 pagesConfusion Matrix-1Arindam PaulNo ratings yet
- Options, Futures, and Other Derivatives, 10th Edition, Copyright © John C. Hull 2017Document15 pagesOptions, Futures, and Other Derivatives, 10th Edition, Copyright © John C. Hull 2017Arindam PaulNo ratings yet
- Linearization of Differential Equation Models: 1 MotivationDocument13 pagesLinearization of Differential Equation Models: 1 MotivationArindam PaulNo ratings yet
- Trapazamine ModelingDocument8 pagesTrapazamine ModelingArindam PaulNo ratings yet
- CH 34 Hull OFOD9 TH EditionDocument23 pagesCH 34 Hull OFOD9 TH Editionseanwu95No ratings yet
- CH 13 Hull OFOD9 TH EditionDocument26 pagesCH 13 Hull OFOD9 TH Editionseanwu95No ratings yet
- CH 16 Hull OFOD8 TH EditionDocument24 pagesCH 16 Hull OFOD8 TH EditionNavin PrabhatNo ratings yet
- CH 16 Hull OFOD9 TH EditionDocument14 pagesCH 16 Hull OFOD9 TH Editionseanwu95No ratings yet
- CH 11 Hull OFOD9 TH EditionDocument20 pagesCH 11 Hull OFOD9 TH EditionJohn Paul TuohyNo ratings yet
- Options, Futures, and Other Derivatives, 8th Edition, 1Document34 pagesOptions, Futures, and Other Derivatives, 8th Edition, 1cute_bee33100% (3)
- CH 08 Hull OFOD9 TH EditionDocument13 pagesCH 08 Hull OFOD9 TH EditionGautam BindlishNo ratings yet
- Gradient, DivergenceDocument39 pagesGradient, DivergenceArindam PaulNo ratings yet
- CH 03 Hull OFOD8 TH EditionDocument18 pagesCH 03 Hull OFOD8 TH EditionafomjNo ratings yet
- Ma324 2 PDFDocument1 pageMa324 2 PDFtaruNo ratings yet
- CNN Basic Beak of BirdDocument20 pagesCNN Basic Beak of BirdPoralla priyanka100% (1)
- Lecture 4: Special Distribution Function & Joint Probability DistributionDocument61 pagesLecture 4: Special Distribution Function & Joint Probability DistributionRahmat JunaidiNo ratings yet
- Foundations of Probability in PythonDocument44 pagesFoundations of Probability in Pythonsunny.anjaniNo ratings yet
- Act CH 1Document23 pagesAct CH 1Magarsa BedasaNo ratings yet
- Assignment On Sta 614Document21 pagesAssignment On Sta 614Obulezi OJNo ratings yet
- PTSP SyllabusDocument2 pagesPTSP SyllabusTayyabunnissa BegumNo ratings yet
- Deep Learning For Smart Manufacturing: Methods and ApplicationsDocument14 pagesDeep Learning For Smart Manufacturing: Methods and ApplicationsAce TobikumaNo ratings yet
- Forecasting Malaysian Gold UsingDocument6 pagesForecasting Malaysian Gold UsingIzzah Nazatul Nazihah Binti EjapNo ratings yet
- Gate Questions On Finite Automata - Theory-of-Computation - AcademyEra2 PDFDocument13 pagesGate Questions On Finite Automata - Theory-of-Computation - AcademyEra2 PDFmukesh guptaNo ratings yet
- Perbandingan Regresi Zero Inflated Poisson Zip Dan PDFDocument6 pagesPerbandingan Regresi Zero Inflated Poisson Zip Dan PDFalmatrisaNo ratings yet
- LSTM Recurrent Neural Networks - How To Teach A Network To Remember The Past - by Saul Dobilas - Towards Data ScienceDocument20 pagesLSTM Recurrent Neural Networks - How To Teach A Network To Remember The Past - by Saul Dobilas - Towards Data Sciencetarunbandari4504No ratings yet
- Unit - III Joint Probability Distribution (Full Notes)Document30 pagesUnit - III Joint Probability Distribution (Full Notes)Acchyutjh100% (2)
- Chapter - 9-Lectures Dr. SAEEDDocument90 pagesChapter - 9-Lectures Dr. SAEEDفيصل القرشيNo ratings yet
- LU5: Deep Feedforward Networks: Hidden Units, Architecture DesignDocument15 pagesLU5: Deep Feedforward Networks: Hidden Units, Architecture DesignDEIVAM RNo ratings yet
- Understanding of Convolutional Neural Network (CNN) - Deep LearningDocument9 pagesUnderstanding of Convolutional Neural Network (CNN) - Deep LearningMark Alwin CaimbreNo ratings yet
- Answer Key (For MCQ Questions Only)Document6 pagesAnswer Key (For MCQ Questions Only)Apoorv SharmaNo ratings yet
- Ma2262 Probability and Queuing Theory: F (X) K If XDocument18 pagesMa2262 Probability and Queuing Theory: F (X) K If XSivabalanNo ratings yet
- Bapatla Engineering College, Bapatla: (Autonomous) Regd. No: Marks: L20ACS587Document64 pagesBapatla Engineering College, Bapatla: (Autonomous) Regd. No: Marks: L20ACS587Kishan ChandNo ratings yet
- Decision Making & Forecasting: Dr. Sharad VardeDocument37 pagesDecision Making & Forecasting: Dr. Sharad VardeFarid CharaniaNo ratings yet
- ARCH GARCH AssignmentDocument8 pagesARCH GARCH AssignmentSruti SuhasariaNo ratings yet
- A Probability and Statistics CheatsheetDocument28 pagesA Probability and Statistics CheatsheetfarahNo ratings yet
- Topics APM 381-Winter 2007: Oakland UniversityDocument4 pagesTopics APM 381-Winter 2007: Oakland Universitytrupti.kodinariya9810No ratings yet
- Formal DefinitionDocument152 pagesFormal DefinitionJai kumarNo ratings yet
- Manual For Neural and Matlab ApplicationsDocument37 pagesManual For Neural and Matlab ApplicationsKiran Jot SinghNo ratings yet
- A Survey On Deep Learning For Multimodal Data FusionDocument36 pagesA Survey On Deep Learning For Multimodal Data FusionllNo ratings yet
- Mat 263 - Probability Theory May 2010Document12 pagesMat 263 - Probability Theory May 2010Lim ZYNo ratings yet
- Project 7Document6 pagesProject 7sandy milk min100% (1)
- Artificial Neural NetworkDocument72 pagesArtificial Neural Networkwawan gunawanNo ratings yet
- Rice DistributionDocument8 pagesRice DistributionTemkin TegegnNo ratings yet