You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (844)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5810)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Reading ResponsesDocument64 pagesReading ResponsesRicky Favela0% (1)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- 20 Ways To Make 100 Per Day OnlineDocument247 pages20 Ways To Make 100 Per Day Onlinehugo789No ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- RRL About Sleep DeprivationDocument8 pagesRRL About Sleep DeprivationZanila YoshiokaNo ratings yet
- Python ProgrammingDocument40 pagesPython Programmingwvargas926No ratings yet
- English 9 Quarter 2 Weeks 3-4Document10 pagesEnglish 9 Quarter 2 Weeks 3-4Heidee BasasNo ratings yet
- Types of Strategies in Strategic ManagementDocument6 pagesTypes of Strategies in Strategic ManagementHan O100% (3)
- Christmas Carols December 24, 2015 O Holy NightDocument1 pageChristmas Carols December 24, 2015 O Holy NightGladys Araneta SaritoNo ratings yet
- Antipsychotics 1Document41 pagesAntipsychotics 1fahad rustam100% (1)
- Atale of Two CitiesDocument17 pagesAtale of Two Citieshasan ibrahimNo ratings yet
- Cause and Effect of Poverty EssayDocument5 pagesCause and Effect of Poverty Essayafibzfwdkaesyf100% (2)
- Facial Wash From NEEM Tree LeavesDocument6 pagesFacial Wash From NEEM Tree LeavesHarvey James ChuaNo ratings yet
- 01 Track Listings Part 16Document12 pages01 Track Listings Part 16Mike MikerNo ratings yet
- HP Vertica 7.1.x IntegratingApacheHadoopDocument135 pagesHP Vertica 7.1.x IntegratingApacheHadoopRahul VishwakarmaNo ratings yet
- Physics SPM DefinitionDocument6 pagesPhysics SPM DefinitionDeqWa EwaNo ratings yet
- Administering QlikViewDocument214 pagesAdministering QlikViewSudhaNo ratings yet
- ID Analisis Faktor Faktor Yang MempengaruhiDocument17 pagesID Analisis Faktor Faktor Yang MempengaruhiM Fadhilah FadliNo ratings yet
- Daffodil International University: LAW 37th Batch English IIDocument3 pagesDaffodil International University: LAW 37th Batch English IIFoujia HasanNo ratings yet
- Tockingtonian 2011Document29 pagesTockingtonian 2011Tockington Manor SchoolNo ratings yet
- Sartorius A200S Electronic Analytical Balance: 1.0titleDocument7 pagesSartorius A200S Electronic Analytical Balance: 1.0titleTarekNo ratings yet
- RPS English MorphologyDocument12 pagesRPS English MorphologynurulwasilaturrahmahNo ratings yet
- SL SN.01 000 V7 GBDocument18 pagesSL SN.01 000 V7 GBStan HonNo ratings yet
- Physical PharmaceuticsDocument39 pagesPhysical Pharmaceuticsrapuenzel50% (2)
- Ip Touch 4008Document29 pagesIp Touch 4008Jose Alberto Redondo CampillosNo ratings yet
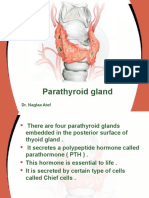
- 5 Parathyroid GlandDocument24 pages5 Parathyroid GlandReem 10No ratings yet
- U.S. Copyright Renewals, 1952 July - December by U.S. Copyright OfficeDocument238 pagesU.S. Copyright Renewals, 1952 July - December by U.S. Copyright OfficeGutenberg.orgNo ratings yet
- AGAPITOS, Literature - and - Education in NicaeaDocument40 pagesAGAPITOS, Literature - and - Education in NicaeaoerwoudtNo ratings yet
- Bitsat 2018 Question PaperDocument20 pagesBitsat 2018 Question PaperNew Scribd userNo ratings yet
- Laporan Bulanan Lb1: 0-7 HR Baru LDocument20 pagesLaporan Bulanan Lb1: 0-7 HR Baru LOla SarlinaNo ratings yet
- Famous Festivals in The PhilippinesDocument4 pagesFamous Festivals in The PhilippinesPrincess Villasis BaciaNo ratings yet
- gSOAP License SDF VFSD VDocument1 pagegSOAP License SDF VFSD Vrah98No ratings yet