You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5806)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (842)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (589)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Specification 33 KV LineDocument18 pagesSpecification 33 KV LineSatyaprasad NimmakayalaNo ratings yet
- CHAPTER 1 Formation and Structure of Foams Pressure in The Liquid and Gas 1998Document41 pagesCHAPTER 1 Formation and Structure of Foams Pressure in The Liquid and Gas 1998Anonymous UYDJtUnNo ratings yet
- 770 - Rail Clamp Manual (GA-9-180KN-TR68 Ex II 2D T3)Document30 pages770 - Rail Clamp Manual (GA-9-180KN-TR68 Ex II 2D T3)j3fersonNo ratings yet
- DAN2400 Product BriefDocument2 pagesDAN2400 Product BriefGuy ResheffNo ratings yet
- Zener DiodeDocument14 pagesZener Diodes211053176No ratings yet
- Merge Outlook PSTDocument5 pagesMerge Outlook PSTjeremybrownNo ratings yet
- Motor2 A Passo de Passo DST86 SeriesDocument20 pagesMotor2 A Passo de Passo DST86 SeriesAlisson laraNo ratings yet
- 30-60-15-300 Training 2ppDocument48 pages30-60-15-300 Training 2ppjorgepm18No ratings yet
- Draw The Orthographic Front View, Top View and Side View of The Given Object Using AutocadDocument81 pagesDraw The Orthographic Front View, Top View and Side View of The Given Object Using AutocadKartik BansalNo ratings yet
- Seminar Manajemen PemasaranDocument15 pagesSeminar Manajemen PemasaranhendyNo ratings yet
- Pola Seismic Code CommentaryDocument15 pagesPola Seismic Code Commentary_ARCUL_100% (1)
- EBARA Reference DataDocument6 pagesEBARA Reference DataMarcelo Peretti100% (1)
- General Diagnostic Table: Malfunction of Parts Other Than Those Listed Is Also Possible.Document2 pagesGeneral Diagnostic Table: Malfunction of Parts Other Than Those Listed Is Also Possible.miguelNo ratings yet
- Lec37 PDFDocument21 pagesLec37 PDFTesh SiNo ratings yet
- Mathematics Methods Sample Calc Free Marking Key 2016Document13 pagesMathematics Methods Sample Calc Free Marking Key 2016gragon.07No ratings yet
- 11Document21 pages11Sumeet Gupta0% (2)
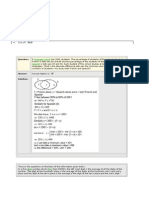
- Set Theory Square RootDocument2 pagesSet Theory Square RootrajatNo ratings yet
- Body Mass Index - Wikipedia, The Free EncyclopediaDocument10 pagesBody Mass Index - Wikipedia, The Free EncyclopediaRupam DasNo ratings yet
- D 850 - 99 - Rdg1mc05oueDocument6 pagesD 850 - 99 - Rdg1mc05oueCasey RybackNo ratings yet
- S2AY21-22 Chem111E Chemistry For Engineers Syllabus - SummaryDocument5 pagesS2AY21-22 Chem111E Chemistry For Engineers Syllabus - SummaryShane Patrick MaddumaNo ratings yet
- Comparative and Contrastive Studies of Information Structure PDFDocument321 pagesComparative and Contrastive Studies of Information Structure PDFAle XanderNo ratings yet
- DN NDM Factor For Bearings Aricle 3Document3 pagesDN NDM Factor For Bearings Aricle 3Anand SinhaNo ratings yet
- Use of Permapol P3.1polymers and Epoxy Resins in The Formulation of Aerospace SealantsDocument6 pagesUse of Permapol P3.1polymers and Epoxy Resins in The Formulation of Aerospace Sealants이형주No ratings yet
- 05 Hardy 1951 The Developments in The Occlusal Patterns of Artificial TeethDocument15 pages05 Hardy 1951 The Developments in The Occlusal Patterns of Artificial Teethjorefe12No ratings yet
- Zebra TLP 2844Document2 pagesZebra TLP 2844Elyass DaddaNo ratings yet
- Auto Tune For InductionDocument2 pagesAuto Tune For InductiontoufikNo ratings yet
- Minimental ParkinsonDocument9 pagesMinimental ParkinsondquebradasNo ratings yet
- ps242 Smoke DetectorDocument2 pagesps242 Smoke DetectorrafaelNo ratings yet
- Thermo Scientific Ramsey Series 17: Belt Scale System For Conveyor Weighing of Bulk MaterialsDocument4 pagesThermo Scientific Ramsey Series 17: Belt Scale System For Conveyor Weighing of Bulk MaterialsFloyd Mejia GamarraNo ratings yet
- Unit 1Document67 pagesUnit 1sophieee19No ratings yet