You might also like
- E2 201: Information Theory (2019) Homework 4: Instructor: Himanshu TyagiDocument3 pagesE2 201: Information Theory (2019) Homework 4: Instructor: Himanshu Tyagis2211rNo ratings yet
- Integer-Valued Polynomials: LA Math Circle High School II Dillon Zhi October 11, 2015Document8 pagesInteger-Valued Polynomials: LA Math Circle High School II Dillon Zhi October 11, 2015Đặng Hoài BãoNo ratings yet
- Polynomial Problems: 0 0 N N I IDocument8 pagesPolynomial Problems: 0 0 N N I IAryan AbrolNo ratings yet
- Polynomials: 1 Roots of UnityDocument4 pagesPolynomials: 1 Roots of UnityFadil Habibi DanufaneNo ratings yet
- Shannon-Fano-Elias CodingDocument3 pagesShannon-Fano-Elias CodingKristina RančićNo ratings yet
- Homework 1Document4 pagesHomework 1Bilal Yousaf0% (1)
- Entropy 2Document3 pagesEntropy 2HarshaNo ratings yet
- SC222: Tutorial Sheet 2: N I N IDocument3 pagesSC222: Tutorial Sheet 2: N I N Irates0% (1)
- Shannon's Noiseless Coding TheoremDocument4 pagesShannon's Noiseless Coding TheoremSharmain QuNo ratings yet
- Report Lucas Slot Sebastian ZurDocument13 pagesReport Lucas Slot Sebastian ZurRani JibhekarNo ratings yet
- Reed-Solomon CodesDocument3 pagesReed-Solomon CodesMohsin RiazNo ratings yet
- 2011.1116.asgn2 CombinedDocument2 pages2011.1116.asgn2 CombinedDavid-Benjamin LimNo ratings yet
- Polynomials: Alexander RemorovDocument6 pagesPolynomials: Alexander Remorovmeoh eezaNo ratings yet
- EE5143 Tutorial1Document5 pagesEE5143 Tutorial1Sayan Rudra PalNo ratings yet
- Homework 2Document2 pagesHomework 2Laura MerchánNo ratings yet
- The 83rd William Lowell Putnam Mathematical Competition Saturday, December 3, 2022Document1 pageThe 83rd William Lowell Putnam Mathematical Competition Saturday, December 3, 2022Tanzil Mujeeb yacoobNo ratings yet
- Discrete Distributions: Bernoulli Random VariableDocument27 pagesDiscrete Distributions: Bernoulli Random VariableThapelo SebolaiNo ratings yet
- Quiz - 1: EC60128: Linear Algebra and Error Control Techniques Amitalok J. Budkuley (Amitalok@ece - Iitkgp.ac - In)Document5 pagesQuiz - 1: EC60128: Linear Algebra and Error Control Techniques Amitalok J. Budkuley (Amitalok@ece - Iitkgp.ac - In)sharan mouryaNo ratings yet
- Irreducibility of Polys in Z (X) - BMCDocument4 pagesIrreducibility of Polys in Z (X) - BMCJirayus JinapongNo ratings yet
- Qualifying Exam in Probability and Statistics PDFDocument11 pagesQualifying Exam in Probability and Statistics PDFYhael Jacinto Cru0% (1)
- Entropy and Huffman Codes: 1 2 N 1 2 N I IDocument15 pagesEntropy and Huffman Codes: 1 2 N 1 2 N I ITech InfoNo ratings yet
- 15ec54 PDFDocument56 pages15ec54 PDFpsych automobilesNo ratings yet
- E2 201: Information Theory (2018) Homework 1: Instructor: Himanshu TyagiDocument2 pagesE2 201: Information Theory (2018) Homework 1: Instructor: Himanshu TyagiNitin ChauhanNo ratings yet
- HW 2Document7 pagesHW 2Billy bobNo ratings yet
- Tutorial 4Document2 pagesTutorial 4Nancy NayakNo ratings yet
- Shannon's Theorems: Math and Science Summer Program 2020Document28 pagesShannon's Theorems: Math and Science Summer Program 2020Anh NguyenNo ratings yet
- NotesDocument32 pagesNotesGiane HiginoNo ratings yet
- Discrete Maths 103 124Document22 pagesDiscrete Maths 103 124Bamdeb DeyNo ratings yet
- Lecture 4 - September 16, 2014Document4 pagesLecture 4 - September 16, 2014as.2007 SNo ratings yet
- MAT 3633 Note 1 Lagrange Interpolation: 1.1 The Lagrange Interpolating PolynomialDocument16 pagesMAT 3633 Note 1 Lagrange Interpolation: 1.1 The Lagrange Interpolating PolynomialKuhu KoyaliyaNo ratings yet
- 1차 미적1Document4 pages1차 미적1jot1jot10311No ratings yet
- Lagrange IntepolationDocument10 pagesLagrange IntepolationceanilNo ratings yet
- Problems On Congruences and DivisibilityDocument3 pagesProblems On Congruences and DivisibilityCristian MoraruNo ratings yet
- Sixth Term Examination Papers 9470 Mathematics 2 Monday 17 June 2019Document12 pagesSixth Term Examination Papers 9470 Mathematics 2 Monday 17 June 2019Joydip SahaNo ratings yet
- Solutions To Information Theory Exercise Problems 1-4Document11 pagesSolutions To Information Theory Exercise Problems 1-4sodekoNo ratings yet
- Lecture 2: Gibb's, Data Processing and Fano's Inequalities: 2.1.1 Fundamental Limits in Information TheoryDocument6 pagesLecture 2: Gibb's, Data Processing and Fano's Inequalities: 2.1.1 Fundamental Limits in Information TheoryAbhishek PrakashNo ratings yet
- Coding Theory: Emmanuel AbbeDocument6 pagesCoding Theory: Emmanuel AbbeEvra LuleNo ratings yet
- ECEN 489 - Fall 2019 Assignment 4 - Channel Coding Problem Due: Friday, October 4, 2019 (In Class)Document2 pagesECEN 489 - Fall 2019 Assignment 4 - Channel Coding Problem Due: Friday, October 4, 2019 (In Class)AGMNo ratings yet
- A Polys and NT Holden Lee Lecture 13 EDocument15 pagesA Polys and NT Holden Lee Lecture 13 ELiu Yi JiaNo ratings yet
- Polynomials J Ainsworth Dec21Document4 pagesPolynomials J Ainsworth Dec21Jason Wenxuan MIAONo ratings yet
- Lagrange Interpolation Formula: Olympiad CornerDocument4 pagesLagrange Interpolation Formula: Olympiad CornerMaxim BogdanNo ratings yet
- Bstat Bmath Ugb 2018Document2 pagesBstat Bmath Ugb 2018A CardinayNo ratings yet
- Data Compression Arithmetic CodingDocument38 pagesData Compression Arithmetic Codingervaishu5342No ratings yet
- Probability S2010Document2 pagesProbability S2010acebagginsNo ratings yet
- Induction: (Chapter 4.2-4.4 of The BookDocument63 pagesInduction: (Chapter 4.2-4.4 of The BookPranay AnandNo ratings yet
- Discriptive Set Theory PDFDocument105 pagesDiscriptive Set Theory PDFHarrison Daka LukwesaNo ratings yet
- Spring 2021: Numerical Analysis Assignment 5 (Due Thursday April 22nd 10:00am)Document4 pagesSpring 2021: Numerical Analysis Assignment 5 (Due Thursday April 22nd 10:00am)Dibs ManiacNo ratings yet
- REsolução de ProblemaDocument2 pagesREsolução de ProblemaNei WinchesterNo ratings yet
- MIT18 650F16 PSet1Document4 pagesMIT18 650F16 PSet1Mithilesh KumarNo ratings yet
- Midterm 2015 SolDocument9 pagesMidterm 2015 SolAlexanderNo ratings yet
- PolynomialsDocument6 pagesPolynomialsToánHọcNo ratings yet
- Discrete Mathematics and Probability TheoryDocument6 pagesDiscrete Mathematics and Probability Theorychege ng'ang'aNo ratings yet
- The 69th William Lowell Putnam Mathematical Competition Saturday, December 6, 2008Document1 pageThe 69th William Lowell Putnam Mathematical Competition Saturday, December 6, 2008Sarthak MishraNo ratings yet
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesFrom EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesNo ratings yet
- The Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64From EverandThe Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64No ratings yet
- A Course of Mathematics for Engineerings and Scientists: Volume 5From EverandA Course of Mathematics for Engineerings and Scientists: Volume 5No ratings yet
- Lec2 - Data Compression PDFDocument9 pagesLec2 - Data Compression PDFrayanmatNo ratings yet
- Lec3 - Probability PDFDocument13 pagesLec3 - Probability PDFrayanmatNo ratings yet
- Lec4 - Probability PDFDocument18 pagesLec4 - Probability PDFrayanmatNo ratings yet
- Information and Digital Transmission: Haykin Chapter 9 Carlson Chapter 16Document27 pagesInformation and Digital Transmission: Haykin Chapter 9 Carlson Chapter 16rayanmatNo ratings yet
- An Introduction To Information Theory and Entropy: Tom Carter CSU StanislausDocument139 pagesAn Introduction To Information Theory and Entropy: Tom Carter CSU StanislausAchuthanand MukundanNo ratings yet
- Information Theory: Capter 1, The Elements of Information Theory, 2 Edition byDocument8 pagesInformation Theory: Capter 1, The Elements of Information Theory, 2 Edition byrayanmatNo ratings yet
- Course: Master's Program - Department of Electrical EngineeringDocument2 pagesCourse: Master's Program - Department of Electrical EngineeringrayanmatNo ratings yet
- Information Theory-Homework Exercises: 1 Entropy, Source CodingDocument18 pagesInformation Theory-Homework Exercises: 1 Entropy, Source CodingrayanmatNo ratings yet
- Exercises 09Document51 pagesExercises 09Abhishek PrakashNo ratings yet
- Course: Master's Program - Department of Electrical EngineeringDocument2 pagesCourse: Master's Program - Department of Electrical EngineeringrayanmatNo ratings yet
- Format For A Review Paper (Attach To F204)Document1 pageFormat For A Review Paper (Attach To F204)Ankita BhardwajNo ratings yet
- Format For A Review Paper (Attach To F204)Document1 pageFormat For A Review Paper (Attach To F204)Ankita BhardwajNo ratings yet
- Format For A Review Paper (Attach To F204)Document1 pageFormat For A Review Paper (Attach To F204)Ankita BhardwajNo ratings yet
- An Introduction To Information Theory and Entropy: Tom Carter CSU StanislausDocument139 pagesAn Introduction To Information Theory and Entropy: Tom Carter CSU StanislausAchuthanand MukundanNo ratings yet
- Exercises 09Document51 pagesExercises 09Abhishek PrakashNo ratings yet
- Exercises 09Document51 pagesExercises 09Abhishek PrakashNo ratings yet
- Information Theory-Homework Exercises: 1 Entropy, Source CodingDocument18 pagesInformation Theory-Homework Exercises: 1 Entropy, Source CodingrayanmatNo ratings yet
- An Introduction To Information Theory and Entropy: Tom Carter CSU StanislausDocument139 pagesAn Introduction To Information Theory and Entropy: Tom Carter CSU StanislausAchuthanand MukundanNo ratings yet
- Course: Master's Program - Department of Electrical EngineeringDocument2 pagesCourse: Master's Program - Department of Electrical EngineeringrayanmatNo ratings yet
- Machine Learning Online Bootcamp Beginners Track CurriculumDocument9 pagesMachine Learning Online Bootcamp Beginners Track CurriculumیاسرانسNo ratings yet
- 1803 08823 PDFDocument122 pages1803 08823 PDFmtl171No ratings yet
- Nursing Research Chapter 4: Types of Research ReportDocument5 pagesNursing Research Chapter 4: Types of Research ReportSupriadi74No ratings yet
- Chapter 3. Articulating Performance Standards Into Competencies and Learning TargetsDocument2 pagesChapter 3. Articulating Performance Standards Into Competencies and Learning TargetsSharmaine Tuliao100% (2)
- Problem Solving Involving Variance and Standard DeviationDocument11 pagesProblem Solving Involving Variance and Standard DeviationJasmine AleliNo ratings yet
- Machine Learning NotesDocument8 pagesMachine Learning NotesAnkit Shaw100% (1)
- Dna of Roulette (E5) PDFDocument16 pagesDna of Roulette (E5) PDFHENRY TORRES100% (1)
- Shivani Pandey TSFDocument32 pagesShivani Pandey TSFShivich10100% (1)
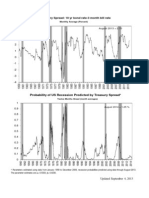
- Probability of US Recession Predicted by Treasury SpreadDocument1 pageProbability of US Recession Predicted by Treasury Spreadmustafa-ahmedNo ratings yet
- Chapter 16Document37 pagesChapter 16Hassan SheikhNo ratings yet
- MBA Business Analytics IBMDocument119 pagesMBA Business Analytics IBMsimhamsidduNo ratings yet
- CHP 3 Notes, GujaratiDocument4 pagesCHP 3 Notes, GujaratiDiwakar ChakrabortyNo ratings yet
- Multilateration AssignmentDocument2 pagesMultilateration AssignmentSaniya MaheshwariNo ratings yet
- Stochastic Processes 2Document11 pagesStochastic Processes 2Seham RaheelNo ratings yet
- Where To Study Maths UKDocument8 pagesWhere To Study Maths UKMike AntonyNo ratings yet
- Journal of Applied Ecology - 2004 - Stander - Spoor Counts As Indices of Large Carnivore Populations The RelationshipDocument8 pagesJournal of Applied Ecology - 2004 - Stander - Spoor Counts As Indices of Large Carnivore Populations The Relationshiphunting ezioNo ratings yet
- Sosi Proposal ResearchDocument17 pagesSosi Proposal ResearchBereket K.ChubetaNo ratings yet
- Institute of Graduate Studies: Reference: Hypothesis Testing by CHRISTINA MAJASKIDocument3 pagesInstitute of Graduate Studies: Reference: Hypothesis Testing by CHRISTINA MAJASKIAngelica OrbizoNo ratings yet
- 4 6003574465387038522 PDFDocument14 pages4 6003574465387038522 PDFYisihak HabteNo ratings yet
- Eligibility of Village Fund Direct Cash Assistance Recipients Using Artificial Neural NetworkDocument8 pagesEligibility of Village Fund Direct Cash Assistance Recipients Using Artificial Neural NetworkIAES IJAINo ratings yet
- Running Head: HR ANALYTICS 1Document7 pagesRunning Head: HR ANALYTICS 1DenizNo ratings yet
- Math 1 - Course OutlineDocument2 pagesMath 1 - Course OutlineJennifer VeloriaNo ratings yet
- Angeles University FoundationDocument26 pagesAngeles University FoundationRance LacsonNo ratings yet
- Syllabus 463 2016Document2 pagesSyllabus 463 2016M PNo ratings yet
- Andhra University SyllabusDocument59 pagesAndhra University SyllabusKalikumarNo ratings yet
- Amreen HandicraftDocument66 pagesAmreen Handicraftajay sharmaNo ratings yet
- All 12 Assignment AnswersDocument5 pagesAll 12 Assignment AnswersShafici CqadirNo ratings yet
- Why Look For BusinessDocument5 pagesWhy Look For BusinessA'del JummaNo ratings yet
- Young 2003 - Enhancing Learning Outcomes - The Effects of Instructional Technology, Learning Styles, Instructional Methods and Studen BehaviorDocument14 pagesYoung 2003 - Enhancing Learning Outcomes - The Effects of Instructional Technology, Learning Styles, Instructional Methods and Studen BehaviorkambudurNo ratings yet
- STAT512 Split Plot DesignDocument7 pagesSTAT512 Split Plot DesignMeenakshi SahuNo ratings yet