You might also like
- Stochastic Analysis in Finance and InsuranceDocument16 pagesStochastic Analysis in Finance and InsurancepostscriptNo ratings yet
- Dumas - Fleming - Whaley - 95 - Loval Vol TestsDocument31 pagesDumas - Fleming - Whaley - 95 - Loval Vol TestsVeeken ChaglassianNo ratings yet
- Testing Geometric Brownian Motion: An Analytical Look at The Black Scholes Option Pricing ModelDocument32 pagesTesting Geometric Brownian Motion: An Analytical Look at The Black Scholes Option Pricing Modelatoi123No ratings yet
- Anticipated Information Releases Reflected in Call Option PricesDocument24 pagesAnticipated Information Releases Reflected in Call Option PricesZhang PeilinNo ratings yet
- Risk-Neutral Option Pricing For Log-Uniform: Z Z and F B. HDocument44 pagesRisk-Neutral Option Pricing For Log-Uniform: Z Z and F B. Hstehbar9570No ratings yet
- Pricing Options On Commodity Futures: The Role of Weather and StorageDocument49 pagesPricing Options On Commodity Futures: The Role of Weather and Storageultrags424685No ratings yet
- 1985 (Anderson)Document18 pages1985 (Anderson)George máximoNo ratings yet
- Do Option Markets Correctlyprice The Probabilities of Movement of The Underlying Asset?Document44 pagesDo Option Markets Correctlyprice The Probabilities of Movement of The Underlying Asset?5ty5No ratings yet
- Implications of Rational Inattention (Sims, JME, 2003)Document26 pagesImplications of Rational Inattention (Sims, JME, 2003)Dominika OSNo ratings yet
- Garven OptionsDocument17 pagesGarven OptionsJoe ZhouNo ratings yet
- Quantitative Methods 2: ECON 20003Document26 pagesQuantitative Methods 2: ECON 20003ninglu wanNo ratings yet
- General Disclaimer One or More of The Following Statements May Affect This DocumentDocument17 pagesGeneral Disclaimer One or More of The Following Statements May Affect This DocumentLEMON GAGALINo ratings yet
- Cox Ross 1976 - The Valuation of Options For Alternative Stochastic ProcessesDocument22 pagesCox Ross 1976 - The Valuation of Options For Alternative Stochastic ProcessesxeperiaNo ratings yet
- Copulas Bivariate Option PricingDocument14 pagesCopulas Bivariate Option PricingRenan CintraNo ratings yet
- Kennedy 01Document39 pagesKennedy 01Mayra GarcíaRodríguezNo ratings yet
- The Interval Market Model in Mathematical Finance: Game-Theoretic MethodsFrom EverandThe Interval Market Model in Mathematical Finance: Game-Theoretic MethodsNo ratings yet
- Reconciling Alternative Estimates of Elasticity of Substitution (Berndt1976)Document11 pagesReconciling Alternative Estimates of Elasticity of Substitution (Berndt1976)Franco BailonNo ratings yet
- Archaeological Applications of Kernel Density Estimates PDFDocument8 pagesArchaeological Applications of Kernel Density Estimates PDFGustavo LuceroNo ratings yet
- Risk Neutral Densities A Review PDFDocument61 pagesRisk Neutral Densities A Review PDFAnonymous 3NPu0MKNo ratings yet
- Asymmetric Power Distribution: Theory and Applications To Risk MeasurementDocument31 pagesAsymmetric Power Distribution: Theory and Applications To Risk Measurementgado semaNo ratings yet
- Implied Volatility - Financial Analysts JournalDocument14 pagesImplied Volatility - Financial Analysts JournalRaymon PrakashNo ratings yet
- Estimation of The Generalized Extreme Value Distribution by The Method of Probability Weighted MomentsDocument11 pagesEstimation of The Generalized Extreme Value Distribution by The Method of Probability Weighted MomentsTesis CyS UNCNo ratings yet
- Testing Null of Stationarity Against Unit RootDocument20 pagesTesting Null of Stationarity Against Unit RootMarcos PoloNo ratings yet
- 1993-00 A Closed-Form Solution For Options With Stochastic Volatility With Applications To Bond and Currency Options - HestonDocument17 pages1993-00 A Closed-Form Solution For Options With Stochastic Volatility With Applications To Bond and Currency Options - Hestonrdouglas2002No ratings yet
- Saddlepoint Methods For Option Pricing: Peter CarrDocument13 pagesSaddlepoint Methods For Option Pricing: Peter CarrfrolloosNo ratings yet
- Unique Option Pricing Measure With Neither Dynamic Hedging Nor Complete MarketsDocument4 pagesUnique Option Pricing Measure With Neither Dynamic Hedging Nor Complete MarketsgliptakNo ratings yet
- Pricing With SmileDocument4 pagesPricing With Smilekufeutebg100% (1)
- Noarbitrage Eq To Risk Neutral ExistanceDocument46 pagesNoarbitrage Eq To Risk Neutral ExistanceJack SmithNo ratings yet
- Malnutrition in The WorldDocument11 pagesMalnutrition in The WorldReginaCristineCabudlanMahinayNo ratings yet
- Sloan School of Mu Magmrnf and Lkpartment of Economics. M.I.T., Cambridge, Alms. 02139. U.S.ADocument28 pagesSloan School of Mu Magmrnf and Lkpartment of Economics. M.I.T., Cambridge, Alms. 02139. U.S.AAndreas KarasNo ratings yet
- Statistical Scale Space MethodsDocument30 pagesStatistical Scale Space MethodsJon TheodoropoulosNo ratings yet
- Stationary and Related Stochastic Processes: Sample Function Properties and Their ApplicationsFrom EverandStationary and Related Stochastic Processes: Sample Function Properties and Their ApplicationsRating: 4 out of 5 stars4/5 (2)
- Black Scholes Pricing ModelDocument11 pagesBlack Scholes Pricing ModelIsm KurNo ratings yet
- Batten 2005Document12 pagesBatten 2005Graphix GurujiNo ratings yet
- Griffiths & Tenenbaum - Reconciling Intuition and ProbabilityDocument6 pagesGriffiths & Tenenbaum - Reconciling Intuition and ProbabilityMatCult100% (1)
- Application of Copulas in Geostatistics: Claus P. Haslauer, Jing Li, and Andr As B ArdossyDocument10 pagesApplication of Copulas in Geostatistics: Claus P. Haslauer, Jing Li, and Andr As B Ardossyseyyed81No ratings yet
- Unit 18Document12 pagesUnit 18Harsh kumar MeerutNo ratings yet
- Block 7Document34 pagesBlock 7Harsh kumar MeerutNo ratings yet
- Approximate Option Valuation For Arbitrary Stochastic ProcessesDocument23 pagesApproximate Option Valuation For Arbitrary Stochastic ProcessesZhang PeilinNo ratings yet
- The Relation Between Implied and Realized VolatilityDocument26 pagesThe Relation Between Implied and Realized VolatilitySo LokNo ratings yet
- Singular Perturbations in Option Pricing: SIAM Journal On Applied Mathematics June 2003Document19 pagesSingular Perturbations in Option Pricing: SIAM Journal On Applied Mathematics June 2003GiktonNo ratings yet
- Kim Shephard Chib 98Document33 pagesKim Shephard Chib 98ALVARO MIGUEL JESUS RODRIGUEZ SAENZNo ratings yet
- A 2020-Bej1171Document32 pagesA 2020-Bej1171Meriem PearlNo ratings yet
- Unit 3 - Framework For InferenceDocument6 pagesUnit 3 - Framework For InferenceCletus Sikwanda100% (1)
- Models: Comparative Study Between An Islamic and A Conventional Index (SP Sharia VS SP 500)Document5 pagesModels: Comparative Study Between An Islamic and A Conventional Index (SP Sharia VS SP 500)Tanzeel Mustafa RanaNo ratings yet
- Disproving Common Probability and Statistics Misconceptions with CounterexamplesDocument12 pagesDisproving Common Probability and Statistics Misconceptions with CounterexamplesRemi A. SamadNo ratings yet
- Mossin Econometrica1966Document16 pagesMossin Econometrica1966Sebastián IsaíasNo ratings yet
- Nonparametric tests for alternatives with an unknown peak locationDocument14 pagesNonparametric tests for alternatives with an unknown peak locationJames Opoku-AgyapongNo ratings yet
- Randomness and CoincidenceDocument6 pagesRandomness and CoincidenceFrank TursackNo ratings yet
- Pricing KernelsDocument44 pagesPricing Kernelspmenaria5126No ratings yet
- Gap PDFDocument13 pagesGap PDFAdeliton DelkNo ratings yet
- Mathematical Models of Orebodies: Is inDocument4 pagesMathematical Models of Orebodies: Is inJose Antonio VillalobosNo ratings yet
- Structural Properties of Commodity Futures Term Structures and Their Implications For Basic Trading StrategiesDocument29 pagesStructural Properties of Commodity Futures Term Structures and Their Implications For Basic Trading StrategiesbboyvnNo ratings yet
- ERIKSSON PricingPathDependentOptionsDocument24 pagesERIKSSON PricingPathDependentOptionsLameuneNo ratings yet
- When Portfolios Well Diversified?: Will Mean-Variance EfficientDocument25 pagesWhen Portfolios Well Diversified?: Will Mean-Variance EfficientelgaNo ratings yet
- Approximate Option ValuationDocument23 pagesApproximate Option Valuationgarav-karam-2731No ratings yet
- Maximum Likelihood Estimation of Stochastic Volatility ModelsDocument40 pagesMaximum Likelihood Estimation of Stochastic Volatility ModelssandeepvempatiNo ratings yet
- An Adjusted Boxplot For Skewed Distributions: M. Hubert, E. VandervierenDocument16 pagesAn Adjusted Boxplot For Skewed Distributions: M. Hubert, E. VandervierenRaul Hernan Villacorta GarciaNo ratings yet
- Dupire - Pricing With A Smile (1994)Document10 pagesDupire - Pricing With A Smile (1994)logos022110No ratings yet
- Complete Market ModelsDocument16 pagesComplete Market Modelsmeko1986No ratings yet
- Murakami QuotesDocument2 pagesMurakami QuotesVeeken ChaglassianNo ratings yet
- Default Risk as an OptionDocument5 pagesDefault Risk as an OptionVeeken ChaglassianNo ratings yet
- Teaching Note 98-01: Closed-Form American Call Option Pricing: Roll-Geske-WhaleyDocument8 pagesTeaching Note 98-01: Closed-Form American Call Option Pricing: Roll-Geske-WhaleyVeeken ChaglassianNo ratings yet
- Estimation of Key in Digital Music Recordings: MSC Computer Science Project ReportDocument80 pagesEstimation of Key in Digital Music Recordings: MSC Computer Science Project ReportVeeken ChaglassianNo ratings yet
- Approximation of American Option ValuesDocument4 pagesApproximation of American Option ValuesVeeken ChaglassianNo ratings yet
- Binomial BSconvergenceDocument10 pagesBinomial BSconvergenceVeeken ChaglassianNo ratings yet
- Teaching Note 96-02: Risk Neutral Pricing in Discrete TimeDocument4 pagesTeaching Note 96-02: Risk Neutral Pricing in Discrete TimeVeeken ChaglassianNo ratings yet
- Teaching Note 00-04: Girsanov'S Theorem in Derivative PricingDocument16 pagesTeaching Note 00-04: Girsanov'S Theorem in Derivative PricingVeeken ChaglassianNo ratings yet
- Topics: Convexity Immunization by Matching Convexity in Addition To DurationDocument8 pagesTopics: Convexity Immunization by Matching Convexity in Addition To DurationVeeken ChaglassianNo ratings yet
- Teaching Note 97-08: Pricing and Valuation of Commodity SwapsDocument13 pagesTeaching Note 97-08: Pricing and Valuation of Commodity SwapsVeeken ChaglassianNo ratings yet
- Stats 242: Algorithmic Trading and Quantitative Strategies Summer 2011Document9 pagesStats 242: Algorithmic Trading and Quantitative Strategies Summer 2011Veeken ChaglassianNo ratings yet
- L4 ImmunizationDocument11 pagesL4 ImmunizationVeeken ChaglassianNo ratings yet
- Overviewof Option Strategies 1Document6 pagesOverviewof Option Strategies 1Veeken ChaglassianNo ratings yet
- Tn99-01: Solving Linear Equations in Excel: Version Date: February 3, 1999 C:/Class/TN99-01.wpdDocument4 pagesTn99-01: Solving Linear Equations in Excel: Version Date: February 3, 1999 C:/Class/TN99-01.wpdVeeken ChaglassianNo ratings yet
- Econophysics Stock Returns PDFDocument8 pagesEconophysics Stock Returns PDFVeeken ChaglassianNo ratings yet
- Teaching Note 00-01: Linear Homogeneity, Euler'S Rule, The Black-Scholes Model, and An Application To Forward Start OptionsDocument6 pagesTeaching Note 00-01: Linear Homogeneity, Euler'S Rule, The Black-Scholes Model, and An Application To Forward Start OptionsVeeken ChaglassianNo ratings yet
- Data Mining in Finance: B20.3355 / B90.3355: Intensive Methods For Financial Modeling and Data AnalysisDocument14 pagesData Mining in Finance: B20.3355 / B90.3355: Intensive Methods For Financial Modeling and Data AnalysisVeeken ChaglassianNo ratings yet
- The Vol Smile Problem - FX FocusDocument5 pagesThe Vol Smile Problem - FX FocusVeeken ChaglassianNo ratings yet
- Smile Dynamics II: Option PricingDocument7 pagesSmile Dynamics II: Option PricingVeeken ChaglassianNo ratings yet
- Lecture-10 Regression TreeDocument7 pagesLecture-10 Regression Treetmtb04No ratings yet
- Poteshman 911 Insider Trading PaperDocument24 pagesPoteshman 911 Insider Trading PaperCarlos RodriguezNo ratings yet
- A Discrete Question (Divs)Document2 pagesA Discrete Question (Divs)Veeken ChaglassianNo ratings yet
- Cutting Edge Dividend AdjustmentDocument2 pagesCutting Edge Dividend AdjustmentVeeken Chaglassian100% (1)
- New Products, New Risks: Equity DerivativesDocument4 pagesNew Products, New Risks: Equity DerivativesVeeken ChaglassianNo ratings yet
- Economics of Finance (U6022) Homework Assignment #2 Tracking A Hedged Options Portfolio Over Time Due: October 23, 2002Document3 pagesEconomics of Finance (U6022) Homework Assignment #2 Tracking A Hedged Options Portfolio Over Time Due: October 23, 2002Veeken ChaglassianNo ratings yet
- Risk - Skew - Fits (Param Used in Spufalator)Document4 pagesRisk - Skew - Fits (Param Used in Spufalator)Veeken ChaglassianNo ratings yet
- Basic BS PDE Calls PutsDocument5 pagesBasic BS PDE Calls PutsVeeken ChaglassianNo ratings yet
- Bachelier To BSDocument1 pageBachelier To BSveeken100% (1)
- Credit Quant SightDocument26 pagesCredit Quant SightmarioturriNo ratings yet
- Book of GreeksDocument135 pagesBook of GreeksNicolas Lefevre-LaumonierNo ratings yet
- Hull OFOD10e MultipleChoice Questions and Answers Ch20Document6 pagesHull OFOD10e MultipleChoice Questions and Answers Ch20Kevin Molly KamrathNo ratings yet
- Nat West Case StudyDocument4 pagesNat West Case StudyMuzna MumtazNo ratings yet
- Local Volatility SurfaceDocument1 pageLocal Volatility SurfaceRajNo ratings yet
- Mancini - Advanced Topics in Financial Econometrics (Swiss) PDFDocument5 pagesMancini - Advanced Topics in Financial Econometrics (Swiss) PDFInvestNo ratings yet
- The Derivation of Black Scholes Model (Ip)Document75 pagesThe Derivation of Black Scholes Model (Ip)Jeevan Kumar RajahNo ratings yet
- FX Derivatives TradingDocument4 pagesFX Derivatives TradingMarcos Avello IbarraNo ratings yet
- The Vol Smile Problem - FX FocusDocument5 pagesThe Vol Smile Problem - FX FocusVeeken ChaglassianNo ratings yet
- Option Pricing Under Skewness and Kurtosis Using A Cornish Fisher ExpansionDocument22 pagesOption Pricing Under Skewness and Kurtosis Using A Cornish Fisher ExpansionUtkarsh DalmiaNo ratings yet
- FX Options FundamentalsDocument52 pagesFX Options Fundamentalspb024No ratings yet
- Ishares US ETFs - Dividends and Implied Volatility Surfaces ParametersDocument2 pagesIshares US ETFs - Dividends and Implied Volatility Surfaces ParametersQ.M.S Advisors LLCNo ratings yet
- Benaim, Dodgson, Kainth - An Arbitrage-Free Method For Smile Extrapolation - 2009Document10 pagesBenaim, Dodgson, Kainth - An Arbitrage-Free Method For Smile Extrapolation - 2009Slavi GeorgievNo ratings yet
- Foreign Exchange Option Pricing A Practitioners Guide by Iain J ClarkDocument8 pagesForeign Exchange Option Pricing A Practitioners Guide by Iain J ClarkSTARK WOLFYRENo ratings yet
- Good OneDocument58 pagesGood OneSandy TerpopeNo ratings yet
- Chap 20 Volatility SmilesDocument37 pagesChap 20 Volatility SmilesnurfakhiraariffinNo ratings yet
- Samples and InstructionsDocument479 pagesSamples and InstructionsWunmi OlaNo ratings yet
- Nick Stavrou Tutorial Questions 2015Document2 pagesNick Stavrou Tutorial Questions 2015Trang PhanNo ratings yet
- Save up to £500 at Global Derivatives 20th AnniversaryDocument14 pagesSave up to £500 at Global Derivatives 20th AnniversaryccaNo ratings yet
- Implied Vol SurfaceDocument10 pagesImplied Vol SurfaceHenry ChowNo ratings yet
- BofA - The EEMEA FX Strategist Higher Oil More EEMEA FX Weakness - 20230926Document19 pagesBofA - The EEMEA FX Strategist Higher Oil More EEMEA FX Weakness - 20230926Sofia Franco100% (1)
- Andrea RoncoroniDocument27 pagesAndrea RoncoroniLameuneNo ratings yet
- A Backward Monte Carlo Approach To Exotic Option Pricing: Cambridge University Press 2017Document42 pagesA Backward Monte Carlo Approach To Exotic Option Pricing: Cambridge University Press 2017Airlangga TantraNo ratings yet
- 09 - Quasi Gaussian Model MathFinance 2017Document33 pages09 - Quasi Gaussian Model MathFinance 2017shih_kaichihNo ratings yet
- S&P 1000 Index - Dividends and Implied Volatility Surfaces ParametersDocument8 pagesS&P 1000 Index - Dividends and Implied Volatility Surfaces ParametersQ.M.S Advisors LLCNo ratings yet
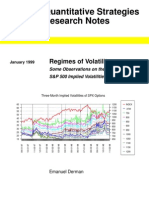
- Regimes of Volatility - DermanDocument30 pagesRegimes of Volatility - Dermancca100% (2)
- Curriculum Vita of Dilip B. MadanDocument17 pagesCurriculum Vita of Dilip B. MadanyinnancyNo ratings yet
- BTC OptionsDocument15 pagesBTC OptionsJoana CostaNo ratings yet
- Investing in VolDocument16 pagesInvesting in VolcookeNo ratings yet
- 2-Valuation of Volatility Derivatives As An Inverse ProblemDocument31 pages2-Valuation of Volatility Derivatives As An Inverse ProblemjeromeNo ratings yet