You might also like
- LFJ All OrdersDocument195 pagesLFJ All Orderskate jackNo ratings yet
- Folktalesofkeral 00 MenoDocument124 pagesFolktalesofkeral 00 Menoreena sudhirNo ratings yet
- Data Structures With C++Document169 pagesData Structures With C++Rachna BhatnagarNo ratings yet
- Partitioning Oracle Sources in PowerCenterDocument12 pagesPartitioning Oracle Sources in PowerCenterSergio Eduardo Pérez TorresNo ratings yet
- 22 Dec OralDocument4 pages22 Dec OralAmanNo ratings yet
- Systolic Algorithm Design: Hardware Merge Sort and Spatial FPGA Cell Placement Case StudiesDocument23 pagesSystolic Algorithm Design: Hardware Merge Sort and Spatial FPGA Cell Placement Case StudiesAbhishek SaxenaNo ratings yet
- High-performance slot map container for CDocument6 pagesHigh-performance slot map container for CKinjalKishorNo ratings yet
- Informatica Interview QuestionsDocument5 pagesInformatica Interview QuestionsPreethaNo ratings yet
- Digital Design Using VHDL: Topic: Huffman Decoder Using VerilogDocument14 pagesDigital Design Using VHDL: Topic: Huffman Decoder Using VerilogTùng Lâm VũNo ratings yet
- Variables and Data Storage - C Interview Questions and AnswersDocument6 pagesVariables and Data Storage - C Interview Questions and AnswersANUSHA SINGH V HNo ratings yet
- InformaticaDocument70 pagesInformaticaVenkataramana Sama100% (1)
- ML InterviewDocument17 pagesML InterviewMarvel MoviesNo ratings yet
- DC AssignmentDocument3 pagesDC AssignmentChandra SinghNo ratings yet
- Chapter 3 - 大数据管理Document38 pagesChapter 3 - 大数据管理gs68295No ratings yet
- Ab Initio QuestionsDocument14 pagesAb Initio QuestionsNagarjuna TammisettiNo ratings yet
- A Interview Questions and AnswersDocument34 pagesA Interview Questions and Answersmallekrishna123No ratings yet
- Oracle Performance Tuning Interview QuestionsDocument7 pagesOracle Performance Tuning Interview QuestionsJean Jacques Nkuitche NzokouNo ratings yet
- Data Stage PDFDocument37 pagesData Stage PDFpappujaiswalNo ratings yet
- 100+ Data Analyst Interview QnA PDFDocument19 pages100+ Data Analyst Interview QnA PDFArun PanneerNo ratings yet
- cs301 FAQDocument9 pagescs301 FAQpirah chhachharNo ratings yet
- Informatica PerformanceDocument4 pagesInformatica PerformanceVikas SinhaNo ratings yet
- Memory and ClassificationDocument8 pagesMemory and Classificationsingh7863No ratings yet
- 6 - Join Techniques and Performance EvaluationDocument33 pages6 - Join Techniques and Performance EvaluationHamid MahmoodNo ratings yet
- Answers 4Document91 pagesAnswers 4Miguel Angel HernandezNo ratings yet
- A Interview Questions and Answers - Cool InterviewDocument30 pagesA Interview Questions and Answers - Cool Interviewcm_ram847118100% (16)
- Citadel White PaperDocument13 pagesCitadel White PaperdsffgdsgsgasfgasfgNo ratings yet
- DP 900 PracticeDocument11 pagesDP 900 PracticeTTNo ratings yet
- ExadataDocument4 pagesExadataSurender MarthaNo ratings yet
- ASCII ProtocolDocument97 pagesASCII ProtocolelricloboNo ratings yet
- Data Mapper Guide-1.6.2Document108 pagesData Mapper Guide-1.6.2Richard AbrahamNo ratings yet
- SQL NotesDocument62 pagesSQL NotesWatsh Rajneesh100% (8)
- Netezza Fundamentals For DevelopersDocument55 pagesNetezza Fundamentals For Developerslokeshkansal100% (1)
- Module 2Document19 pagesModule 2a45 asNo ratings yet
- Operating System: COPE/Technical Test/Interview/Database Questions & AnswersDocument25 pagesOperating System: COPE/Technical Test/Interview/Database Questions & AnswersVasu DevanNo ratings yet
- Ans: A: 1. Describe The Following: Dimensional ModelDocument8 pagesAns: A: 1. Describe The Following: Dimensional ModelAnil KumarNo ratings yet
- Shift Register: Adebiyi Ismail AdebayoDocument15 pagesShift Register: Adebiyi Ismail AdebayoAdebiyi Ismail RaitoNo ratings yet
- 1-Program Design and AnalysisDocument6 pages1-Program Design and AnalysisUmer AftabNo ratings yet
- Netezza Fundamentals PDFDocument60 pagesNetezza Fundamentals PDFraghutejharishNo ratings yet
- Datasatage QuestionsDocument5 pagesDatasatage QuestionsMUNI muniraja0303No ratings yet
- Major Differences Between C and Java Programming LanguagesDocument31 pagesMajor Differences Between C and Java Programming LanguagesNavin Andrew Prince100% (1)
- An82156 001-82156 0F VDocument115 pagesAn82156 001-82156 0F Vandrej2112No ratings yet
- Structured P2P Networks by Example Chord, DKS (N, K, F) : Jun QinDocument11 pagesStructured P2P Networks by Example Chord, DKS (N, K, F) : Jun Qinsorin092004No ratings yet
- Machine Learning & Grid TechnologyDocument3 pagesMachine Learning & Grid TechnologyCee MabNo ratings yet
- Data Modeling For Data Warehouses: Davor GornikDocument15 pagesData Modeling For Data Warehouses: Davor Gornikbudi.hw748No ratings yet
- Wide Area ComputingDocument46 pagesWide Area ComputingAlexandros ValavanisNo ratings yet
- Understanding MemoryDocument23 pagesUnderstanding MemoryAshok KumarNo ratings yet
- Loader Loads Programs From Executable Files Into MemoryDocument4 pagesLoader Loads Programs From Executable Files Into Memoryrajchaurasia143No ratings yet
- Postgres PerformanceDocument13 pagesPostgres PerformancePhani PNo ratings yet
- Design For PerformanceDocument34 pagesDesign For Performancec0de517e.blogspot.com100% (1)
- Data Structures Interview Questions Set - 1Document3 pagesData Structures Interview Questions Set - 1Swastik AcharyaNo ratings yet
- Essential Algorithms: A Practical Approach to Computer AlgorithmsFrom EverandEssential Algorithms: A Practical Approach to Computer AlgorithmsRating: 4.5 out of 5 stars4.5/5 (2)
- Pointers in C Programming: A Modern Approach to Memory Management, Recursive Data Structures, Strings, and ArraysFrom EverandPointers in C Programming: A Modern Approach to Memory Management, Recursive Data Structures, Strings, and ArraysNo ratings yet
- Magic Data: Part 1 - Harnessing the Power of Algorithms and StructuresFrom EverandMagic Data: Part 1 - Harnessing the Power of Algorithms and StructuresNo ratings yet
- “Information Systems Unraveled: Exploring the Core Concepts”: GoodMan, #1From Everand“Information Systems Unraveled: Exploring the Core Concepts”: GoodMan, #1No ratings yet
- Build Your Own Distributed Compilation Cluster: A Practical WalkthroughFrom EverandBuild Your Own Distributed Compilation Cluster: A Practical WalkthroughNo ratings yet
- Preliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960From EverandPreliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960No ratings yet
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- I. Project Initiation Activities:: Diacenco Margareta, FAF-171 Ivanova Anastasia, FAF-172 Țurcanu Ana, FAF-171Document5 pagesI. Project Initiation Activities:: Diacenco Margareta, FAF-171 Ivanova Anastasia, FAF-172 Țurcanu Ana, FAF-171Anastasia WagnerNo ratings yet
- Example Bilet MathsDocument9 pagesExample Bilet MathsAnastasia WagnerNo ratings yet
- Edge Computing: Moving Computation Closer to Data SourcesDocument17 pagesEdge Computing: Moving Computation Closer to Data SourcesAnastasia WagnerNo ratings yet
- Launcher PDFDocument2 pagesLauncher PDFAnastasia WagnerNo ratings yet
- Guitar Lessons: Offered by A Music School GraduateDocument1 pageGuitar Lessons: Offered by A Music School GraduateAnastasia WagnerNo ratings yet
- LinAlg CompleteDocument331 pagesLinAlg Completes0uizNo ratings yet
- CPA Review Module on Accounting Standards and RegulationDocument13 pagesCPA Review Module on Accounting Standards and RegulationLuiNo ratings yet
- Script of Cca Eim EditedDocument4 pagesScript of Cca Eim EditedMhen Maugan100% (1)
- CV Jubilee Bubala Environmental SpecialistDocument4 pagesCV Jubilee Bubala Environmental SpecialistNomayi100% (2)
- Apparent Dip PDFDocument2 pagesApparent Dip PDFanon_114803412No ratings yet
- Safety Data Sheet: Flexa SoftDocument9 pagesSafety Data Sheet: Flexa SoftSercan şahinkayaNo ratings yet
- Measure Science AccuratelyDocument41 pagesMeasure Science AccuratelyAnthony QuanNo ratings yet
- Axial Centrifugal FansDocument15 pagesAxial Centrifugal FansAhsan JavedNo ratings yet
- Sunday School Lesson Activity 219 Moses Builds A Tablernacle in The Wilderness - Printable 3D Model KitDocument17 pagesSunday School Lesson Activity 219 Moses Builds A Tablernacle in The Wilderness - Printable 3D Model Kitmcontrerasseitz3193No ratings yet
- Design Report For Proposed 3storied ResidentialbuildingDocument35 pagesDesign Report For Proposed 3storied ResidentialbuildingMohamed RinosNo ratings yet
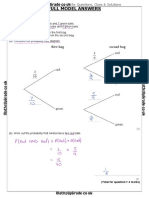
- Probability Tree Diagrams Solutions Mathsupgrade Co UkDocument10 pagesProbability Tree Diagrams Solutions Mathsupgrade Co UknatsNo ratings yet
- Language in UseDocument1 pageLanguage in UseEvaNo ratings yet
- Burkert General Catalogue Rev2Document44 pagesBurkert General Catalogue Rev2cuongNo ratings yet
- Strategic Management and Municipal Financial ReportingDocument38 pagesStrategic Management and Municipal Financial ReportingMarius BuysNo ratings yet
- Sustainability - Research PaperDocument18 pagesSustainability - Research PapermrigssNo ratings yet
- AP Poetry TermsDocument8 pagesAP Poetry TermsTEACHER BARAY LLCE ANGLAISNo ratings yet
- Lesson 2 - Procedures in Cleaning Utensils and EquipmentDocument26 pagesLesson 2 - Procedures in Cleaning Utensils and EquipmentReizel TulauanNo ratings yet
- KPW FSO Yetagun Presentation 250713Document36 pagesKPW FSO Yetagun Presentation 250713muhamadrafie1975No ratings yet
- SECURED TRANSACTION BAR CHECKLISTDocument4 pagesSECURED TRANSACTION BAR CHECKLISTatw4377100% (1)
- Forcepoint Email Security Configuration Information v8.5Document64 pagesForcepoint Email Security Configuration Information v8.5ajay chaudharyNo ratings yet
- Falling Weight Deflectometer (FWD) Projects in IndiaDocument13 pagesFalling Weight Deflectometer (FWD) Projects in IndiaKaran Dave100% (1)
- Leadership's Ramdom MCQsDocument48 pagesLeadership's Ramdom MCQsAhmed NoumanNo ratings yet
- PV380 Operations ManualDocument20 pagesPV380 Operations ManualCarlosNo ratings yet
- Lyrics: Original Songs: - JW BroadcastingDocument56 pagesLyrics: Original Songs: - JW BroadcastingLucky MorenoNo ratings yet
- Report-Teaching English Ministery of EduDocument21 pagesReport-Teaching English Ministery of EduSohrab KhanNo ratings yet
- Chapter Three: Business Plan PreparationDocument26 pagesChapter Three: Business Plan PreparationwaqoleNo ratings yet
- Online test series analysis reportDocument17 pagesOnline test series analysis reportchetan kapoorNo ratings yet
- Business Letter WritingDocument13 pagesBusiness Letter WritingAlex Alexandru100% (1)