You might also like
- CS229 Section: Python Tutorial: Maya SrikanthDocument39 pagesCS229 Section: Python Tutorial: Maya SrikanthTrần Thành LongNo ratings yet
- Alm Co-3 PDFDocument16 pagesAlm Co-3 PDFThota DeepNo ratings yet
- Cs3353 Fds Unit 4 Notes EduenggDocument44 pagesCs3353 Fds Unit 4 Notes EduenggGanesh KumarNo ratings yet
- 3rd UnitDocument75 pages3rd UnitDharma Teja Sunkara100% (1)
- Numpy - Basics - Jupyter NotebookDocument9 pagesNumpy - Basics - Jupyter Notebookhuzaifa khawarNo ratings yet
- ContentDocument12 pagesContentPrashanth ShettyNo ratings yet
- STD XII-IP Ch-1 (Practical)Document7 pagesSTD XII-IP Ch-1 (Practical)Vills GondaliyaNo ratings yet
- CS229 Python & Numpy: Jingbo Yang, Zhihan XiongDocument40 pagesCS229 Python & Numpy: Jingbo Yang, Zhihan Xiongsid s100% (1)
- NumPy & PandasDocument27 pagesNumPy & PandasPavan DevaNo ratings yet
- NumPy OperationsDocument6 pagesNumPy OperationsSaijanith PNo ratings yet
- Data Science - Unit IIDocument173 pagesData Science - Unit IIDHEEVIKA SURESH100% (1)
- NumPy Array Operations: Rank, Indexing, Math & MoreDocument6 pagesNumPy Array Operations: Rank, Indexing, Math & MoreSaijanith PNo ratings yet
- AD3301 - Numpy - and - Pandas - Ipynb - ColaboratoryDocument18 pagesAD3301 - Numpy - and - Pandas - Ipynb - Colaboratorypalaniappan.cseNo ratings yet
- What Is Numpy?: #Creating Array #Cheak Type of ArrDocument19 pagesWhat Is Numpy?: #Creating Array #Cheak Type of ArrVineet AnkamNo ratings yet
- Fdspracticals - Ipynb - ColaboratoryDocument21 pagesFdspracticals - Ipynb - Colaboratorycc76747321No ratings yet
- N Umpy NotebookDocument17 pagesN Umpy NotebookStocknEarnNo ratings yet
- Numpy - Tutorial - Ipynb - ColaboratoryDocument9 pagesNumpy - Tutorial - Ipynb - ColaboratoryAtul Kumar UttamNo ratings yet
- 2 - Numpy - Tutorial - Ipynb - ColaboratoryDocument10 pages2 - Numpy - Tutorial - Ipynb - ColaboratoryTayyab KhalilNo ratings yet
- NumPy: A Guide to the NumPy Multidimensional Array LibraryDocument8 pagesNumPy: A Guide to the NumPy Multidimensional Array LibraryNada ElokabyNo ratings yet
- Experiment No: 1 Introduction To Data Analytics and Python Fundamentals Page-1/11Document8 pagesExperiment No: 1 Introduction To Data Analytics and Python Fundamentals Page-1/11Harshali ManeNo ratings yet
- Ap19110010321 - JanithDocument6 pagesAp19110010321 - JanithSaijanith PNo ratings yet
- Pendahuluan PythonDocument29 pagesPendahuluan PythonArasy Dafa Sulistya KurniawanNo ratings yet
- Kuliah #7 Alprog - Numpy, Pandas, MatplotlibDocument48 pagesKuliah #7 Alprog - Numpy, Pandas, MatplotlibAzzahrah YrNo ratings yet
- AmanDocument3 pagesAmanSajan Kumar SinghNo ratings yet
- P02 Introduction To Numpy AnsDocument32 pagesP02 Introduction To Numpy AnsYONG LONG KHAWNo ratings yet
- Machine Learning NotesDocument52 pagesMachine Learning NotesBhagyashri RaneNo ratings yet
- PrintDocument296 pagesPrintMohammed ZameerNo ratings yet
- CodesDocument7 pagesCodesManeesh DarisiNo ratings yet
- DS Unit 3 Part 1Document27 pagesDS Unit 3 Part 1mounika narraNo ratings yet
- Fds AnswersDocument53 pagesFds AnswerssaranyatvcetNo ratings yet
- Lecture+Notes Python+for+DS PDFDocument48 pagesLecture+Notes Python+for+DS PDFRohit AsthanaNo ratings yet
- Numpy Pyhton tutorialDocument28 pagesNumpy Pyhton tutorialskreddyvgstNo ratings yet
- Informatics Practices Practical List22-2323Document7 pagesInformatics Practices Practical List22-2323Shivam GoswamiNo ratings yet
- Python IntroductionDocument20 pagesPython IntroductionKalaivani VNo ratings yet
- Python Myssql Programs For Practical File Class 12 IpDocument26 pagesPython Myssql Programs For Practical File Class 12 IpPragyanand SinghNo ratings yet
- 22mbada303 Module 4Document32 pages22mbada303 Module 4Kiran VinnuNo ratings yet
- Python 20240309 154846 0000Document34 pagesPython 20240309 154846 0000burnerpocoNo ratings yet
- Numpy Tutorial by Expertized GuyDocument12 pagesNumpy Tutorial by Expertized GuyReena ShahaNo ratings yet
- Numpy ArraysDocument7 pagesNumpy ArraysAdam TaufikNo ratings yet
- Pandas and SQL Class XII Practical ListDocument7 pagesPandas and SQL Class XII Practical ListShivam GoswamiNo ratings yet
- HUAWEI - 04 Third-Party LibrariesDocument59 pagesHUAWEI - 04 Third-Party LibrariesPierpaolo VergatiNo ratings yet
- JOVIA REPORTDocument18 pagesJOVIA REPORTmagembejude40No ratings yet
- Numpy Array Operations in Jupyter NotebookDocument32 pagesNumpy Array Operations in Jupyter NotebookSesha SaiNo ratings yet
- NumPy Arrays for MatricesDocument23 pagesNumPy Arrays for MatricesPriyaGandhiNo ratings yet
- Practical File Class - Xii Informatics Practices (New) : 1. How To Create A Series From A List, Numpy Array and Dict?Document17 pagesPractical File Class - Xii Informatics Practices (New) : 1. How To Create A Series From A List, Numpy Array and Dict?AHMED NAEEM 2No ratings yet
- NumPy arrays operations and functionsDocument18 pagesNumPy arrays operations and functionsPankaj AmaleNo ratings yet
- Introduction to Numpy arrays and operationsDocument11 pagesIntroduction to Numpy arrays and operationsVincent GiangNo ratings yet
- R Lab Programs-1Document26 pagesR Lab Programs-1rns itNo ratings yet
- Module 6 NumPY and PandasDocument12 pagesModule 6 NumPY and PandasMegha TrivediNo ratings yet
- Ipr Practical 2022Document7 pagesIpr Practical 2022Shivam GoswamiNo ratings yet
- Chapter 7 - ArraysDocument53 pagesChapter 7 - ArraysswatiNo ratings yet
- What Is PCA: When Should You Use PCA?Document21 pagesWhat Is PCA: When Should You Use PCA?sailushaNo ratings yet
- PL Labexer4 Sacasas ElizaldeDocument7 pagesPL Labexer4 Sacasas Elizaldeapi-565917483No ratings yet
- Informatics Practices Practical List22-2323Document6 pagesInformatics Practices Practical List22-2323Shivam GoswamiNo ratings yet
- Python Pandas N-WPS OfficeDocument15 pagesPython Pandas N-WPS OfficeDeepanshu RajputNo ratings yet
- NumPy BasicsDocument23 pagesNumPy BasicsRohith VKaNo ratings yet
- ML 2Document71 pagesML 2Shailesh KumarNo ratings yet
- Analitical ReseachDocument15 pagesAnalitical Reseachemir taşçıNo ratings yet
- Num PyDocument48 pagesNum Pysubodhaade2No ratings yet
- TDMSDocument10 pagesTDMSSambasiva MannavaNo ratings yet
- User Guide: Elektronikon Mk5 Gateway ModuleDocument24 pagesUser Guide: Elektronikon Mk5 Gateway ModuleMohd Faidzal100% (1)
- Raju MandapatiDocument4 pagesRaju MandapatiRaju MandapatiNo ratings yet
- Project Synopsis GuideDocument4 pagesProject Synopsis GuideDnyaneshwar Sham SalaveNo ratings yet
- Tsuma PrivateDocument4 pagesTsuma PrivateAditya KumarNo ratings yet
- National University of Technology CS4012 Database Systems Lab Assessment 04Document6 pagesNational University of Technology CS4012 Database Systems Lab Assessment 04Ansar IqbalNo ratings yet
- Remote Deposit Capture Team - Blue BarchDocument3 pagesRemote Deposit Capture Team - Blue BarchA.G. AshishNo ratings yet
- Salesforce Developer ResumeDocument8 pagesSalesforce Developer Resumevtdvkkjbf100% (2)
- Ict Assignment Set ADocument2 pagesIct Assignment Set AKyna RaborNo ratings yet
- ESMIG - U2A - Qualified - Configurations - v1.3.4 ENDocument31 pagesESMIG - U2A - Qualified - Configurations - v1.3.4 ENTest UserNo ratings yet
- JWT Social Auth with ASP.NET Core & Xamarin EssentialsDocument10 pagesJWT Social Auth with ASP.NET Core & Xamarin EssentialshsuyipNo ratings yet
- Mango Microfinance User ManualDocument31 pagesMango Microfinance User ManualOjelel Tony OcholNo ratings yet
- ICS Resource Unavailable in ProductionDocument7 pagesICS Resource Unavailable in ProductionDevender ReddyNo ratings yet
- Noise - LightroomDocument2 pagesNoise - LightroomLauraNo ratings yet
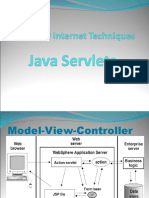
- Lecture 8 - Java ServletsDocument36 pagesLecture 8 - Java ServletsGaafar Mohammed GaafarNo ratings yet
- LinuxDocument491 pagesLinuxAlexperabrxNo ratings yet
- Crack Online Passwords With HYDRADocument9 pagesCrack Online Passwords With HYDRASaimonK100% (1)
- Prinect Signa Station - Install enDocument41 pagesPrinect Signa Station - Install enRogelio Jr. AustriaNo ratings yet
- Blockchain Technology in Current Agricultural Systems From Techniques To ApplicationsDocument18 pagesBlockchain Technology in Current Agricultural Systems From Techniques To ApplicationsPradyumna HathwarNo ratings yet
- CISCO - A Roadmap To SASEDocument11 pagesCISCO - A Roadmap To SASEMiguel Cabrera RamirezNo ratings yet
- File Based Approac VS Database ApproachDocument7 pagesFile Based Approac VS Database Approachnicos peeNo ratings yet
- CIV ManualDocument40 pagesCIV ManualVishnuNo ratings yet
- Honeywell Component Manual UpdateDocument74 pagesHoneywell Component Manual UpdateSanteBrucoliNo ratings yet
- Event Driven Programming: Class ScheduleDocument7 pagesEvent Driven Programming: Class ScheduleOlsen CortunaNo ratings yet
- m0 - 61544122s BlogDocument11 pagesm0 - 61544122s BlogRAZNo ratings yet
- Gattu PDFDocument27 pagesGattu PDFHarsh Commence 17No ratings yet
- IntroductionDocument4 pagesIntroductionkeith lorraine lumberaNo ratings yet
- C Interview Questions and Answers: Main Char CharDocument3 pagesC Interview Questions and Answers: Main Char CharMaheshNo ratings yet
- Dimas Miftahul Huda - CVDocument2 pagesDimas Miftahul Huda - CVteuku masnur ramadhanNo ratings yet
- Introduction of C LanguageDocument25 pagesIntroduction of C LanguageQamar AhmedNo ratings yet