You might also like
- Solutions To II Unit Exercises From KamberDocument16 pagesSolutions To II Unit Exercises From Kamberjyothibellaryv83% (42)
- Practical Engineering, Process, and Reliability StatisticsFrom EverandPractical Engineering, Process, and Reliability StatisticsNo ratings yet
- Week 2 Lab - Introduction To Data - CourseraDocument6 pagesWeek 2 Lab - Introduction To Data - CourseraSampada DesaiNo ratings yet
- E-Tivity 2.2 Tharcisse 217010849Document7 pagesE-Tivity 2.2 Tharcisse 217010849Tharcisse Tossen TharryNo ratings yet
- 1Z0 071 Demo PDFDocument8 pages1Z0 071 Demo PDFErwin Raphael Piolo Canlas EsmeriaNo ratings yet
- Q.1. Why Is Data Preprocessing Required?Document26 pagesQ.1. Why Is Data Preprocessing Required?Akshay Mathur100% (1)
- DATA MINING Chapter 1 and 2 Lect SlideDocument47 pagesDATA MINING Chapter 1 and 2 Lect SlideSanjeev ThakurNo ratings yet
- (NagpurStudents - Org) Database Management SystemDocument6 pages(NagpurStudents - Org) Database Management SystemAkash RautNo ratings yet
- DNS-global Name Servicies1Document14 pagesDNS-global Name Servicies1Alex Jens Jadiel LhemanNo ratings yet
- Excel Lab 1 - Descriptive StatisticsDocument8 pagesExcel Lab 1 - Descriptive StatisticsVeken BakradNo ratings yet
- Chapter 3 Data DescriptionDocument140 pagesChapter 3 Data DescriptionNg Ngọc Phương NgânNo ratings yet
- Lecture 9 MomentsDocument29 pagesLecture 9 MomentsAzhar HussainNo ratings yet
- Amity Centre For Elearning: Program: Semester-IDocument10 pagesAmity Centre For Elearning: Program: Semester-IDeepanarendraNo ratings yet
- Clustering Exercise 4-15-15Document2 pagesClustering Exercise 4-15-15nomore891No ratings yet
- Chapter 4: Probability Distributions: 4.1 Random VariablesDocument53 pagesChapter 4: Probability Distributions: 4.1 Random VariablesGanesh Nagal100% (1)
- CHAPTER 7 Probability DistributionsDocument97 pagesCHAPTER 7 Probability DistributionsAyushi Jangpangi100% (1)
- Essential Excel Skills For Data Preparation and Analysis Week 2Document3 pagesEssential Excel Skills For Data Preparation and Analysis Week 2Ivan Jon FerriolNo ratings yet
- Point Estimation: Definition of EstimatorsDocument8 pagesPoint Estimation: Definition of EstimatorsUshnish MisraNo ratings yet
- Multivariate Linear RegressionDocument30 pagesMultivariate Linear RegressionesjaiNo ratings yet
- Introduction To RDocument20 pagesIntroduction To Rseptian_bbyNo ratings yet
- DMDocument14 pagesDMPhani KumarNo ratings yet
- 1st Unit NotesDocument22 pages1st Unit NotesJazzNo ratings yet
- MA7155-Applied Probability and Statistics Question BankDocument15 pagesMA7155-Applied Probability and Statistics Question Bankselvakrishnan_sNo ratings yet
- 3 - Bayesian ClassificationDocument15 pages3 - Bayesian ClassificationjanubandaruNo ratings yet
- Computer Graphics Lecture 6-7Document74 pagesComputer Graphics Lecture 6-7Qazi ShaikhNo ratings yet
- Unit-3 IGNOU STATISTICSDocument13 pagesUnit-3 IGNOU STATISTICSCarbideman100% (1)
- Abstract, LinearDocument100 pagesAbstract, LinearMonty SigmundNo ratings yet
- R Basics NotesDocument15 pagesR Basics NotesGrowii GrowiiNo ratings yet
- Statistics Quiz 1 - SolutionsDocument11 pagesStatistics Quiz 1 - SolutionsAndrew LimNo ratings yet
- Sets PPT Math ProjectDocument11 pagesSets PPT Math Projectapi-248492367No ratings yet
- DispersionDocument2 pagesDispersionrauf tabassumNo ratings yet
- Applications of Statistical Software For Data AnalysisDocument5 pagesApplications of Statistical Software For Data AnalysisDrBabita SinglaNo ratings yet
- Test To Identify Outliers in Data SeriesDocument16 pagesTest To Identify Outliers in Data SeriesplanetpbNo ratings yet
- Test For Association of Attributes: Contingency TablesDocument7 pagesTest For Association of Attributes: Contingency TablesSaurabh Kulkarni 23No ratings yet
- Solution 1Document3 pagesSolution 1tinhyeusoida63% (8)
- Basic Anova PDFDocument6 pagesBasic Anova PDFEmmanuel Jimenez-Bacud, CSE-Professional,BA-MA Pol SciNo ratings yet
- Business Statistics Mid TermDocument2 pagesBusiness Statistics Mid TermgomalstudentNo ratings yet
- Design Analysis and AlgorithmDocument83 pagesDesign Analysis and AlgorithmLuis Anderson100% (2)
- ANOVA MCQ (Free PDF) - Objective Question Answer For ANOVA Quiz - Download Now!Document10 pagesANOVA MCQ (Free PDF) - Objective Question Answer For ANOVA Quiz - Download Now!jayant bansalNo ratings yet
- Lecture5 Fuzzy LogicDocument86 pagesLecture5 Fuzzy LogicAnshul PatodiNo ratings yet
- Index Numbers (Maths)Document12 pagesIndex Numbers (Maths)Vijay AgrahariNo ratings yet
- Compound Distributions and Mixture Distributions: ParametersDocument5 pagesCompound Distributions and Mixture Distributions: ParametersDennis ClasonNo ratings yet
- Ratio To Trend MethodDocument1 pageRatio To Trend MethodKumuthaa Ilangovan100% (1)
- Interval ScaleDocument7 pagesInterval ScaleGilian PradoNo ratings yet
- K - Nearest Neighbor AlgorithmDocument18 pagesK - Nearest Neighbor AlgorithmM.saqlain younasNo ratings yet
- OUTLIERSDocument5 pagesOUTLIERSRana Arslan Munir100% (1)
- R Programming NotesDocument113 pagesR Programming Notesnalluri_08No ratings yet
- Quantitative Techniques in FinanceDocument31 pagesQuantitative Techniques in FinanceAshraj_16No ratings yet
- Measure of Central TendencyDocument113 pagesMeasure of Central TendencyRajdeep DasNo ratings yet
- Multiple Linear RegressionDocument25 pagesMultiple Linear Regression3432meesala100% (1)
- Sampling Distribution EstimationDocument21 pagesSampling Distribution Estimationsoumya dasNo ratings yet
- Multiple Choice QuestionsDocument64 pagesMultiple Choice QuestionspatienceNo ratings yet
- Tabular and Graphical Descriptive Techniques Using MS-ExcelDocument20 pagesTabular and Graphical Descriptive Techniques Using MS-ExcelVarun LalwaniNo ratings yet
- Answer:: Convert The Following To Clausal FormDocument10 pagesAnswer:: Convert The Following To Clausal Form5140 - SANTHOSH.KNo ratings yet
- Vertical Horizons: 6-Variable K-Map - Karnaugh Map in Digital Electronics Tutorial Part 7Document5 pagesVertical Horizons: 6-Variable K-Map - Karnaugh Map in Digital Electronics Tutorial Part 7OMSURYACHANDRANNo ratings yet
- Multiple Choice QuestionsDocument3 pagesMultiple Choice QuestionsArnelson Derecho100% (3)
- FDP Day1Document35 pagesFDP Day1yadavsticky5108No ratings yet
- 1 e ExercisesDocument31 pages1 e ExerciseszubairulhassanNo ratings yet
- Computer Graphics - Question BankDocument8 pagesComputer Graphics - Question BankSyedkareem_hkg100% (1)
- DWDM Unit-2Document20 pagesDWDM Unit-2CS BCANo ratings yet
- E-Book On Essentials of Business Analytics: Group 7Document6 pagesE-Book On Essentials of Business Analytics: Group 7Mark Gabriel GerillaNo ratings yet
- Lis 111 Records ManagementDocument24 pagesLis 111 Records ManagementMichelle SipatNo ratings yet
- CAPE INFORMATION TECHNOLOGY Unit 2 SO 1Document14 pagesCAPE INFORMATION TECHNOLOGY Unit 2 SO 1Shannoyia D'Neila ClarkeNo ratings yet
- Data Preparation and AnalysisDocument22 pagesData Preparation and Analysismurlak37No ratings yet
- Data Warehousing Interview QuestionsDocument6 pagesData Warehousing Interview QuestionssurenNo ratings yet
- Step 1: Ask QuestionsDocument30 pagesStep 1: Ask QuestionsFarah MkhNo ratings yet
- Online BookDocument117 pagesOnline BookpavithraNo ratings yet
- Learning Module 01Document3 pagesLearning Module 01sample name100% (1)
- Administering Microsoft SQL Server DatabasesDocument4 pagesAdministering Microsoft SQL Server DatabasesMuthu Raman ChinnaduraiNo ratings yet
- UntitledDocument11 pagesUntitledJohn Edward LucenaNo ratings yet
- VSAM QuestionsDocument31 pagesVSAM QuestionsKrishnappa NiyogiNo ratings yet
- New Application /change Request Format: Schematic FlowDocument4 pagesNew Application /change Request Format: Schematic FlowUDAYNo ratings yet
- Ebook Concepts of Database Management 7Th Edition Pratt Solutions Manual Full Chapter PDFDocument28 pagesEbook Concepts of Database Management 7Th Edition Pratt Solutions Manual Full Chapter PDFkaylinque98y2100% (13)
- ThesisDocument104 pagesThesisberop31759No ratings yet
- Mysqlcourse 190815092242Document71 pagesMysqlcourse 190815092242Scribe.coNo ratings yet
- Finding The Right Reference Materials: Renato O. Arazo, PH.DDocument53 pagesFinding The Right Reference Materials: Renato O. Arazo, PH.DSebastian Carlo CabiadesNo ratings yet
- SC-XP-10.3.0-Upgrade Guide-EnDocument49 pagesSC-XP-10.3.0-Upgrade Guide-EnŁukasz MacuraNo ratings yet
- DDD - Firmware Update For E2eDocument46 pagesDDD - Firmware Update For E2enasierrasNo ratings yet
- De Unit 1-Database ConceptsDocument54 pagesDe Unit 1-Database ConceptsGautam ManchandaNo ratings yet
- Convert SQL Server Results Into JSONDocument1 pageConvert SQL Server Results Into JSONluca pilottiNo ratings yet
- Lect01-Annotated DBDocument31 pagesLect01-Annotated DBMadhulika BalakumarNo ratings yet
- Cloning Database Using RmanDocument2 pagesCloning Database Using RmanRaghavendra PrabhuNo ratings yet
- TigerGraph Buyers Guide Part 1Document8 pagesTigerGraph Buyers Guide Part 11977amNo ratings yet
- Leave Application Management SystemDocument26 pagesLeave Application Management SystemRana Toqeer Ahmad KhanNo ratings yet
- Azure AD ConnectDocument5 pagesAzure AD ConnectmicuNo ratings yet
- All SAP Security TCodesDocument4 pagesAll SAP Security TCodessmadhu324No ratings yet
- Exercise 4 Create QueriesDocument6 pagesExercise 4 Create QueriesJennifer Ledesma-PidoNo ratings yet
- Log MinarDocument24 pagesLog MinarGaurav GuptaNo ratings yet
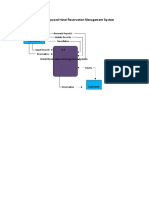
- Context Diagram of Proposed Hotel Reservation Management SystemDocument8 pagesContext Diagram of Proposed Hotel Reservation Management SystemJoffrey Montalla67% (3)
- CSIDEDocument402 pagesCSIDEalexandru_mg3No ratings yet