You might also like
- A Step by Step Explanation of Principal Component AnalysisDocument7 pagesA Step by Step Explanation of Principal Component AnalysisVaibhav YadavNo ratings yet
- Solutions To Problems in Merzbacher Quantum Mechanics 3rd Ed-Reid-P59Document59 pagesSolutions To Problems in Merzbacher Quantum Mechanics 3rd Ed-Reid-P59SVFA90% (10)
- 2DOF Systems PDFDocument41 pages2DOF Systems PDFManavNo ratings yet
- Estimation and Detection Theory by Don H. JohnsonDocument214 pagesEstimation and Detection Theory by Don H. JohnsonPraveen Chandran C RNo ratings yet
- Exercicios Resolvidos Parte 3Document35 pagesExercicios Resolvidos Parte 3Lucas Venâncio da Silva SantosNo ratings yet
- Unsupervised Machine Learning in PythonDocument89 pagesUnsupervised Machine Learning in PythonSoumya SahaNo ratings yet
- Hints To Problems On Fundamentals of Vector SpacesDocument6 pagesHints To Problems On Fundamentals of Vector SpaceschandrahasNo ratings yet
- Cho-Models To Solve Coupled PendulDocument4 pagesCho-Models To Solve Coupled PendulAqe KitamNo ratings yet
- Mech Vibes HW Set Solution 3Document9 pagesMech Vibes HW Set Solution 3Ryan HetzNo ratings yet
- Coeficiente Binomial Asociado A La Serie ArmónicaDocument3 pagesCoeficiente Binomial Asociado A La Serie ArmónicaOscar GutierrezNo ratings yet
- On Generalizations and Refinements of Triangle Inequalities: Tamotsu IzumidaDocument74 pagesOn Generalizations and Refinements of Triangle Inequalities: Tamotsu IzumidaFustei BogdanNo ratings yet
- CH605 2023 24tutorial3Document2 pagesCH605 2023 24tutorial3NeerajNo ratings yet
- A Note On Some New Bounds For Trigonometric Functions Using Infinite ProductsDocument8 pagesA Note On Some New Bounds For Trigonometric Functions Using Infinite ProductsElham AnarakiNo ratings yet
- DSP Additonal Solved ExamplesDocument44 pagesDSP Additonal Solved ExamplesAnonymous VG6Zat1oNo ratings yet
- ELC 325 Electromagnetic Waves - Lec 5Document25 pagesELC 325 Electromagnetic Waves - Lec 5mhmedibrahimuaNo ratings yet
- Problem Set 6 SolutionDocument3 pagesProblem Set 6 SolutionSourajit RoyNo ratings yet
- 2 Examples AnnotatedDocument26 pages2 Examples AnnotatedANIL EREN GÖÇERNo ratings yet
- HW 4 SolutionsDocument5 pagesHW 4 SolutionsKiran AdhikariNo ratings yet
- Eqworld: Tricomi EquationDocument1 pageEqworld: Tricomi EquationIsrael EmmanuelNo ratings yet
- Ch5 - Response of MDOF Systems PDFDocument37 pagesCh5 - Response of MDOF Systems PDFRicky AriyantoNo ratings yet
- FALLSEM2023-24 BECE202L TH VL2023240102253 2023-10-12 Reference-Material-IDocument5 pagesFALLSEM2023-24 BECE202L TH VL2023240102253 2023-10-12 Reference-Material-Is.sreeram135No ratings yet
- Impurity Scattering in Graphene Nano RibbonDocument5 pagesImpurity Scattering in Graphene Nano RibbonArun NissimagoudarNo ratings yet
- HRSAT82 (Honours Research in Astronomy)Document8 pagesHRSAT82 (Honours Research in Astronomy)Mpho MokanyaneNo ratings yet
- Articlepsib Am FMDocument4 pagesArticlepsib Am FMJean-ChristopheCexusNo ratings yet
- Petrovic Oper TH 1Document74 pagesPetrovic Oper TH 1Omonda NiiNo ratings yet
- The Z-Transform and Discrete Functions: Z KT X KT X T X Z XDocument5 pagesThe Z-Transform and Discrete Functions: Z KT X KT X T X Z XSàazón KasulaNo ratings yet
- Ch4 Multiple Linear Regression - PDF (Ch4 Multiple Linear Regression - PDF) (Z-Library)Document24 pagesCh4 Multiple Linear Regression - PDF (Ch4 Multiple Linear Regression - PDF) (Z-Library)ss tNo ratings yet
- 2013 Ui Mock Putnam Exam September 25, 2013, 5 PM - 7 PM SolutionsDocument4 pages2013 Ui Mock Putnam Exam September 25, 2013, 5 PM - 7 PM SolutionsGag PafNo ratings yet
- Model Predictive Control Examples Sheet: k+1 K K K KDocument8 pagesModel Predictive Control Examples Sheet: k+1 K K K KPierre Narcisse MASSOMA BILLENo ratings yet
- 4604 Exam3 Solutions Fa06Document25 pages4604 Exam3 Solutions Fa06Muhammad Nomaan ❊No ratings yet
- Unit 2Document31 pagesUnit 2aviNo ratings yet
- CPTR 36-40Document37 pagesCPTR 36-40Maulida HardiantiNo ratings yet
- U20ma301 Tpde Model Set 1Document4 pagesU20ma301 Tpde Model Set 1PriyankaNo ratings yet
- 2021 PH107 Tutorial10Document2 pages2021 PH107 Tutorial10Bhakti MatsyapalNo ratings yet
- L30 - COntrollability, Observability and Stability Os Discrete Time Systems - Revisiting The BasicDocument5 pagesL30 - COntrollability, Observability and Stability Os Discrete Time Systems - Revisiting The BasicKhi VuNo ratings yet
- Exercises: Stochastic ProcessesDocument4 pagesExercises: Stochastic ProcessestayeNo ratings yet
- Kronnig-Penney Using Block TheoremDocument6 pagesKronnig-Penney Using Block TheoremChris EvanNo ratings yet
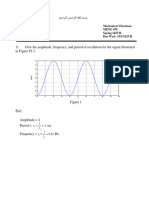
- 1) Give The Amplitude, Frequency, and Period of Oscillation For The Signal Illustrated in Figure P1.1Document8 pages1) Give The Amplitude, Frequency, and Period of Oscillation For The Signal Illustrated in Figure P1.1Ahmed Abdulbary AL-QarmNo ratings yet
- Quantum Mechanics - 5Document20 pagesQuantum Mechanics - 5khaledga65No ratings yet
- UTS CLO 2 Attempt ReviewDocument16 pagesUTS CLO 2 Attempt ReviewFEBRIYANANDA PRATAMA HERAWANNo ratings yet
- Midterm SolutionsDocument9 pagesMidterm SolutionsJohnathan SandersonNo ratings yet
- Chapter 15: Oscillations: The Mechanical Energy E of The Oscillator-Remains ConstantDocument9 pagesChapter 15: Oscillations: The Mechanical Energy E of The Oscillator-Remains ConstantAsifur R. HimelNo ratings yet
- EAT216 - Vibration 20191008Document47 pagesEAT216 - Vibration 20191008ibrahim ibrahimNo ratings yet
- Iterative LinearDocument10 pagesIterative LinearahmedNo ratings yet
- Assignment 1Document2 pagesAssignment 1lallamayandNo ratings yet
- HW SignalDocument4 pagesHW SignalHiếu VũNo ratings yet
- Lagrangians For Harmonic OscillatorsDocument2 pagesLagrangians For Harmonic Oscillatorssayandatta1No ratings yet
- Dynamical Systems and Chaos - Page 14Document4 pagesDynamical Systems and Chaos - Page 14Eyek MarzanNo ratings yet
- Sol 6Document5 pagesSol 6Luis ZambranoNo ratings yet
- ECE 6451 - Dr. Alan Doolittle Georgia TechDocument19 pagesECE 6451 - Dr. Alan Doolittle Georgia TechMosa A ShormanNo ratings yet
- 316s09hw04 SolnDocument4 pages316s09hw04 Solndaniela vanegasNo ratings yet
- Assignment1 SolutionDocument16 pagesAssignment1 Solutiondagani ranisamyukthaNo ratings yet
- Introduction To Nanomaterials and Devices - 2011 - Manasreh - Appendix A Derivation of Heisenberg Uncertainty PrincipleDocument4 pagesIntroduction To Nanomaterials and Devices - 2011 - Manasreh - Appendix A Derivation of Heisenberg Uncertainty Principleabhaypal617No ratings yet
- Lecture32 PDFDocument5 pagesLecture32 PDFMar BallesterosNo ratings yet
- EE 301 Notes - Chapter 3 - Part 1Document17 pagesEE 301 Notes - Chapter 3 - Part 1farouq_razzaz2574No ratings yet
- Analytic FBM RoughDocument27 pagesAnalytic FBM Roughanahh ramakNo ratings yet
- Lecture 4Document35 pagesLecture 4Nart-Ahia GideonNo ratings yet
- Abstract. We Extend The Applicability of The Kantorovich Theorem (KT) ForDocument8 pagesAbstract. We Extend The Applicability of The Kantorovich Theorem (KT) ForPaco DamianNo ratings yet
- HW No 2. February 26, 2017.docx SolutionDocument4 pagesHW No 2. February 26, 2017.docx SolutionkhalidNo ratings yet
- Topic22 DFT and FFTDocument7 pagesTopic22 DFT and FFTManikanta KrishnamurthyNo ratings yet
- Amen A221109Document6 pagesAmen A221109satitz chongNo ratings yet
- Article Przeglad EuropejskiDocument14 pagesArticle Przeglad EuropejskiAgustín EstramilNo ratings yet
- Assignment 1 - GossipDocument3 pagesAssignment 1 - GossipAgustín EstramilNo ratings yet
- OBD Parts 1 and 2 PDFDocument106 pagesOBD Parts 1 and 2 PDFAgustín EstramilNo ratings yet
- Essential Questions For The Exam 2018, AMCS 308, Stochastic Methods in EngineeringDocument14 pagesEssential Questions For The Exam 2018, AMCS 308, Stochastic Methods in EngineeringAgustín EstramilNo ratings yet
- Essential Questions For The Exam 2017, AMCS 336, Numerical Methods For Stochastic Differential EquationsDocument21 pagesEssential Questions For The Exam 2017, AMCS 336, Numerical Methods For Stochastic Differential EquationsAgustín EstramilNo ratings yet
- Essential Questions For The Exam 2018, AMCS 308, Stochastic Methods in EngineeringDocument20 pagesEssential Questions For The Exam 2018, AMCS 308, Stochastic Methods in EngineeringAgustín EstramilNo ratings yet
- Kode ScriptDocument25 pagesKode ScriptJmc JktNo ratings yet
- Moore 1968Document3 pagesMoore 1968Leqia HeNo ratings yet
- M.SC Statistics (MDU)Document28 pagesM.SC Statistics (MDU)DrRitu MalikNo ratings yet
- Data Analaysis and Visualization - 49QDocument28 pagesData Analaysis and Visualization - 49Qahmedmaheen123No ratings yet
- Steiger 1990Document9 pagesSteiger 1990AlexNo ratings yet
- Estimación de La Forma Del Blanco Aplicada A Radar PasivoDocument13 pagesEstimación de La Forma Del Blanco Aplicada A Radar PasivoNelson CruzNo ratings yet
- The Digital Divide of Word of Mouth PDFDocument9 pagesThe Digital Divide of Word of Mouth PDFjolliebraNo ratings yet
- Exponentially Weighted Control Charts To Monitor Multivariate Process Variability For High Dimensions - IJPR - 2017Document16 pagesExponentially Weighted Control Charts To Monitor Multivariate Process Variability For High Dimensions - IJPR - 2017Carlos Dario CristianoNo ratings yet
- MD Tutorial Using GromacsDocument22 pagesMD Tutorial Using GromacsSeagal AsjaliNo ratings yet
- Manual Stata MultilevelDocument371 pagesManual Stata MultilevelJaime CazaNo ratings yet
- Kalman Filter and Surveying ApplicationsDocument30 pagesKalman Filter and Surveying ApplicationskateborghiNo ratings yet
- RV CoefficientDocument3 pagesRV Coefficientdev414No ratings yet
- Analytical Chemistry by Ira S. KrullDocument154 pagesAnalytical Chemistry by Ira S. KrullDaniel PolancoNo ratings yet
- 6114 Weight Normalization A Simple Reparameterization To Accelerate Training of Deep Neural NetworksDocument9 pages6114 Weight Normalization A Simple Reparameterization To Accelerate Training of Deep Neural NetworksJose Miguel AlvesNo ratings yet
- EmpFinPhDAll PDFDocument360 pagesEmpFinPhDAll PDFjamilkhannNo ratings yet
- Lecture Note 4 To 7 OLSDocument29 pagesLecture Note 4 To 7 OLSViktória KónyaNo ratings yet
- Position Recovery From Accelerometric SensorsDocument50 pagesPosition Recovery From Accelerometric SensorsMarkusMayer100% (1)
- Deep Learning: Nicholas G. Polson Vadim O. SokolovDocument18 pagesDeep Learning: Nicholas G. Polson Vadim O. SokolovAbdul HamidNo ratings yet
- A Tutorial On Principal Component AnalysisDocument29 pagesA Tutorial On Principal Component AnalysisrigastiNo ratings yet
- Hausman - Hausman Specification TestDocument10 pagesHausman - Hausman Specification TestSaiganesh RameshNo ratings yet
- CSE3506 - Essentials of Data Analytics: Facilitator: DR Sathiya Narayanan SDocument36 pagesCSE3506 - Essentials of Data Analytics: Facilitator: DR Sathiya Narayanan SWINORLOSENo ratings yet
- All Tutorials Dynamic EconometricsDocument58 pagesAll Tutorials Dynamic EconometricsAriyan JahanyarNo ratings yet
- Advanced Machine Learning: CS 281Document88 pagesAdvanced Machine Learning: CS 281Will White100% (1)
- Dynare Examples PDFDocument21 pagesDynare Examples PDFAnonymous T2LhplUNo ratings yet
- Estimation Variogram UncertaintyDocument32 pagesEstimation Variogram UncertaintydamebrolisNo ratings yet
- DBMAFSIMDocument20 pagesDBMAFSIMMário de FreitasNo ratings yet
- Unit - Iv: After Reading This Chapter, Students ShouldDocument37 pagesUnit - Iv: After Reading This Chapter, Students ShouldJayash KaushalNo ratings yet