You might also like
- Econ 251 S2018 PS6 SolutionsDocument16 pagesEcon 251 S2018 PS6 SolutionsPeter ShangNo ratings yet
- Econ 251 PS4 SolutionsDocument11 pagesEcon 251 PS4 SolutionsPeter ShangNo ratings yet
- Transcricao How To Be Happy (Before Success) - by Earl NightingaleDocument62 pagesTranscricao How To Be Happy (Before Success) - by Earl NightingalepauloalaraNo ratings yet
- Econ 251 PS1 SolutionsDocument5 pagesEcon 251 PS1 SolutionsPeter ShangNo ratings yet
- Econ 251 PS5 SolutionsDocument16 pagesEcon 251 PS5 SolutionsPeter ShangNo ratings yet
- PzenaCommentary Second Quarter 2013Document3 pagesPzenaCommentary Second Quarter 2013CanadianValueNo ratings yet
- Econ 138: Financial and Behavioral Economics: Noise-Trader Risk in Financial Markets February 8 & 13, 2017Document35 pagesEcon 138: Financial and Behavioral Economics: Noise-Trader Risk in Financial Markets February 8 & 13, 2017econdocs0% (1)
- Investing in Credit Hedge Funds: An In-Depth Guide to Building Your Portfolio and Profiting from the Credit MarketFrom EverandInvesting in Credit Hedge Funds: An In-Depth Guide to Building Your Portfolio and Profiting from the Credit MarketNo ratings yet
- Econ 251 PS3 Solutions v2Document18 pagesEcon 251 PS3 Solutions v2Peter ShangNo ratings yet
- Econ 251 PS3 Solutions v2Document18 pagesEcon 251 PS3 Solutions v2Peter ShangNo ratings yet
- Fae3e SM ch03Document19 pagesFae3e SM ch03JarkeeNo ratings yet
- VolatilityFriendOrFoeDocument18 pagesVolatilityFriendOrFoejacekNo ratings yet
- Art em Is Capital Currency NoteDocument35 pagesArt em Is Capital Currency NoteBen SchwartzNo ratings yet
- Mizuho EconomicOutlook 17.5.29Document3 pagesMizuho EconomicOutlook 17.5.29abraNo ratings yet
- SSRN Id1138782 PDFDocument45 pagesSSRN Id1138782 PDFmanojNo ratings yet
- Anatomy of A CrisisDocument17 pagesAnatomy of A CrisisgautamnarulaNo ratings yet
- Building A Global Core-Satellite Portfolio: Executive SummaryDocument12 pagesBuilding A Global Core-Satellite Portfolio: Executive SummarydospxNo ratings yet
- Paper On Mcap To GDPDocument20 pagesPaper On Mcap To GDPgreyistariNo ratings yet
- Vanguard Asset AllocationDocument19 pagesVanguard Asset AllocationVinicius QueirozNo ratings yet
- The GIC WeeklyDocument12 pagesThe GIC WeeklyedgarmerchanNo ratings yet
- Artemis - Meeting+of+the+Waters - March2016Document5 pagesArtemis - Meeting+of+the+Waters - March2016jacekNo ratings yet
- When Do Stop-Loss Rules Stop LossesDocument42 pagesWhen Do Stop-Loss Rules Stop LossesPieroNo ratings yet
- The GIC Weekly Update November 2015Document12 pagesThe GIC Weekly Update November 2015John MathiasNo ratings yet
- 5 - RegressionDocument63 pages5 - RegressionMarcello RossiNo ratings yet
- Artemis+Letter+to+Investors What+is+Water July2018 2 PDFDocument11 pagesArtemis+Letter+to+Investors What+is+Water July2018 2 PDFmdorneanuNo ratings yet
- Gic WeeklyDocument12 pagesGic WeeklycampiyyyyoNo ratings yet
- Alluvial Tear SheetDocument1 pageAlluvial Tear SheetkdwcapitalNo ratings yet
- The Fifth HorsemanDocument18 pagesThe Fifth HorsemanFrancesco LontriNo ratings yet
- Artemis - The Great Vega Short - Volatility, Tail Risk, and Sleeping ElephantsDocument10 pagesArtemis - The Great Vega Short - Volatility, Tail Risk, and Sleeping ElephantsRazvan Arion100% (2)
- A Step-By-Step Guide To The Black-Litterman Model Incorporating User-Specified Confidence LevelsDocument34 pagesA Step-By-Step Guide To The Black-Litterman Model Incorporating User-Specified Confidence LevelsMang AwanNo ratings yet
- Eri WP Predicting Decomposing Risk Data Driven Portfolios 0 PDFDocument46 pagesEri WP Predicting Decomposing Risk Data Driven Portfolios 0 PDFdemetraNo ratings yet
- Not All Risk Mitigation Is Created Equal: Mark SpitznagelDocument7 pagesNot All Risk Mitigation Is Created Equal: Mark SpitznagelASM AAS ASSASNo ratings yet
- Bridgewater File 6Document87 pagesBridgewater File 6the kingfishNo ratings yet
- Virtual Value Investing Student Info SessionDocument13 pagesVirtual Value Investing Student Info SessionKeren CherskyNo ratings yet
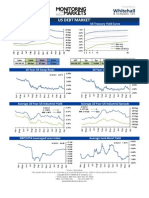
- 2.17 Whitehall: Monitoring The Markets Vol. 2 Iss. 17 (April 24, 2012)Document2 pages2.17 Whitehall: Monitoring The Markets Vol. 2 Iss. 17 (April 24, 2012)Whitehall & CompanyNo ratings yet
- Strategy Focus Report - Market Neutral EquityDocument5 pagesStrategy Focus Report - Market Neutral EquityZerohedgeNo ratings yet
- CampelloSaffi15 PDFDocument39 pagesCampelloSaffi15 PDFdreamjongenNo ratings yet
- Technical Report (Equity) - 26 Dec 2019 - 26!12!2019 - 09Document3 pagesTechnical Report (Equity) - 26 Dec 2019 - 26!12!2019 - 09Avismith DuttaNo ratings yet
- Artemis+Research - Dennis+Rodman+and+Portfolio+Optimization - April2016Document7 pagesArtemis+Research - Dennis+Rodman+and+Portfolio+Optimization - April2016jacekNo ratings yet
- Accelerating Dual Momentum Is Better Than Classic Dual MomentumDocument26 pagesAccelerating Dual Momentum Is Better Than Classic Dual MomentumAyhanNo ratings yet
- Incremental and Marginal VaR Plus Infiniti 4 Moment Version No VBADocument14 pagesIncremental and Marginal VaR Plus Infiniti 4 Moment Version No VBAPeter UrbaniNo ratings yet
- By Ben Carlson: The Only Rational Deployment of Our IgnoranceDocument33 pagesBy Ben Carlson: The Only Rational Deployment of Our IgnoranceBen CarlsonNo ratings yet
- Value-At-risk Based Portfolio Theory - Optimum Startegies and AllocationDocument35 pagesValue-At-risk Based Portfolio Theory - Optimum Startegies and AllocationDebNo ratings yet
- LemonsAndCDOsWhyDidSoManyLenders PreviewDocument68 pagesLemonsAndCDOsWhyDidSoManyLenders PreviewkunalwarwickNo ratings yet
- Profitable and Unprofitable Investment Sectors Detailed in Quarterly ReportDocument28 pagesProfitable and Unprofitable Investment Sectors Detailed in Quarterly ReportMilan StojevNo ratings yet
- Cio Spotlight ReportDocument9 pagesCio Spotlight Reporthkm_gmat4849No ratings yet
- The Hardest Market EverDocument65 pagesThe Hardest Market EverBen Carlson100% (1)
- Understanding DilutionDocument4 pagesUnderstanding DilutionKunalNo ratings yet
- CS Global Money Notes 2Document26 pagesCS Global Money Notes 2rockstarliveNo ratings yet
- Understanding Style PremiaDocument9 pagesUnderstanding Style PremiaZen TraderNo ratings yet
- Why I'm Bullish On The Next Gen in FinanceDocument48 pagesWhy I'm Bullish On The Next Gen in FinanceBen CarlsonNo ratings yet
- EDHEC-Risk Publication Dynamic Risk Control ETFsDocument44 pagesEDHEC-Risk Publication Dynamic Risk Control ETFsAnindya Chakrabarty100% (1)
- On Gold Swings and Cluelessness Galore: Ctober SsueDocument13 pagesOn Gold Swings and Cluelessness Galore: Ctober SsueChad Thayer VNo ratings yet
- JPM研报 ELDocument34 pagesJPM研报 ELMENGWEI ZHOUNo ratings yet
- Capital Flow AnalysisDocument8 pagesCapital Flow AnalysisNak-Gyun KimNo ratings yet
- JPM Registry Provider Survey Report March 2012Document33 pagesJPM Registry Provider Survey Report March 2012Nicholas AngNo ratings yet
- Bank Loans Poised to Deliver Attractive Risk-Adjusted ReturnsDocument6 pagesBank Loans Poised to Deliver Attractive Risk-Adjusted ReturnsSabin NiculaeNo ratings yet
- Global Investment Returns Yearbook 2014Document68 pagesGlobal Investment Returns Yearbook 2014Rosetta RennerNo ratings yet
- GS OutlookDocument30 pagesGS OutlookMrittunjayNo ratings yet
- CLO Liquidity Provision and the Volcker Rule: Implications on the Corporate Bond MarketFrom EverandCLO Liquidity Provision and the Volcker Rule: Implications on the Corporate Bond MarketNo ratings yet
- Statement of Cash Flows: Financial Accounting - Lecture 3Document29 pagesStatement of Cash Flows: Financial Accounting - Lecture 3Peter ShangNo ratings yet
- Revenue Recognition and Receivables: Financial Accounting - Lecture 5Document30 pagesRevenue Recognition and Receivables: Financial Accounting - Lecture 5Peter ShangNo ratings yet
- Accounting Process and Adjusting EntriesDocument7 pagesAccounting Process and Adjusting EntriesPeter ShangNo ratings yet
- Long-Lived Tangible and Intangible Assets: Financial Accounting - Lecture 4Document11 pagesLong-Lived Tangible and Intangible Assets: Financial Accounting - Lecture 4Peter ShangNo ratings yet
- Income Statement and Adjusting Entries ExplainedDocument21 pagesIncome Statement and Adjusting Entries ExplainedPeter Shang100% (1)
- SF-2012AH-QG User' S ManualDocument61 pagesSF-2012AH-QG User' S Manualkamal hasan0% (1)
- Marketing Strategies Audit On Hewlett Packard (HP)Document19 pagesMarketing Strategies Audit On Hewlett Packard (HP)auraNo ratings yet
- First Aid KitDocument15 pagesFirst Aid Kitdex adecNo ratings yet
- Proficiency 6Document4 pagesProficiency 6api-508196283No ratings yet
- New Product Performance Advantages For Extending Large, Established Fast Moving Consumer Goods (FMCG) BrandsDocument18 pagesNew Product Performance Advantages For Extending Large, Established Fast Moving Consumer Goods (FMCG) Brandssmart_kidzNo ratings yet
- Accenture Sustainable ProcurementDocument2 pagesAccenture Sustainable ProcurementAnupriyaSaxenaNo ratings yet
- Probability Concepts and Random Variable - SMTA1402: Unit - IDocument105 pagesProbability Concepts and Random Variable - SMTA1402: Unit - IVigneshwar SNo ratings yet
- Case3: What's in A Car 1. What Kind of Research Study Should Shridhar Undertake? Define TheDocument2 pagesCase3: What's in A Car 1. What Kind of Research Study Should Shridhar Undertake? Define TheRoshan kumar Rauniyar0% (3)
- Institute of Graduate Studies (Igs)Document46 pagesInstitute of Graduate Studies (Igs)Syara Shazanna ZulkifliNo ratings yet
- Probability and Statistics. ASSIGNMENT 2Document5 pagesProbability and Statistics. ASSIGNMENT 2ByhiswillNo ratings yet
- National Capital Region Schools Division Office Novaliches High School MAPEH Department Definitive Budget of Work for Blended Learning Modality Quarter 1 Grade 10Document9 pagesNational Capital Region Schools Division Office Novaliches High School MAPEH Department Definitive Budget of Work for Blended Learning Modality Quarter 1 Grade 10Ma. Cristina Angenel RamosNo ratings yet
- RIZAL: INSPIRATION FOR A NEW GENERATIONDocument11 pagesRIZAL: INSPIRATION FOR A NEW GENERATIONErica B. DaclanNo ratings yet
- Growatt Warranty Procedure - 07-09-2020Document9 pagesGrowatt Warranty Procedure - 07-09-2020Design TeamNo ratings yet
- K Park 24 TH Edition ChangesDocument8 pagesK Park 24 TH Edition ChangesAnkit ChoudharyNo ratings yet
- 7306 31980 1 PBDocument10 pages7306 31980 1 PBRaihan Aditiya JuniorNo ratings yet
- EMAG W01 RodHeatingDocument16 pagesEMAG W01 RodHeatingMiguel Ángel ArizaNo ratings yet
- 5.1 Advanced Pattern Making - IDocument9 pages5.1 Advanced Pattern Making - IRisul Islam EmonNo ratings yet
- Careers at FEWA-DubaiDocument8 pagesCareers at FEWA-DubaiJnanamNo ratings yet
- CSB 211102 1 FCT EMS 702 Upgrade Process With Security FeaturesDocument2 pagesCSB 211102 1 FCT EMS 702 Upgrade Process With Security FeaturesCedric NkongoNo ratings yet
- AST Study Centers 2021 Updated Till 25oct2021 GOVT DATADocument33 pagesAST Study Centers 2021 Updated Till 25oct2021 GOVT DATAprasadNo ratings yet
- Providing Clean Water and Financial Assistance in Binangonan RizalDocument29 pagesProviding Clean Water and Financial Assistance in Binangonan RizalArebeeJayBelloNo ratings yet
- RTR - Nonmetallic Pipng ProcedureDocument16 pagesRTR - Nonmetallic Pipng Proceduremoytabura96100% (1)
- Rubber Conveyor Belt Wear ResistanceDocument5 pagesRubber Conveyor Belt Wear ResistanceBelt Power LLCNo ratings yet
- Deutz td2011 l04w Service Manual PDFDocument7 pagesDeutz td2011 l04w Service Manual PDFLuis Carlos RamosNo ratings yet
- NCM 105-Lesson 2Document68 pagesNCM 105-Lesson 2Roshin TejeroNo ratings yet
- Wma11 01 Que 20221011Document28 pagesWma11 01 Que 20221011Maks LubasNo ratings yet
- Death of Frank LangamanDocument6 pagesDeath of Frank LangamanPaul ToguayNo ratings yet
- Presentation - On SVAMITVADocument18 pagesPresentation - On SVAMITVAPraveen PrajapatiNo ratings yet
- Vdocuments - MX Setting Procedure Evs HMF Tech Procedure Evs 11 16pdf Setting ProcedureDocument37 pagesVdocuments - MX Setting Procedure Evs HMF Tech Procedure Evs 11 16pdf Setting ProcedureKrum Kashavarov100% (1)