You might also like
- Huang L 2011Corpus-Aided Language Learning Key Concepts in ELTDocument4 pagesHuang L 2011Corpus-Aided Language Learning Key Concepts in ELTjuliaayscoughNo ratings yet
- Arab World English Journal (AWEJ) Volume 9. Number 3. September 2018 Pp.176-187Document12 pagesArab World English Journal (AWEJ) Volume 9. Number 3. September 2018 Pp.176-187learning EnglishNo ratings yet
- Multilingualism and Translanguaging in Chinese Language ClassroomsFrom EverandMultilingualism and Translanguaging in Chinese Language ClassroomsNo ratings yet
- First: Changes in Goals of English Teaching and Learning.: Amel Lusta / 2017Document6 pagesFirst: Changes in Goals of English Teaching and Learning.: Amel Lusta / 2017sparkling9No ratings yet
- Analysis of a Medical Research Corpus: A Prelude for Learners, Teachers, Readers and BeyondFrom EverandAnalysis of a Medical Research Corpus: A Prelude for Learners, Teachers, Readers and BeyondNo ratings yet
- Developing Collocation S 2Document23 pagesDeveloping Collocation S 2antarNo ratings yet
- Proposal Mina PashazanousDocument26 pagesProposal Mina PashazanousminaNo ratings yet
- Data Driven Learning A Call For A Broader Research GazeDocument14 pagesData Driven Learning A Call For A Broader Research GazeUMUT MUHARREM SALİHOĞLUNo ratings yet
- English Language Material DevelopmentDocument9 pagesEnglish Language Material DevelopmentSakuraNo ratings yet
- PHO1Document11 pagesPHO1TỪ TÀI HUỲNHNo ratings yet
- A Proposal For Language Teaching in Tran PDFDocument13 pagesA Proposal For Language Teaching in Tran PDFGERMAIN ZOA MANGANo ratings yet
- On Vocabulary Presentation Modes in College English Teaching and LearningDocument6 pagesOn Vocabulary Presentation Modes in College English Teaching and LearningHardiman AminNo ratings yet
- My Paper On Leveraging I+1 Input ModelDocument20 pagesMy Paper On Leveraging I+1 Input ModelAhmadNo ratings yet
- 9 - English Language Syllabuses - Definition, Types, Design, and SelectionDocument16 pages9 - English Language Syllabuses - Definition, Types, Design, and SelectionLily MaulidyahNo ratings yet
- 1 SMDocument7 pages1 SMNabila YasifaNo ratings yet
- Corpus Approach To Analysing Gerund Vs InfinitiveDocument16 pagesCorpus Approach To Analysing Gerund Vs Infinitivesswoo8245No ratings yet
- Role of Applied Linguistics in The Teaching of English in Saudi ArabiaDocument11 pagesRole of Applied Linguistics in The Teaching of English in Saudi Arabiaرحمة الجنيديNo ratings yet
- Communicative Dictation For Adult Foreign Language Learners in University Academic ContextsDocument11 pagesCommunicative Dictation For Adult Foreign Language Learners in University Academic ContextsGlobal Research and Development ServicesNo ratings yet
- CorporaDocument26 pagesCorporaN SNo ratings yet
- Corpus-Aided Language Learning: Key Concepts inDocument4 pagesCorpus-Aided Language Learning: Key Concepts inWiqoyil IslamaNo ratings yet
- Research StudyDocument15 pagesResearch StudyJhelene AlyzzaNo ratings yet
- Learning Strategies in ESP Classroom Concordancing: An Initial Investigation Into Data-Driven LearningDocument21 pagesLearning Strategies in ESP Classroom Concordancing: An Initial Investigation Into Data-Driven LearningNovák-Arnold NikolettNo ratings yet
- Thesis & Research Final Project 7th Semester 2021Document7 pagesThesis & Research Final Project 7th Semester 2021Danang AdinugrahaNo ratings yet
- 10 51726-jlr 714724-1198537Document14 pages10 51726-jlr 714724-1198537Lương Nguyễn Vân ThanhNo ratings yet
- 2022 O'FlynnDocument28 pages2022 O'FlynnHurmet FatimaNo ratings yet
- Revisiting The Content-Based Instruction in Language Teaching in Relation With CLIL: Implementation and OutcomeDocument11 pagesRevisiting The Content-Based Instruction in Language Teaching in Relation With CLIL: Implementation and OutcomeNurulfNo ratings yet
- To Dictogloss or Not To Dictogloss Potential Effects On Jordanian Efl Learners Written PerformanceDocument18 pagesTo Dictogloss or Not To Dictogloss Potential Effects On Jordanian Efl Learners Written PerformanceОльга СурьяниноваNo ratings yet
- Content ServerDocument27 pagesContent ServerClaudia Albuccó AriztíaNo ratings yet
- Ejbss 1403 14 Effectsoftask BasedstrategiesonstudentsDocument16 pagesEjbss 1403 14 Effectsoftask BasedstrategiesonstudentsOnwaree Lily PromtaNo ratings yet
- Authenticity Material Effectiveness-1Document14 pagesAuthenticity Material Effectiveness-1Nurul FatinNo ratings yet
- PROPOSAL Kartini S3 Edit ArmanDocument83 pagesPROPOSAL Kartini S3 Edit ArmanAndi ArmanNo ratings yet
- English Language Syllabuses: Definition, Types, Design, and SelectionDocument11 pagesEnglish Language Syllabuses: Definition, Types, Design, and SelectionJuliana LunaNo ratings yet
- Number Nine DreamDocument16 pagesNumber Nine Dreamviersieben0% (1)
- Artikel Challenges CLTDocument9 pagesArtikel Challenges CLTnoviani nurjannahNo ratings yet
- A J AL: Using Pictures in Teaching Metaphorical Expressions To Arabic-Speaking EFL LearnersDocument13 pagesA J AL: Using Pictures in Teaching Metaphorical Expressions To Arabic-Speaking EFL LearnersMaria FernandaNo ratings yet
- EFL Learners' Writing Progress Through Collocation Awareness-Raising Approach: An Analytic AssessmentDocument16 pagesEFL Learners' Writing Progress Through Collocation Awareness-Raising Approach: An Analytic AssessmentEbrahim AbdullaNo ratings yet
- Ej 1313596Document12 pagesEj 1313596Hou FadelNo ratings yet
- Blended Learning in A University EFL Writing Course: Description and EvaluationDocument9 pagesBlended Learning in A University EFL Writing Course: Description and EvaluationKetrin ViollitaNo ratings yet
- Chapter IiiDocument4 pagesChapter Iiivanni devarizalNo ratings yet
- Ej 1359174Document15 pagesEj 1359174agitoagito26No ratings yet
- Subtitling On The Intersection of Theory and Practice: Pedagogical Research-Based Approach To Subtitler TrainingDocument16 pagesSubtitling On The Intersection of Theory and Practice: Pedagogical Research-Based Approach To Subtitler TrainingmalakmaghafNo ratings yet
- Does Task Complexity MatterDocument10 pagesDoes Task Complexity MatterzhaojingnaquNo ratings yet
- TPLS, 02Document6 pagesTPLS, 02Ngọc Nông Thị HồngNo ratings yet
- Data-Driven South Asian Language Learning: SALRC Pedagogy Workshop June 8, 2005Document14 pagesData-Driven South Asian Language Learning: SALRC Pedagogy Workshop June 8, 2005Naheed AzhariNo ratings yet
- 1601 6054 2 PBDocument23 pages1601 6054 2 PBKhánh Linh ĐàoNo ratings yet
- Colin Christie (2016) Speaking Spontaneously in The Modern Foreign Languages Classroom - Tools For Supporting Successful Target Language ConversationDocument17 pagesColin Christie (2016) Speaking Spontaneously in The Modern Foreign Languages Classroom - Tools For Supporting Successful Target Language ConversationShahid.wNo ratings yet
- Chen and Bruncak - 2015Document6 pagesChen and Bruncak - 2015Darren O'BrienNo ratings yet
- Coursebook EvaluationDocument10 pagesCoursebook Evaluationthy ngocNo ratings yet
- 181-Article Text-304-1-10-20171229Document13 pages181-Article Text-304-1-10-20171229Huy NguyenNo ratings yet
- Vocabulary Acquisition Through Direct and Indirect Learning StrategiesDocument10 pagesVocabulary Acquisition Through Direct and Indirect Learning StrategiesAnonymous 0WoVWFsINo ratings yet
- TESOL Quarterly - 2022 - Shi - I Don T Let What I Don T Know Stop What I Can Do How Monolingual English TeachersDocument28 pagesTESOL Quarterly - 2022 - Shi - I Don T Let What I Don T Know Stop What I Can Do How Monolingual English Teachersivyzheng1027No ratings yet
- Isbn: 978-607-8356-17-1Document6 pagesIsbn: 978-607-8356-17-1N SNo ratings yet
- EYL Zein-2018-TranslanguagingintheEYLclassroomasametadiscursivepracticeDocument7 pagesEYL Zein-2018-TranslanguagingintheEYLclassroomasametadiscursivepracticePRASANDI PINASTHIKONo ratings yet
- EJ1199324Document11 pagesEJ1199324Trung Thành NguyễnNo ratings yet
- Literature Review On Mother Tongue InterferenceDocument4 pagesLiterature Review On Mother Tongue Interferencec5p9zbep100% (1)
- Lexical Cohesion of Sino-British College Students EAP WritingDocument7 pagesLexical Cohesion of Sino-British College Students EAP Writingarnold tyNo ratings yet
- Corpus Linguistics and Vocabulary: A Commentary On Four StudiesDocument9 pagesCorpus Linguistics and Vocabulary: A Commentary On Four Studiessisifo80No ratings yet
- HORST - Lextutor - Academic VocabularyDocument21 pagesHORST - Lextutor - Academic VocabularyOlga TszagaNo ratings yet
- UNDP Information Note-Implementation of GA Resolution 72-279Document8 pagesUNDP Information Note-Implementation of GA Resolution 72-279Stillme MotollaNo ratings yet
- Repertoire of The Practice of The Security Council: United NationsDocument580 pagesRepertoire of The Practice of The Security Council: United NationsStillme MotollaNo ratings yet
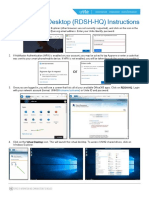
- Mobile Office Microsoft VDI PDFDocument1 pageMobile Office Microsoft VDI PDFStillme MotollaNo ratings yet
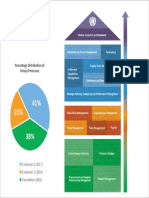
- Figure I 12th Umoja PR RDocument1 pageFigure I 12th Umoja PR RStillme MotollaNo ratings yet
- 2021-5-Evaluation Summary-Strategic Plan 2018-2021-2020.12.17 DeptCorr PDFDocument4 pages2021-5-Evaluation Summary-Strategic Plan 2018-2021-2020.12.17 DeptCorr PDFStillme MotollaNo ratings yet
- 4260P - Use of School Facilities ProcedureDocument6 pages4260P - Use of School Facilities ProcedureAnthony RodriguezNo ratings yet
- Dirtside - Science-Fiction Combat Rules For 1-300 (6mm) Scale - 1989 - Optimized - OCR - RevisedDocument38 pagesDirtside - Science-Fiction Combat Rules For 1-300 (6mm) Scale - 1989 - Optimized - OCR - RevisedNeal Baedke100% (2)
- Orleans Jail Jan 19 ReportDocument111 pagesOrleans Jail Jan 19 ReportEthan BrownNo ratings yet
- Marketing Presentatio N: CadburyDocument17 pagesMarketing Presentatio N: CadburyHARSH SHUKLANo ratings yet
- Las Week 5Document6 pagesLas Week 5Muzically Inspired100% (1)
- Computer Integrated Manufacturing SystemDocument12 pagesComputer Integrated Manufacturing Systemabemat100% (1)
- City Union Bank FormatDocument4 pagesCity Union Bank FormatRaja RajanNo ratings yet
- Essential Components of Business AcumenDocument2 pagesEssential Components of Business AcumenYazad DoctorrNo ratings yet
- HDFC Bank-Analyse Its Organisational Structure and Find IssuesDocument6 pagesHDFC Bank-Analyse Its Organisational Structure and Find IssuesTapash DekaNo ratings yet
- Family Courts: Origin in IndiaDocument2 pagesFamily Courts: Origin in IndiaaasdsfasfNo ratings yet
- Wickberg, Daniel - Intellectual History vs. The Social History of Intellectuals, 2001Document14 pagesWickberg, Daniel - Intellectual History vs. The Social History of Intellectuals, 2001carlosusassNo ratings yet
- Pita Vs CaDocument8 pagesPita Vs CaBasri JayNo ratings yet
- Us - Uk History and CultureDocument59 pagesUs - Uk History and CultureMohamed BouladamNo ratings yet
- International Human Resource Management.: Exit & Stay InterviewDocument20 pagesInternational Human Resource Management.: Exit & Stay InterviewbharathchowriraNo ratings yet
- Ayush Raj Singh - COA - Mini ProjectDocument16 pagesAyush Raj Singh - COA - Mini ProjectAyush Raj SinghNo ratings yet
- Elements of Criminal LiabilityDocument9 pagesElements of Criminal LiabilitydiannedensonNo ratings yet
- GEcc 1 - Purposive Communication - Aug 17 - 29lesson - First SemDocument3 pagesGEcc 1 - Purposive Communication - Aug 17 - 29lesson - First SemChiesa ArellanoNo ratings yet
- The Culture Environments Facing BusinessDocument5 pagesThe Culture Environments Facing BusinessAnuranjanSinhaNo ratings yet
- Assignment: South Eastern University of Sri LankaDocument12 pagesAssignment: South Eastern University of Sri LankaHasanthikaNo ratings yet
- Banner, Brochure, Leaflet, and PhampletDocument20 pagesBanner, Brochure, Leaflet, and Phampletnurul husniahNo ratings yet
- Thayer Challenges For Vietnam's New Cabinet MinistersDocument3 pagesThayer Challenges For Vietnam's New Cabinet MinistersCarlyle Alan ThayerNo ratings yet
- Supply Chain - Introduction: Rosalin RubaraniDocument17 pagesSupply Chain - Introduction: Rosalin RubaranipremNo ratings yet
- 9steps Drawing Architectural Plan DWG Format4Document63 pages9steps Drawing Architectural Plan DWG Format4Shreyansh JainNo ratings yet
- Prelim Module Teaching Science in The Elem GradesDocument28 pagesPrelim Module Teaching Science in The Elem GradesLemuel Aying100% (3)
- Rethinking Dubai's UrbanismDocument14 pagesRethinking Dubai's UrbanismIbrahim AlsayedNo ratings yet
- 09 - San Juan vs. People, May 30, 2011Document2 pages09 - San Juan vs. People, May 30, 2011Nica Cielo B. Libunao100% (1)
- Punjab 2016Document4,298 pagesPunjab 2016Yanamandra Radha Phani ShankarNo ratings yet
- Writing A Travel EssayDocument2 pagesWriting A Travel EssayJohnmark Dagsa FalcoteloNo ratings yet
- Dropping and Home Visitation FormDocument3 pagesDropping and Home Visitation Formmary ann s. nunag100% (1)
- Projects, The Cutting Edge of DevelopmentDocument28 pagesProjects, The Cutting Edge of DevelopmentMerkebu NIgusieNo ratings yet
- Age of Revolutions: Progress and Backlash from 1600 to the PresentFrom EverandAge of Revolutions: Progress and Backlash from 1600 to the PresentRating: 4.5 out of 5 stars4.5/5 (8)
- Prisoners of Geography: Ten Maps That Explain Everything About the WorldFrom EverandPrisoners of Geography: Ten Maps That Explain Everything About the WorldRating: 4.5 out of 5 stars4.5/5 (1147)
- The War after the War: A New History of ReconstructionFrom EverandThe War after the War: A New History of ReconstructionRating: 5 out of 5 stars5/5 (2)
- For Love of Country: Leave the Democrat Party BehindFrom EverandFor Love of Country: Leave the Democrat Party BehindRating: 5 out of 5 stars5/5 (4)
- Son of Hamas: A Gripping Account of Terror, Betrayal, Political Intrigue, and Unthinkable ChoicesFrom EverandSon of Hamas: A Gripping Account of Terror, Betrayal, Political Intrigue, and Unthinkable ChoicesRating: 4.5 out of 5 stars4.5/5 (504)
- Pagan America: The Decline of Christianity and the Dark Age to ComeFrom EverandPagan America: The Decline of Christianity and the Dark Age to ComeRating: 5 out of 5 stars5/5 (2)
- The Franklin Scandal: A Story of Powerbrokers, Child Abuse & BetrayalFrom EverandThe Franklin Scandal: A Story of Powerbrokers, Child Abuse & BetrayalRating: 4.5 out of 5 stars4.5/5 (45)
- The Russia Hoax: The Illicit Scheme to Clear Hillary Clinton and Frame Donald TrumpFrom EverandThe Russia Hoax: The Illicit Scheme to Clear Hillary Clinton and Frame Donald TrumpRating: 4.5 out of 5 stars4.5/5 (11)
- How States Think: The Rationality of Foreign PolicyFrom EverandHow States Think: The Rationality of Foreign PolicyRating: 5 out of 5 stars5/5 (7)
- Heretic: Why Islam Needs a Reformation NowFrom EverandHeretic: Why Islam Needs a Reformation NowRating: 4 out of 5 stars4/5 (57)
- Compromised: Counterintelligence and the Threat of Donald J. TrumpFrom EverandCompromised: Counterintelligence and the Threat of Donald J. TrumpRating: 4 out of 5 stars4/5 (18)
- How to Destroy America in Three Easy StepsFrom EverandHow to Destroy America in Three Easy StepsRating: 4.5 out of 5 stars4.5/5 (21)
- You Can't Joke About That: Why Everything Is Funny, Nothing Is Sacred, and We're All in This TogetherFrom EverandYou Can't Joke About That: Why Everything Is Funny, Nothing Is Sacred, and We're All in This TogetherNo ratings yet
- The Smear: How Shady Political Operatives and Fake News Control What You See, What You Think, and How You VoteFrom EverandThe Smear: How Shady Political Operatives and Fake News Control What You See, What You Think, and How You VoteRating: 4.5 out of 5 stars4.5/5 (16)
- Bind, Torture, Kill: The Inside Story of BTK, the Serial Killer Next DoorFrom EverandBind, Torture, Kill: The Inside Story of BTK, the Serial Killer Next DoorRating: 3.5 out of 5 stars3.5/5 (77)
- Modern Warriors: Real Stories from Real HeroesFrom EverandModern Warriors: Real Stories from Real HeroesRating: 3.5 out of 5 stars3.5/5 (3)
- Uncontrolled Spread: Why COVID-19 Crushed Us and How We Can Defeat the Next PandemicFrom EverandUncontrolled Spread: Why COVID-19 Crushed Us and How We Can Defeat the Next PandemicNo ratings yet
- The Return of George Washington: Uniting the States, 1783–1789From EverandThe Return of George Washington: Uniting the States, 1783–1789Rating: 4 out of 5 stars4/5 (22)
- Revenge: How Donald Trump Weaponized the US Department of Justice Against His CriticsFrom EverandRevenge: How Donald Trump Weaponized the US Department of Justice Against His CriticsRating: 4.5 out of 5 stars4.5/5 (60)
- Warnings: Finding Cassandras to Stop CatastrophesFrom EverandWarnings: Finding Cassandras to Stop CatastrophesRating: 4 out of 5 stars4/5 (10)
- From Cold War To Hot Peace: An American Ambassador in Putin's RussiaFrom EverandFrom Cold War To Hot Peace: An American Ambassador in Putin's RussiaRating: 4 out of 5 stars4/5 (23)
- The Courage to Be Free: Florida's Blueprint for America's RevivalFrom EverandThe Courage to Be Free: Florida's Blueprint for America's RevivalNo ratings yet
- Stonewalled: My Fight for Truth Against the Forces of Obstruction, Intimidation, and Harassment in Obama's WashingtonFrom EverandStonewalled: My Fight for Truth Against the Forces of Obstruction, Intimidation, and Harassment in Obama's WashingtonRating: 4.5 out of 5 stars4.5/5 (21)