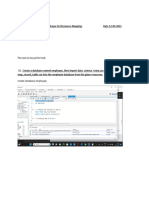
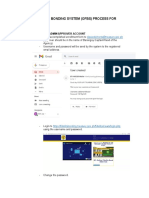
You might also like
- Querying with SQL T-SQL for Microsoft SQL ServerFrom EverandQuerying with SQL T-SQL for Microsoft SQL ServerRating: 2.5 out of 5 stars2.5/5 (4)
- L4 Functions Manipulating Character ValuesDocument10 pagesL4 Functions Manipulating Character ValuesHarvey HayesNo ratings yet
- Base SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandBase SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Internal Tables:: APPEND Gwa - Student TO ItDocument20 pagesInternal Tables:: APPEND Gwa - Student TO ItUday SagarNo ratings yet
- L1 Controlling Input and OutputDocument14 pagesL1 Controlling Input and OutputHarvey HayesNo ratings yet
- 2 Sap Internel TableDocument23 pages2 Sap Internel Tableidrees aliNo ratings yet
- Creating Dynamic Internal TableDocument8 pagesCreating Dynamic Internal TableEldior SolutionsNo ratings yet
- Topic: The SET, MERGE, UPDATE StatementsDocument10 pagesTopic: The SET, MERGE, UPDATE StatementsAymen KortasNo ratings yet
- Sas 1Document50 pagesSas 1pratyusa100% (2)
- Day 1Document13 pagesDay 1Hanzel CorneliaNo ratings yet
- Internal TablesDocument17 pagesInternal TablesphanikumarpujyamNo ratings yet
- stata应用课程 回归Document50 pagesstata应用课程 回归Mengdi ShiNo ratings yet
- L2 Summarizing DataDocument9 pagesL2 Summarizing DataHarvey Hayes100% (2)
- Data Modification TipsDocument3 pagesData Modification TipsKv NarayanaNo ratings yet
- SasDocument36 pagesSasGurteg SinghNo ratings yet
- SQL Q ADocument15 pagesSQL Q AprashantNo ratings yet
- SQL Project ScienceQtech Employee Performance Mapping...Document14 pagesSQL Project ScienceQtech Employee Performance Mapping...Sushii Killing machineNo ratings yet
- Top 100 SAS Interview Questions and Answers For 2022Document22 pagesTop 100 SAS Interview Questions and Answers For 2022Murali Krishna ReddyNo ratings yet
- Performance TunningDocument7 pagesPerformance TunningSreenivasulu Reddy SanamNo ratings yet
- Assignment 3Document30 pagesAssignment 3Shivangi MahuleNo ratings yet
- Debugging SAS Programs A Handbook of Tools and TechniquesDocument7 pagesDebugging SAS Programs A Handbook of Tools and Techniquesnishu_aminNo ratings yet
- SAPTech - 2017Document41 pagesSAPTech - 2017Arun Varshney (MULAYAM)No ratings yet
- How Can I Implement Row Level Security in Peoplesoft CRM v8.8Document7 pagesHow Can I Implement Row Level Security in Peoplesoft CRM v8.8chakripsNo ratings yet
- SQL MikeDaneDocument7 pagesSQL MikeDaneKaran ShahNo ratings yet
- DB Assignement 2Document17 pagesDB Assignement 2BilisumaNo ratings yet
- Project 3 - Case Study Part 2 - MS AccessDocument6 pagesProject 3 - Case Study Part 2 - MS Accessesmiwuals0% (1)
- OLE Excel Document Creation and FormatingDocument7 pagesOLE Excel Document Creation and FormatinglpedrerosaNo ratings yet
- 5reading Excel WorksheetsDocument42 pages5reading Excel Worksheetsrishabhindore2009No ratings yet
- Alv 11Document56 pagesAlv 11mukesh0286No ratings yet
- Assignment Description.: Language: Oracle SQL. Level: Advanced. Price: 100$Document13 pagesAssignment Description.: Language: Oracle SQL. Level: Advanced. Price: 100$sadiya siddiquaNo ratings yet
- ADBMSDocument6 pagesADBMSKaushik GhoshNo ratings yet
- Base SAS Interview QuestionsDocument26 pagesBase SAS Interview Questionsmamatha_mba269690No ratings yet
- 20BDS0174 VL2022230503449 DaDocument19 pages20BDS0174 VL2022230503449 DaDev Rishi ThakurNo ratings yet
- How To... Create and Delete Info Packages With BAPIDocument10 pagesHow To... Create and Delete Info Packages With BAPIyshriniNo ratings yet
- SQL Notse-172-249Document78 pagesSQL Notse-172-249Suribabu VNo ratings yet
- Two Field DeltaDocument8 pagesTwo Field Deltamara_ferraz_8No ratings yet
- CS311 Introduction To Database Systems: Usman Institute of Technology Department of Computer ScienceDocument10 pagesCS311 Introduction To Database Systems: Usman Institute of Technology Department of Computer ScienceBarkatNo ratings yet
- A066 PA PractDocument8 pagesA066 PA PractYash JadhavNo ratings yet
- Department of Economics: ECONOMICS 481: Economics Research Paper and SeminarDocument15 pagesDepartment of Economics: ECONOMICS 481: Economics Research Paper and SeminarHan ZhongNo ratings yet
- Practical No. 9: Aim: To Explicitly Control The Output of Multiple Observations To A SAS Data Set and CreateDocument2 pagesPractical No. 9: Aim: To Explicitly Control The Output of Multiple Observations To A SAS Data Set and Createrahul PatelNo ratings yet
- Maulidya Yunanda Practice Sec 5 6Document19 pagesMaulidya Yunanda Practice Sec 5 6maulidyayunandaNo ratings yet
- Example Varant Pointer S71500, TIA V13Document4 pagesExample Varant Pointer S71500, TIA V13PepitoPerezNo ratings yet
- Summary of Lesson 4: Producing Detail Reports: Topic SummariesDocument4 pagesSummary of Lesson 4: Producing Detail Reports: Topic SummariesreussiteNo ratings yet
- Lab Assignment 6 ViewsDocument52 pagesLab Assignment 6 ViewsRienzi Adrienne VillenoNo ratings yet
- ALV Easy TutorialDocument61 pagesALV Easy TutorialGabriel MagalhãesNo ratings yet
- Two SPSS Programs For Interpreting Multiple Regression ResultsDocument5 pagesTwo SPSS Programs For Interpreting Multiple Regression Resultsmattyoung2003No ratings yet
- IndexDocument38 pagesIndexNIZAR MOHAMMEDNo ratings yet
- 8 Uses of Proc FormatDocument12 pages8 Uses of Proc FormatRenu PareekNo ratings yet
- 45677777MySQL - All Basics Query by Using PopSQL Text EditorDocument22 pages45677777MySQL - All Basics Query by Using PopSQL Text EditorMahadevamma S100% (1)
- OMT QuizDocument9 pagesOMT Quizwarriorsoul1029No ratings yet
- Share 'Unit-III Ds - Docx'Document65 pagesShare 'Unit-III Ds - Docx'yashwanth gunisettyNo ratings yet
- Module Pool ProgrammingDocument69 pagesModule Pool ProgrammingGnaneswari KumaresanNo ratings yet
- Oracle PLSQL NotesDocument59 pagesOracle PLSQL Notesdatastage_dwh100% (4)
- Base Sas Certification ExerciseDocument47 pagesBase Sas Certification ExercisesvidhyaghantasalaNo ratings yet
- Base Sas Certification ExerciseDocument47 pagesBase Sas Certification ExerciseErshad ShaikNo ratings yet
- Lab Manuals DDBSDocument67 pagesLab Manuals DDBSzubair100% (1)
- Practice Session - 1Document1 pagePractice Session - 1Rajesh KumarNo ratings yet
- COMP9313: Big Data Management: Course Web Site: HTTP://WWW - Cse.unsw - Edu.au/ cs9313Document76 pagesCOMP9313: Big Data Management: Course Web Site: HTTP://WWW - Cse.unsw - Edu.au/ cs9313maithuong85No ratings yet
- Radio Electronics December 1989 PDFDocument100 pagesRadio Electronics December 1989 PDFManny De GuzmanJrNo ratings yet
- Analizador Termogravinetrico Modelo TGA701 - V1-3x - 3-08Document308 pagesAnalizador Termogravinetrico Modelo TGA701 - V1-3x - 3-08Yafer HassanNo ratings yet
- Pembimbing Kti Ta Kelas Xii Tahun Pelajaran 2021-2022Document33 pagesPembimbing Kti Ta Kelas Xii Tahun Pelajaran 2021-2022Alifudin KhumaidiNo ratings yet
- FL-10 User Manual: (Economic/Basic AVL Terminal)Document42 pagesFL-10 User Manual: (Economic/Basic AVL Terminal)Roberto Agustin Ramos PattersonNo ratings yet
- Automatic Seeding in Always On Availability Groups 1598681906Document9 pagesAutomatic Seeding in Always On Availability Groups 1598681906Naheed HossainNo ratings yet
- Memory Verification Using UVMDocument13 pagesMemory Verification Using UVMAnji medidiNo ratings yet
- Laravel FW-PHP s02Document15 pagesLaravel FW-PHP s02Ngo Quoc Khanh (Aptech HCM)No ratings yet
- OBIEE Interview Questions Part - 1Document5 pagesOBIEE Interview Questions Part - 1VHP tubeNo ratings yet
- CS220-Database Systems!: Dr. Seema JehanDocument50 pagesCS220-Database Systems!: Dr. Seema JehanhgjNo ratings yet
- Manual EA GREEDY REDDocument13 pagesManual EA GREEDY REDsuyono100% (1)
- AllDSP ALLControl User MafnualDocument21 pagesAllDSP ALLControl User MafnualRui Miguel FerreiraNo ratings yet
- SG AlgorithmsDocument31 pagesSG AlgorithmsAmira AlwahshiNo ratings yet
- Logix 5000 Controllers Nonvolatile Memory Card: Programming ManualDocument31 pagesLogix 5000 Controllers Nonvolatile Memory Card: Programming Manualjoao alexandre correaNo ratings yet
- Azure CommandsDocument5 pagesAzure Commandsrajgopalv2No ratings yet
- MR DJ Repacks ListDocument1 pageMR DJ Repacks ListMike Wasauski0% (1)
- TTRPG Resources 1.9Document6 pagesTTRPG Resources 1.9PeterNo ratings yet
- Introduction To Information Systems Canadian 4th Edition Rainer Test BankDocument30 pagesIntroduction To Information Systems Canadian 4th Edition Rainer Test BankJenniferMartinezxtafr100% (10)
- Demco EASIZON Conventional Fire Alarm PanelDocument4 pagesDemco EASIZON Conventional Fire Alarm PanelThein TunNo ratings yet
- Test Bank For Linux and Lpic 1 Guide To Linux Certification 5th Edition Jason EckertDocument19 pagesTest Bank For Linux and Lpic 1 Guide To Linux Certification 5th Edition Jason Eckertzoundsstriklegnth100% (44)
- Manual For Barangays Application For Fidelity BondDocument7 pagesManual For Barangays Application For Fidelity BondChekay PayaoNo ratings yet
- Archmodels Vol 109 Doors & WindowsDocument36 pagesArchmodels Vol 109 Doors & Windowsgombestralala100% (1)
- PyCUDA AH PDFDocument16 pagesPyCUDA AH PDFjackopsNo ratings yet
- Delta Psc3 Configuration and SW UpgradeDocument11 pagesDelta Psc3 Configuration and SW UpgradeAlayn1807No ratings yet
- Regedit 2Document8 pagesRegedit 2smokeZ12No ratings yet
- Radovan Bast - CMake CookbookDocument758 pagesRadovan Bast - CMake Cookbookunknown100% (1)
- Whitepaper BDR3 2ndquadrant Feb2020Document10 pagesWhitepaper BDR3 2ndquadrant Feb2020Steph ChrisNo ratings yet
- 1st Grade Math Lessons: More Math Interactive WorksheetsDocument1 page1st Grade Math Lessons: More Math Interactive WorksheetsBradyn JongNo ratings yet
- Methods-Overload OverrideDocument19 pagesMethods-Overload Overridesiddhant kudesiaNo ratings yet
- An Introduction To PhotoshopDocument8 pagesAn Introduction To PhotoshopArvic Omila LasacaNo ratings yet
- Microsoft 365 Guide to Success: 10 Books in 1 | Kick-start Your Career Learning the Key Information to Master Your Microsoft Office Files to Optimize Your Tasks & Surprise Your Colleagues | Access, Excel, OneDrive, Outlook, PowerPoint, Word, Teams, etc.From EverandMicrosoft 365 Guide to Success: 10 Books in 1 | Kick-start Your Career Learning the Key Information to Master Your Microsoft Office Files to Optimize Your Tasks & Surprise Your Colleagues | Access, Excel, OneDrive, Outlook, PowerPoint, Word, Teams, etc.Rating: 5 out of 5 stars5/5 (3)
- Learn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.From EverandLearn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.Rating: 5 out of 5 stars5/5 (34)
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceFrom EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceNo ratings yet
- Microsoft Excel Guide for Success: Transform Your Work with Microsoft Excel, Unleash Formulas, Functions, and Charts to Optimize Tasks and Surpass Expectations [II EDITION]From EverandMicrosoft Excel Guide for Success: Transform Your Work with Microsoft Excel, Unleash Formulas, Functions, and Charts to Optimize Tasks and Surpass Expectations [II EDITION]Rating: 5 out of 5 stars5/5 (3)
- How to Make a Video Game All By Yourself: 10 steps, just you and a computerFrom EverandHow to Make a Video Game All By Yourself: 10 steps, just you and a computerRating: 5 out of 5 stars5/5 (1)
- Understanding Software: Max Kanat-Alexander on simplicity, coding, and how to suck less as a programmerFrom EverandUnderstanding Software: Max Kanat-Alexander on simplicity, coding, and how to suck less as a programmerRating: 4.5 out of 5 stars4.5/5 (44)
- Clean Code: A Handbook of Agile Software CraftsmanshipFrom EverandClean Code: A Handbook of Agile Software CraftsmanshipRating: 5 out of 5 stars5/5 (13)
- Microsoft PowerPoint Guide for Success: Learn in a Guided Way to Create, Edit & Format Your Presentations Documents to Visual Explain Your Projects & Surprise Your Bosses And Colleagues | Big Four Consulting Firms MethodFrom EverandMicrosoft PowerPoint Guide for Success: Learn in a Guided Way to Create, Edit & Format Your Presentations Documents to Visual Explain Your Projects & Surprise Your Bosses And Colleagues | Big Four Consulting Firms MethodRating: 5 out of 5 stars5/5 (5)
- Microsoft OneNote Guide to Success: Learn In A Guided Way How To Take Digital Notes To Optimize Your Understanding, Tasks, And Projects, Surprising Your Colleagues And ClientsFrom EverandMicrosoft OneNote Guide to Success: Learn In A Guided Way How To Take Digital Notes To Optimize Your Understanding, Tasks, And Projects, Surprising Your Colleagues And ClientsRating: 5 out of 5 stars5/5 (3)
- PYTHON PROGRAMMING: A Beginner’s Guide To Learn Python From ZeroFrom EverandPYTHON PROGRAMMING: A Beginner’s Guide To Learn Python From ZeroRating: 5 out of 5 stars5/5 (1)
- Nine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersFrom EverandNine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersRating: 5 out of 5 stars5/5 (8)
- A Slackers Guide to Coding with Python: Ultimate Beginners Guide to Learning Python QuickFrom EverandA Slackers Guide to Coding with Python: Ultimate Beginners Guide to Learning Python QuickNo ratings yet
- Linux: The Ultimate Beginner's Guide to Learn Linux Operating System, Command Line and Linux Programming Step by StepFrom EverandLinux: The Ultimate Beginner's Guide to Learn Linux Operating System, Command Line and Linux Programming Step by StepRating: 4.5 out of 5 stars4.5/5 (9)
- Python Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionFrom EverandPython Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionRating: 5 out of 5 stars5/5 (2)
- Optimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesFrom EverandOptimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesNo ratings yet
- The Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!From EverandThe Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!Rating: 4.5 out of 5 stars4.5/5 (2)
- Once Upon an Algorithm: How Stories Explain ComputingFrom EverandOnce Upon an Algorithm: How Stories Explain ComputingRating: 4 out of 5 stars4/5 (43)
- Competing in the Age of AI: Strategy and Leadership When Algorithms and Networks Run the WorldFrom EverandCompeting in the Age of AI: Strategy and Leadership When Algorithms and Networks Run the WorldRating: 4.5 out of 5 stars4.5/5 (21)
- Learn Algorithmic Trading: Build and deploy algorithmic trading systems and strategies using Python and advanced data analysisFrom EverandLearn Algorithmic Trading: Build and deploy algorithmic trading systems and strategies using Python and advanced data analysisNo ratings yet
- Microservices Patterns: With examples in JavaFrom EverandMicroservices Patterns: With examples in JavaRating: 5 out of 5 stars5/5 (2)
- Visual Studio Code: End-to-End Editing and Debugging Tools for Web DevelopersFrom EverandVisual Studio Code: End-to-End Editing and Debugging Tools for Web DevelopersNo ratings yet