You might also like
- Econometery ch2Document38 pagesEconometery ch2Abel AbelNo ratings yet
- YearDocument43 pagesYeartassawarNo ratings yet
- Heteroscedasticity3 150218115247 Conversion Gate01Document10 pagesHeteroscedasticity3 150218115247 Conversion Gate01LWANGA FRANCISNo ratings yet
- Hsts423 Unit 4Document13 pagesHsts423 Unit 4Keith Tanyaradzwa MushiningaNo ratings yet
- Testing A Correlation Coefficient's Significance: Using H: 0 U D O Is Preferable To H: U 0Document14 pagesTesting A Correlation Coefficient's Significance: Using H: 0 U D O Is Preferable To H: U 0Saurav GhoshalNo ratings yet
- BSM by ProsDocument16 pagesBSM by Prossediha5178No ratings yet
- Chapter 4Document47 pagesChapter 4Desala HabteNo ratings yet
- CHEMOM2255 v103 160Document12 pagesCHEMOM2255 v103 160PoornimaNo ratings yet
- ETW2510 Lecture 8 HeteroskedasticityDocument29 pagesETW2510 Lecture 8 HeteroskedasticityLow Wai LeongNo ratings yet
- Statistical Properties of OLSDocument59 pagesStatistical Properties of OLSEvgenIy BokhonNo ratings yet
- Assignment 1 StatisticsDocument6 pagesAssignment 1 Statisticsjaspreet46No ratings yet
- Reality of The WavefunctionDocument7 pagesReality of The WavefunctiondNo ratings yet
- Chapter 1Document106 pagesChapter 1WondmageneUrgessaNo ratings yet
- Bivariate Poissson CountDocument18 pagesBivariate Poissson Countray raylandeNo ratings yet
- Unit 6. Heteroscedasticity: María José Olmo JiménezDocument9 pagesUnit 6. Heteroscedasticity: María José Olmo JiménezAlex LovisottoNo ratings yet
- JKG 2011 AsDocument29 pagesJKG 2011 AsAsmita BhandariNo ratings yet
- BRM AssignmentDocument26 pagesBRM AssignmentVivek GuptaNo ratings yet
- Econ 335 Wooldridge CH 8 HeteroskedasticityDocument23 pagesEcon 335 Wooldridge CH 8 Heteroskedasticityminhly12104No ratings yet
- CH - 5 - Econometrics UGDocument24 pagesCH - 5 - Econometrics UGMewded DelelegnNo ratings yet
- IGNOU MBA Note On Statistics For ManagementDocument23 pagesIGNOU MBA Note On Statistics For Managementravvig100% (2)
- What Is Econometrics?: (Ref: Wooldridge, Chapter 1)Document11 pagesWhat Is Econometrics?: (Ref: Wooldridge, Chapter 1)universedrillNo ratings yet
- Heteros Kedas T I CityDocument9 pagesHeteros Kedas T I Citynai09No ratings yet
- Identification Through Heteroskedasticity.1 Roberto Rigobon Sloan School of Management, MIT and NBER June 20, 2002Document32 pagesIdentification Through Heteroskedasticity.1 Roberto Rigobon Sloan School of Management, MIT and NBER June 20, 2002noor ul hqNo ratings yet
- Eco 401 Econometrics: SI 2021, Week 8, 2 November 2021Document43 pagesEco 401 Econometrics: SI 2021, Week 8, 2 November 2021Jerry maNo ratings yet
- ©the Mcgraw-Hill Companies, Inc. 2008 Mcgraw-Hill/IrwinDocument20 pages©the Mcgraw-Hill Companies, Inc. 2008 Mcgraw-Hill/IrwinQurat-ul- ainNo ratings yet
- HSTS423 - Unit 5 MulticolinearityDocument12 pagesHSTS423 - Unit 5 MulticolinearityTenday ChadokaNo ratings yet
- Mathematics and StatisticsDocument3 pagesMathematics and StatisticsRathan SantoshNo ratings yet
- Generalized Least Squares: Simon Jackman Stanford UniversityDocument3 pagesGeneralized Least Squares: Simon Jackman Stanford Universityrvalecha6446No ratings yet
- Statistic SimpleLinearRegressionDocument7 pagesStatistic SimpleLinearRegressionmfah00No ratings yet
- 10.1524 stnd.2006.24.1.1Document25 pages10.1524 stnd.2006.24.1.1zainab alshatterNo ratings yet
- Regresia Multipla (1) - Modelare, Interpretare Si TestareDocument10 pagesRegresia Multipla (1) - Modelare, Interpretare Si TestareDelia RaduNo ratings yet
- Econometrics ModuleDocument79 pagesEconometrics ModuleTariku GutaNo ratings yet
- Quantum Probabilities As Bayesian ProbabilitiesDocument6 pagesQuantum Probabilities As Bayesian ProbabilitiesmelanocitosNo ratings yet
- Two Mark Question and Answers: SRM Institute of Science and TechnologyDocument9 pagesTwo Mark Question and Answers: SRM Institute of Science and TechnologykeerthiiNo ratings yet
- Lec6 V1Document35 pagesLec6 V1Bokul HossainNo ratings yet
- Generalized Gleason Theorem and Contextuality: 1 2 M M N 1 N K KDocument8 pagesGeneralized Gleason Theorem and Contextuality: 1 2 M M N 1 N K KjrashidNo ratings yet
- Randomness Vs Non Locality and Entanglement: Antonio Ac In, Serge Massar, Stefano PironioDocument12 pagesRandomness Vs Non Locality and Entanglement: Antonio Ac In, Serge Massar, Stefano PironioPaul BertolNo ratings yet
- Least Squares in Calibration: Dealing With Uncertainty in X: The Analyst August 2010Document31 pagesLeast Squares in Calibration: Dealing With Uncertainty in X: The Analyst August 2010keynote76No ratings yet
- BAStutorial Linear RegressionDocument30 pagesBAStutorial Linear RegressionLuis LuengoNo ratings yet
- Basic Econometrics: TWO-VARIABLEREGRESSION MODELDocument35 pagesBasic Econometrics: TWO-VARIABLEREGRESSION MODELsebastianNo ratings yet
- Probability and Probability DistributionsDocument27 pagesProbability and Probability DistributionsAyushi TanwarNo ratings yet
- RELAXING ASSUMPTIONS OF CLRMsDocument75 pagesRELAXING ASSUMPTIONS OF CLRMswebeshet bekeleNo ratings yet
- Week1 Lecture2Document57 pagesWeek1 Lecture2Panagiotis Ballis-PapanastasiouNo ratings yet
- Extreme Value Theory in Finance: Erik Brodin Claudia KL UppelbergDocument14 pagesExtreme Value Theory in Finance: Erik Brodin Claudia KL UppelbergAqeela FatimaNo ratings yet
- Rou 0194Document26 pagesRou 0194bahaalamore200No ratings yet
- Chapter Two of Econometrics I-1Document22 pagesChapter Two of Econometrics I-1Yetsedaw KindieNo ratings yet
- Clinical-Social-Personality: A Agreement Scales 1Document10 pagesClinical-Social-Personality: A Agreement Scales 1jeff bozoNo ratings yet
- Abu HorayraDocument11 pagesAbu HorayraAbu HorayraNo ratings yet
- Chapter 4-Volation Final Last 2018Document105 pagesChapter 4-Volation Final Last 2018Getacher NiguseNo ratings yet
- HeteroskedasticityDocument20 pagesHeteroskedasticityfffkpmdqx9No ratings yet
- Further Regression Topics IIDocument32 pagesFurther Regression Topics IIthrphys1940No ratings yet
- Board of The Foundation of The Scandinavian Journal of StatisticsDocument7 pagesBoard of The Foundation of The Scandinavian Journal of StatisticslacisagNo ratings yet
- ST2187 Block 5Document15 pagesST2187 Block 5Joseph MatthewNo ratings yet
- Introductory Econometrics: Multiple Regression: InferenceDocument38 pagesIntroductory Econometrics: Multiple Regression: Inferencechanlego123No ratings yet
- DiTommasoCristian RiskAndUncertainty IndividualRiskPerceptionDocument9 pagesDiTommasoCristian RiskAndUncertainty IndividualRiskPerceptionLeonardo SimonciniNo ratings yet
- (Statistics Amp Risk Modeling) Risk Measurement With Equivalent Utility PrinciplesDocument25 pages(Statistics Amp Risk Modeling) Risk Measurement With Equivalent Utility PrinciplesWiko Rizki WijayaNo ratings yet
- Heteroscedasticity NotesDocument9 pagesHeteroscedasticity NotesDenise Myka TanNo ratings yet
- TWO-VARIABLE NewDocument19 pagesTWO-VARIABLE NewAbhimanyu VermaNo ratings yet
- Determinants of External Auditors' Independence: A Case Study On Ethiopian Authorized Audit FirmsDocument16 pagesDeterminants of External Auditors' Independence: A Case Study On Ethiopian Authorized Audit Firmsiaset123No ratings yet
- Lean Six Sigma TemplateDocument908 pagesLean Six Sigma TemplateBalaji S100% (3)
- Quasi Maximum Likelihood Theory - Lecture NotesDocument119 pagesQuasi Maximum Likelihood Theory - Lecture NotesAnonymous tsTtieMHDNo ratings yet
- ECOM053 Quantitative Methods For FinanceDocument4 pagesECOM053 Quantitative Methods For Financedo3ukan3pusat3i33kNo ratings yet
- 17.874 Lecture Notes Part 6: Panel ModelsDocument13 pages17.874 Lecture Notes Part 6: Panel ModelsArmin BehbahanianNo ratings yet
- 6 RegresieDocument6 pages6 RegresieStefan CatalinNo ratings yet
- 1999 Anselin Spatial Eonometrics PDFDocument31 pages1999 Anselin Spatial Eonometrics PDFArv1ndNo ratings yet
- Week 4 - EViews Practice NoteDocument13 pagesWeek 4 - EViews Practice NoteChip choiNo ratings yet
- The Influence of Work Discipline, Self-Efficacy and Work Environment On Employee Performance in The Building Plant D Department at PT Gajah Tunggal TBKDocument8 pagesThe Influence of Work Discipline, Self-Efficacy and Work Environment On Employee Performance in The Building Plant D Department at PT Gajah Tunggal TBKInternational Journal of Innovative Science and Research TechnologyNo ratings yet
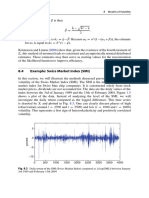
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- Road Vs RailDocument17 pagesRoad Vs RailAynup IrahtakNo ratings yet
- Chapter 2 - Quantitative AnalysisDocument244 pagesChapter 2 - Quantitative AnalysisCHAN StephenieNo ratings yet
- CJ EconometricsDocument6 pagesCJ EconometricsLow Wai LeongNo ratings yet
- Phan I - C5a-Breakdown of OLS AssumptionsDocument35 pagesPhan I - C5a-Breakdown of OLS Assumptionspham nguyetNo ratings yet
- β β X, X σ X X X: Simposium Nasional Akuntansi ViDocument12 pagesβ β X, X σ X X X: Simposium Nasional Akuntansi ViNicholas AlexanderNo ratings yet
- IB - 306: Econometrics Department of International BusinessDocument6 pagesIB - 306: Econometrics Department of International BusinessRimon IslamNo ratings yet
- The Effect of Food Expenditure To The Total of Household ExpenditureDocument12 pagesThe Effect of Food Expenditure To The Total of Household ExpenditureBELVA ATHAYA ALZENANo ratings yet
- Final-Factors Lead SensationalismDocument20 pagesFinal-Factors Lead SensationalismRozina ImtiazNo ratings yet
- 2014 Mock Exam - AM - QuestionDocument30 pages2014 Mock Exam - AM - Question12jdNo ratings yet
- Factors Affecting Consumer Interest in Choosing A Coffee Store in Tangerang DistrictDocument13 pagesFactors Affecting Consumer Interest in Choosing A Coffee Store in Tangerang Districtriro farNo ratings yet
- Panel CookbookDocument98 pagesPanel CookbookMaruška VizekNo ratings yet
- CHAPTER TWO-Econometrics I (Econ 2061) Edited1 PDFDocument35 pagesCHAPTER TWO-Econometrics I (Econ 2061) Edited1 PDFanwar muhammedNo ratings yet
- Coefficient Std. Error T-Ratio P-Value: Running OLS On DataDocument15 pagesCoefficient Std. Error T-Ratio P-Value: Running OLS On DataAadil ZamanNo ratings yet
- A Review of The Theoretical and Empirical Basis of Financial Ratio AnalysisDocument36 pagesA Review of The Theoretical and Empirical Basis of Financial Ratio AnalysisMohammed Ali Askar100% (4)
- Fundamentals of Forecasting Using Excel: Dr. Kenneth D. Lawrence Dr. Ronald K. Klimberg Dr. Sheila M. LawrenceDocument7 pagesFundamentals of Forecasting Using Excel: Dr. Kenneth D. Lawrence Dr. Ronald K. Klimberg Dr. Sheila M. Lawrencenauli10No ratings yet
- Heteroscedasticity IssueDocument3 pagesHeteroscedasticity IssueShadman Sakib100% (2)
- Lab Introduction To STATADocument27 pagesLab Introduction To STATAAfifNo ratings yet
- The Performance of Tourism Sector and Economic Growth in Nigeria (1996-2010)Document5 pagesThe Performance of Tourism Sector and Economic Growth in Nigeria (1996-2010)erpublicationNo ratings yet
- CH 07Document21 pagesCH 07이재훈No ratings yet