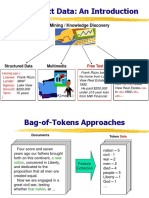
You might also like
- Web MiningDocument100 pagesWeb MiningMADHURA HARSHENo ratings yet
- Text MiningDocument27 pagesText MiningAchyuth PentakotaNo ratings yet
- Introduction To Information Storage and Retrieval Systems: BY-Research ScholarDocument42 pagesIntroduction To Information Storage and Retrieval Systems: BY-Research ScholarumraojigyasaNo ratings yet
- 1 introIRDocument22 pages1 introIRFiraol TesfayeNo ratings yet
- Web Mining: Based On Tutorials and PresentationsDocument101 pagesWeb Mining: Based On Tutorials and PresentationsRathna KanthNo ratings yet
- (IJIT-V6I3P1) :asst. Prof. Omprakash Yadav, Saikumar Kandakatla, Shantanu Sawant, Chandan Soni, Murari Indra BahadurDocument4 pages(IJIT-V6I3P1) :asst. Prof. Omprakash Yadav, Saikumar Kandakatla, Shantanu Sawant, Chandan Soni, Murari Indra BahadurIJITJournalsNo ratings yet
- 16 Mark Questions: Unit: 1Document11 pages16 Mark Questions: Unit: 1ganeshyahooNo ratings yet
- Annotating Search Results From Web Databases Using Clustering-Based ShiftingDocument8 pagesAnnotating Search Results From Web Databases Using Clustering-Based ShiftingJOY PhilipNo ratings yet
- Great Expectations Vs Apache Griffin v1.2Document2 pagesGreat Expectations Vs Apache Griffin v1.2kashifNo ratings yet
- Digital Object Identifier (DOI) SystemDocument7 pagesDigital Object Identifier (DOI) SystemFenfen Fenda FlorenaNo ratings yet
- Completed Unit II 17.7.17Document113 pagesCompleted Unit II 17.7.17Dr.A.R.KavithaNo ratings yet
- Information RetrievalDocument17 pagesInformation RetrievalChuks ValentineNo ratings yet
- Unit-1 Chapter 1Document44 pagesUnit-1 Chapter 1indiraNo ratings yet
- MSC IR 2021Document188 pagesMSC IR 2021Bini Teflon Ankh100% (1)
- Revision On Key Aspects of A DatabaseDocument1 pageRevision On Key Aspects of A DatabaseBlake HarrisNo ratings yet
- Lecture 4: Term Weighting and The Vector Space Model: Information Retrieval Computer Science Tripos Part IIDocument62 pagesLecture 4: Term Weighting and The Vector Space Model: Information Retrieval Computer Science Tripos Part IIBemenet BiniyamNo ratings yet
- IR Models: - Why IR Models? - Boolean IR Model - Vector Space IR Model - Probabilistic IR ModelDocument46 pagesIR Models: - Why IR Models? - Boolean IR Model - Vector Space IR Model - Probabilistic IR Modelkerya ibrahimNo ratings yet
- Database AdministratorDocument17 pagesDatabase AdministratorJustine Joyce GabiaNo ratings yet
- 1 - introIR BestDocument21 pages1 - introIR Bestrobel damiseNo ratings yet
- ElasticSearch IEEE Format1Document3 pagesElasticSearch IEEE Format1shrasti guptaNo ratings yet
- Ekso Ideas05Document10 pagesEkso Ideas05Dejan NNo ratings yet
- Discovering Computers 2008: Database ManagementDocument50 pagesDiscovering Computers 2008: Database ManagementMarwa HassanNo ratings yet
- DatabasesDocument7 pagesDatabasesapi-416920618No ratings yet
- IRS Unit-3Document32 pagesIRS Unit-3Nagendra MarisettiNo ratings yet
- Chapter OneDocument10 pagesChapter OnelatigudataNo ratings yet
- Modern Information Storage and RetrievalDocument10 pagesModern Information Storage and Retrievalteddy demissieNo ratings yet
- Dokumen - Pub Elasticsearch 7 Quick Start Guide Get Up and Running With The Distributed Search and Analytics Capabilities of Elasticsearch 9781789803327 1789803322Document326 pagesDokumen - Pub Elasticsearch 7 Quick Start Guide Get Up and Running With The Distributed Search and Analytics Capabilities of Elasticsearch 9781789803327 1789803322ZeroCool ZeroNo ratings yet
- Operator Essentials 1Document51 pagesOperator Essentials 1Jhoel ChinchinNo ratings yet
- Information Retrieval System Assignment-1Document10 pagesInformation Retrieval System Assignment-1suryachandra poduguNo ratings yet
- Outline For Chapter 2:: Index Design FactorsDocument2 pagesOutline For Chapter 2:: Index Design FactorsSIDRANo ratings yet
- Module 5 - Development of Health Information Systems Through MS Access Flashcards - QuizletDocument4 pagesModule 5 - Development of Health Information Systems Through MS Access Flashcards - QuizletjoshuaNo ratings yet
- 1-Overview of Information RetrievalDocument44 pages1-Overview of Information Retrievalhalal.army07No ratings yet
- Information Retrieval: BITS PilaniDocument17 pagesInformation Retrieval: BITS PilaniSwati AgrawalNo ratings yet
- Chapter 3 IRDocument56 pagesChapter 3 IROumer HussenNo ratings yet
- Irs 3Document14 pagesIrs 3Vanraj PardeshiNo ratings yet
- Unit 2 Data - StructuresDocument84 pagesUnit 2 Data - StructuresTatipamula RatnakarNo ratings yet
- ReviewerDocument5 pagesReviewerKrezza Amor MabanNo ratings yet
- Packt Elasticsearch 7 Quick Start Guide 2019Document324 pagesPackt Elasticsearch 7 Quick Start Guide 2019yohoyonNo ratings yet
- IJETR031236Document4 pagesIJETR031236erpublicationNo ratings yet
- Cornell Notes 5Document9 pagesCornell Notes 5Joderon NimesNo ratings yet
- Unit-3 IrsDocument48 pagesUnit-3 Irsganeshjaggineni1927No ratings yet
- Deep Learning Based Complaint Classification For Telecommunication Company's Call CenterDocument17 pagesDeep Learning Based Complaint Classification For Telecommunication Company's Call CenterShinta LukitasariNo ratings yet
- Instructor:-Genene A. (Ass - Pro.)Document27 pagesInstructor:-Genene A. (Ass - Pro.)endris yimerNo ratings yet
- Boolean Similarity MeasureDocument14 pagesBoolean Similarity Measureshoeb mazzinniNo ratings yet
- Elastic Search PresentationDocument55 pagesElastic Search PresentationMustafa ShaikhNo ratings yet
- Using Strong Types in Systemverilog Design and Verification EnvironmentsDocument10 pagesUsing Strong Types in Systemverilog Design and Verification Environmentsselvi0412No ratings yet
- Text MiningDocument23 pagesText MiningChakkarawarthiNo ratings yet
- Hashing and Data Fingerprinting in Digital ForensicsDocument7 pagesHashing and Data Fingerprinting in Digital ForensicsArchana VNo ratings yet
- RDS AWS UpdatedDocument27 pagesRDS AWS Updatedjyotiraditya0709.be21No ratings yet
- Introduction To IR Chapter 01Document29 pagesIntroduction To IR Chapter 01123456ranoNo ratings yet
- Defining IR - Information Retrieval ProcessDocument17 pagesDefining IR - Information Retrieval Processabreham damtewNo ratings yet
- Class NotesDocument610 pagesClass NotesNiraj KumarNo ratings yet
- Database Management Blood Bank Applications: Systems ForDocument3 pagesDatabase Management Blood Bank Applications: Systems ForAsh LynxNo ratings yet
- RDS AwsDocument33 pagesRDS Awsjyotiraditya0709.be21No ratings yet
- NLP TA IR-Application of AI (3L)Document86 pagesNLP TA IR-Application of AI (3L)Ravi RanjanNo ratings yet
- 2a. DATA-WRANGLING-import-link-mixedDocument62 pages2a. DATA-WRANGLING-import-link-mixedGauravNo ratings yet
- What Is Hashing?Document5 pagesWhat Is Hashing?AC18UCS088 Rahul bhatiaNo ratings yet
- Automated Latent Fingerprint Recognition: Kai Cao and Anil K. Jain, Fellow, IEEEDocument14 pagesAutomated Latent Fingerprint Recognition: Kai Cao and Anil K. Jain, Fellow, IEEEmadhura jaiNo ratings yet
- ENG 201 Assignment 1 Solution FileDocument2 pagesENG 201 Assignment 1 Solution FileNalain Zahra0% (2)
- 2004 CE CS Paper II C VersionDocument15 pages2004 CE CS Paper II C Versionapi-3739994No ratings yet
- SP Unit 3Document63 pagesSP Unit 3deepak.singhNo ratings yet
- CSI201 Syllabus Fall2015Document6 pagesCSI201 Syllabus Fall2015lolNo ratings yet
- General Education and Professional EducationDocument21 pagesGeneral Education and Professional Education내이민No ratings yet
- Pipe Bending: Case StudyDocument4 pagesPipe Bending: Case StudyIbrahim shaikNo ratings yet
- Case Study: Digital Learning and Employee Development at The Gulfistan Co., LTDDocument5 pagesCase Study: Digital Learning and Employee Development at The Gulfistan Co., LTDsharan chakravarthyNo ratings yet
- 75rt Ad Ccpulse+Document94 pages75rt Ad Ccpulse+RoyalDSouzaNo ratings yet
- 2023 Globalmobilenetworkexperienceawards OpensignalDocument36 pages2023 Globalmobilenetworkexperienceawards Opensignalsamon samvannakNo ratings yet
- Oaisys Version 8 Administration GuideDocument145 pagesOaisys Version 8 Administration Guidemichael guereroNo ratings yet
- Onsite Service Call Report: Customer Signature: Engineer SignatureDocument2 pagesOnsite Service Call Report: Customer Signature: Engineer SignatureSuraj KumarNo ratings yet
- Regional SettingsDocument7 pagesRegional SettingsSumana VenkateshNo ratings yet
- Sem 6 End Sem PaperDocument11 pagesSem 6 End Sem Paperlakshaaysharma003No ratings yet
- Spatial DatabaseDocument28 pagesSpatial DatabasePravah ShuklaNo ratings yet
- Lions Club Chennai PDFDocument1,114 pagesLions Club Chennai PDFpriya selvaraj100% (1)
- Automatic College Bell Using RTC ECE ProjectDocument6 pagesAutomatic College Bell Using RTC ECE ProjectchandravmNo ratings yet
- THE DOSE Magazine - Issue 3 (Paris) TEASERDocument10 pagesTHE DOSE Magazine - Issue 3 (Paris) TEASERthedosemag100% (1)
- Arma3 ReadmeDocument2 pagesArma3 ReadmeIrvan KurnialfanniNo ratings yet
- APPLE'S Management StyleDocument25 pagesAPPLE'S Management StyleHaniya MubeenNo ratings yet
- Huawei G630-U251 V100r001c00b159custc605d001 Upgrade Guideline v1.0Document8 pagesHuawei G630-U251 V100r001c00b159custc605d001 Upgrade Guideline v1.0Ever Joao Dávila SotoNo ratings yet
- MVTS II Globalink Manual PDFDocument216 pagesMVTS II Globalink Manual PDFCYTT USTONo ratings yet
- Autocad Lab ReportDocument9 pagesAutocad Lab ReportArsl RanaNo ratings yet
- Servo Magazine - April 2010Document84 pagesServo Magazine - April 2010dan_m_huNo ratings yet
- Optimize Hitachi Storage and Server Platforms in Vmware Vsphere 5 5 EnvironmentsDocument41 pagesOptimize Hitachi Storage and Server Platforms in Vmware Vsphere 5 5 EnvironmentsPaing HtooNo ratings yet
- Timeline of C++ CourseDocument9 pagesTimeline of C++ CoursesohamNo ratings yet
- OMR06Document2 pagesOMR06Anas IsmailNo ratings yet
- CharmDocument660 pagesCharmanirbanisonlineNo ratings yet
- Final DOXupdatedfeb20Document186 pagesFinal DOXupdatedfeb20Neil JohnNo ratings yet
- Compact NSX LV432081Document2 pagesCompact NSX LV432081Lucian ChorusNo ratings yet
- Finite Difference Method 10EL20Document34 pagesFinite Difference Method 10EL20muhammad_sarwar_2775% (8)