You might also like
- Write A Program That Multiplies Two Integer Numbers Without Using Operator, Using Repeated AdditionDocument15 pagesWrite A Program That Multiplies Two Integer Numbers Without Using Operator, Using Repeated AdditionAnsh GaurNo ratings yet
- Computer Science Practical File Solutions 2020-21Document36 pagesComputer Science Practical File Solutions 2020-21Soumen MahatoNo ratings yet
- Class 12 - Computer Science Practical File PythonDocument38 pagesClass 12 - Computer Science Practical File PythonHriman Mittal100% (1)
- Write A Python Program To Solve Quadratic EquationDocument6 pagesWrite A Python Program To Solve Quadratic EquationroseNo ratings yet
- Python Lab ProgramsDocument8 pagesPython Lab ProgramsVARSHA K U100% (1)
- Smic Class Xii Python Practicals-2021Document26 pagesSmic Class Xii Python Practicals-2021Aryan YadavNo ratings yet
- Cs Codes 12thDocument33 pagesCs Codes 12thAbhay MehtaNo ratings yet
- CS018 - Python Lab ManualDocument28 pagesCS018 - Python Lab ManualChamarthi HarshithaNo ratings yet
- Practical Assignment Xi SC (CS) - 2022-23Document8 pagesPractical Assignment Xi SC (CS) - 2022-23Adarsh Kumar PadhanNo ratings yet
- ST. TERESA SCHOOL PYTHON PROGRAMMINGDocument50 pagesST. TERESA SCHOOL PYTHON PROGRAMMINGVishalNo ratings yet
- Python Programming Lab IntroductionDocument9 pagesPython Programming Lab IntroductionAnuradha PatnalaNo ratings yet
- Python Lecture Notes III UnitsDocument21 pagesPython Lecture Notes III UnitsEmo ChNo ratings yet
- IP Class-XI Chapter-9 NOTESDocument14 pagesIP Class-XI Chapter-9 NOTESRituNagpal IpisNo ratings yet
- Memory Layout of C ProgramsDocument5 pagesMemory Layout of C Programsarv1612No ratings yet
- Class 12 PYTHON FILE PDFDocument29 pagesClass 12 PYTHON FILE PDFAnurag JacksonNo ratings yet
- AI Practical FileDocument30 pagesAI Practical FileTridonNo ratings yet
- Programming Fundamentals: Lecturer XXXDocument30 pagesProgramming Fundamentals: Lecturer XXXPeterNo ratings yet
- CSE 4235c Python Assignment 01Document14 pagesCSE 4235c Python Assignment 01Anonymous mw8QhbhfhONo ratings yet
- Python ProgramsDocument35 pagesPython ProgramsnikhilNo ratings yet
- C Lab SheetDocument4 pagesC Lab SheetRamesh ShresthaNo ratings yet
- AI ClassXII Study MaterialsDocument40 pagesAI ClassXII Study MaterialsPradeep SinghNo ratings yet
- Finite State Machines NotesDocument6 pagesFinite State Machines Notesemilzaev01No ratings yet
- Unit-I: Introction To PythonDocument18 pagesUnit-I: Introction To PythonSumanth GopuNo ratings yet
- D A1110 Pages:3: Answer All Questions, Each Carries2 or 3 MarksDocument3 pagesD A1110 Pages:3: Answer All Questions, Each Carries2 or 3 Marksrose100% (1)
- Department of Information Science and Engineering: Study Material For Academic Year 2020-21 (Odd Semester)Document51 pagesDepartment of Information Science and Engineering: Study Material For Academic Year 2020-21 (Odd Semester)1NH19CS047. NithishNo ratings yet
- Lab Sheet 05 - Numpy and MatplotlibDocument12 pagesLab Sheet 05 - Numpy and MatplotlibSasmitha KalharaNo ratings yet
- Python PPT 2Document36 pagesPython PPT 2Yusuf Khan100% (1)
- Python LAB Exercises: Sample OutputDocument2 pagesPython LAB Exercises: Sample OutputMadhu Priya Guthi100% (1)
- Xii Cs Question Bank For Bright Students Chapter Wise Set-IIDocument40 pagesXii Cs Question Bank For Bright Students Chapter Wise Set-IIUsha Mishra365No ratings yet
- 6 - KNN ClassifierDocument10 pages6 - KNN ClassifierCarlos LopezNo ratings yet
- Diffuse Algorithms for Neural and Neuro-Fuzzy Networks: With Applications in Control Engineering and Signal ProcessingFrom EverandDiffuse Algorithms for Neural and Neuro-Fuzzy Networks: With Applications in Control Engineering and Signal ProcessingNo ratings yet
- PythonDocument14 pagesPythonDarshan M MNo ratings yet
- Mini Project On Calculator. Source Code:-: Experiment No:-13Document5 pagesMini Project On Calculator. Source Code:-: Experiment No:-13Akshay VarmaNo ratings yet
- Python Lab ManualDocument26 pagesPython Lab ManualRamalaxmi BollaNo ratings yet
- An Introduction to MATLAB® Programming and Numerical Methods for EngineersFrom EverandAn Introduction to MATLAB® Programming and Numerical Methods for EngineersNo ratings yet
- Convolutional Neural Network Architecture - CNN ArchitectureDocument13 pagesConvolutional Neural Network Architecture - CNN ArchitectureRathi PriyaNo ratings yet
- How to Design Optimization Algorithms by Applying Natural Behavioral PatternsFrom EverandHow to Design Optimization Algorithms by Applying Natural Behavioral PatternsNo ratings yet
- ANN MatlabDocument13 pagesANN MatlabprashmceNo ratings yet
- Group Assignment (Beng 1113)Document15 pagesGroup Assignment (Beng 1113)Faris AzminNo ratings yet
- ML Assignment 1 PDFDocument6 pagesML Assignment 1 PDFAnubhav MongaNo ratings yet
- Data Structures NotesDocument97 pagesData Structures NotesKibru AberaNo ratings yet
- Experiment 1: Write A Python Program To Find Sum of Series (1+ (1+2) + (1+2+3) +-+ (1+2+3+ - +N) )Document20 pagesExperiment 1: Write A Python Program To Find Sum of Series (1+ (1+2) + (1+2+3) +-+ (1+2+3+ - +N) )jai geraNo ratings yet
- Effective SNR Estimation in Ofdm System Simulation: He Mats TorkelsonDocument6 pagesEffective SNR Estimation in Ofdm System Simulation: He Mats TorkelsonJORGE GONZALEZ ORELLANANo ratings yet
- EmbeddedCProgrammingV1 1Document447 pagesEmbeddedCProgrammingV1 1Ahmed Nour0% (1)
- Machine Learning Practical FileDocument41 pagesMachine Learning Practical FileAnupriya JainNo ratings yet
- Assignments in PythonDocument5 pagesAssignments in PythonArindam0% (1)
- Calculator ADocument11 pagesCalculator Aabhijith sajithNo ratings yet
- About The Classification and Regression Supervised Learning ProblemsDocument3 pagesAbout The Classification and Regression Supervised Learning ProblemssaileshmnsNo ratings yet
- Here Is A Good Place To Include Header Files That Are Required Across Your Application.Document16 pagesHere Is A Good Place To Include Header Files That Are Required Across Your Application.Vladimir ZidarNo ratings yet
- Artificial Neural Network Simulation and Training in MatlabDocument13 pagesArtificial Neural Network Simulation and Training in MatlabAkhil AroraNo ratings yet
- Intro To Automata TheoryDocument23 pagesIntro To Automata TheoryRaqeeb RahmanNo ratings yet
- Python Lab: Introduction to VariablesDocument15 pagesPython Lab: Introduction to Variablestala massadNo ratings yet
- Python Programs - OswalDocument29 pagesPython Programs - OswalAnitha SathiaseelanNo ratings yet
- Python PracticalsDocument14 pagesPython PracticalsMr.Sachin Harne RungtaNo ratings yet
- Python Question SolutionDocument11 pagesPython Question SolutionAvijit BiswasNo ratings yet
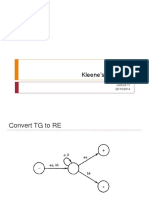
- Kleene's Theorem RE to FA ConversionDocument24 pagesKleene's Theorem RE to FA ConversionSamitaNo ratings yet
- Lecture 13Document26 pagesLecture 13SamitaNo ratings yet
- CSE-402 Virtual University PakistanDocument22 pagesCSE-402 Virtual University PakistanSamitaNo ratings yet
- Finite AutomataDocument10 pagesFinite AutomataSamitaNo ratings yet
- Lecture 3Document20 pagesLecture 3SamitaNo ratings yet
- Introduction to Defining LanguagesDocument13 pagesIntroduction to Defining LanguagesSamitaNo ratings yet
- Ecture: Regular ExpressionsDocument19 pagesEcture: Regular ExpressionsSamitaNo ratings yet
- S B T A: Amita AI Heory OF UtomataDocument16 pagesS B T A: Amita AI Heory OF UtomataSamitaNo ratings yet
- Finite AutomataDocument10 pagesFinite AutomataSamitaNo ratings yet
- Introduction to Defining LanguagesDocument13 pagesIntroduction to Defining LanguagesSamitaNo ratings yet
- Ecture: Regular ExpressionsDocument19 pagesEcture: Regular ExpressionsSamitaNo ratings yet
- Lecture 3Document20 pagesLecture 3SamitaNo ratings yet
- S B T A: Amita AI Heory OF UtomataDocument16 pagesS B T A: Amita AI Heory OF UtomataSamitaNo ratings yet
- LR(0) and SLR Parse Table ConstructionDocument19 pagesLR(0) and SLR Parse Table ConstructionNaveed KhanNo ratings yet
- Bottom Up ApproachDocument22 pagesBottom Up ApproachShruti PatelNo ratings yet
- PCD Important QuestionDocument28 pagesPCD Important QuestionGaurav SahuNo ratings yet
- UGC-NET Computer ScienceDocument21 pagesUGC-NET Computer Scienceswastik1100% (2)
- Principles of Compiler Design 2001 Regulations CS337Document2 pagesPrinciples of Compiler Design 2001 Regulations CS337Monica NareshNo ratings yet
- CD Unit-IiDocument34 pagesCD Unit-IiVasudevarao PeyyetiNo ratings yet
- Compiler DesignDocument25 pagesCompiler DesignTrust KaguraNo ratings yet
- Bottom Up ParsingDocument36 pagesBottom Up Parsingparoo7kNo ratings yet
- Module 4Document31 pagesModule 4arunlaldsNo ratings yet
- Compiler Design Lab ManualDocument39 pagesCompiler Design Lab ManualSri Prince PriyatharsanNo ratings yet
- CD Lab RecordDocument43 pagesCD Lab RecordGaurav PandeyNo ratings yet
- CSE382-compiler Design Lab ManualDocument76 pagesCSE382-compiler Design Lab Manualmanchicse15100% (1)
- Co DataDocument76 pagesCo DataTarun BeheraNo ratings yet
- CD Module2 16 03 23 PDFDocument36 pagesCD Module2 16 03 23 PDFSouvik DasNo ratings yet
- CSE313 - Compiler Design - HandoutDocument5 pagesCSE313 - Compiler Design - HandoutDamodharan DNo ratings yet
- SSQBANKDocument2 pagesSSQBANKUmaNo ratings yet
- Quick Book of CompilerDocument66 pagesQuick Book of CompilerArshadNo ratings yet
- CC QuestionsDocument9 pagesCC QuestionsjagdishNo ratings yet
- Compiler Design GuideDocument31 pagesCompiler Design GuidePadmavathi BNo ratings yet
- Compiler Design CS8602 Questions & Problem AnswersDocument15 pagesCompiler Design CS8602 Questions & Problem AnswersPrawinNo ratings yet
- Bottom-Up Parsing - IntroDocument12 pagesBottom-Up Parsing - Introkushagra goyalNo ratings yet
- Compiler Lab Manual Final E-ContentDocument55 pagesCompiler Lab Manual Final E-ContentPRISTUniversity75% (16)
- Bottom-up Parsing TechniquesDocument26 pagesBottom-up Parsing TechniquesFitawu TekolaNo ratings yet
- Shift Reduce ParsingDocument14 pagesShift Reduce ParsingUsama ArainNo ratings yet
- Shift Reduce ParsingDocument21 pagesShift Reduce ParsingsuryanshNo ratings yet
- Compiler Design MaterialDocument19 pagesCompiler Design MaterialthebillionairepraveenNo ratings yet
- CS8602 Compiler Design Two Marks Questions 1Document22 pagesCS8602 Compiler Design Two Marks Questions 1Pradeepkumar PradeepkumarNo ratings yet
- Module 4Document53 pagesModule 4appushetty072No ratings yet
- PCD 2 MarksDocument23 pagesPCD 2 MarksVignesh VickyNo ratings yet
- CLR(1) and LALR(1) Parsers ExplainedDocument76 pagesCLR(1) and LALR(1) Parsers ExplainedNiall HoranNo ratings yet