You might also like
- Practical-5 - Jupyter NotebookDocument8 pagesPractical-5 - Jupyter NotebookHarsha Gohil100% (1)
- Interpolatingfunction : Bla Ndsolve ( (F ''' (T) + F (T) F '' (T) 0, F (0) 0, F ' (0) 0, F ' (100 000) 1), F, T)Document7 pagesInterpolatingfunction : Bla Ndsolve ( (F ''' (T) + F (T) F '' (T) 0, F (0) 0, F ' (0) 0, F ' (100 000) 1), F, T)Alexis CastleNo ratings yet
- ANANYAA GUPTA 20BCT0177 ML MTT 24/11/21 Q3 Breast Cancer DatasetDocument4 pagesANANYAA GUPTA 20BCT0177 ML MTT 24/11/21 Q3 Breast Cancer DatasetAnanyaa GuptaNo ratings yet
- Lab 5Document4 pagesLab 5Muhammad SalmanNo ratings yet
- 1Document4 pages1Arpita DasNo ratings yet
- DSBDA-4Document4 pagesDSBDA-4Arbaz ShaikhNo ratings yet
- Assignment-7 (CSL5402) Name:-Kommireddy - Manikanta Sai Roll No: - 1906036 Branch: - CSE-1Document7 pagesAssignment-7 (CSL5402) Name:-Kommireddy - Manikanta Sai Roll No: - 1906036 Branch: - CSE-1Manikanta Sai100% (1)
- SVM Classifier Accuracy on Iris and Social Media DataDocument7 pagesSVM Classifier Accuracy on Iris and Social Media DataManikanta Sai100% (1)
- Covid-19 Prediction - Jupyter NotebookDocument6 pagesCovid-19 Prediction - Jupyter NotebookTEEGALAMEHERRITHWIK 122010320035No ratings yet
- Logistic RegressionDocument3 pagesLogistic RegressionShwetha ReddyNo ratings yet
- Glass ClassificationDocument3 pagesGlass ClassificationSiddharth Tiwari100% (2)
- Project 8 Predictive Analytics - Ipynb - ColaboratoryDocument8 pagesProject 8 Predictive Analytics - Ipynb - ColaboratoryaadityadeolalikarNo ratings yet
- Varma GarchDocument55 pagesVarma GarchJosue KouakouNo ratings yet
- Tutorial Pandas Bag-5Document11 pagesTutorial Pandas Bag-5NUR JAYANo ratings yet
- K MeansDocument15 pagesK MeansJEISON ANDRES GOMEZ PEDRAZANo ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Labpractice 2Document29 pagesLabpractice 2Rajashree Das100% (1)
- Using Tensorflow To Predict Jet Numbers in Cern Proton Collisions (Evaluator-Omid-Baghcheh-Saraei)Document29 pagesUsing Tensorflow To Predict Jet Numbers in Cern Proton Collisions (Evaluator-Omid-Baghcheh-Saraei)David EsparzaArellanoNo ratings yet
- Advertising - Paulina Frigia Rante (34) - PPBP 1 - ColaboratoryDocument7 pagesAdvertising - Paulina Frigia Rante (34) - PPBP 1 - ColaboratoryPaulina Frigia RanteNo ratings yet
- Image ClassificationsDocument4 pagesImage ClassificationsAnvesh SilaganaNo ratings yet
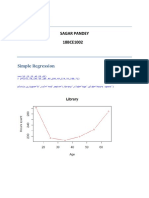
- WEEK: 3&4: Simple RegressionDocument6 pagesWEEK: 3&4: Simple RegressionatNo ratings yet
- Logistic Pima Indians - Ipynb - ColaboratoryDocument4 pagesLogistic Pima Indians - Ipynb - ColaboratorySHEKHAR SWAMINo ratings yet
- NBA Games Prediction 1683875972Document11 pagesNBA Games Prediction 1683875972luis pozaspalomoNo ratings yet
- Regression analysis of housing dataDocument12 pagesRegression analysis of housing datasadyehclenNo ratings yet
- Clustering analysis reveals optimum number of clusters for airlines and crime dataDocument9 pagesClustering analysis reveals optimum number of clusters for airlines and crime datanehal gundrapally100% (1)
- Numpy PandasDocument20 pagesNumpy PandasAnish pandeyNo ratings yet
- DATA SCIENCE IDC 302 end sem projectDocument1 pageDATA SCIENCE IDC 302 end sem projectsoniakar3000No ratings yet
- Sklearn Decision Tree Classification of Iris DatasetDocument4 pagesSklearn Decision Tree Classification of Iris DatasetNguyen Trung ThinhNo ratings yet
- Meaningful Predictive Modeling Week-4 Assignment Cancer Disease PredictionDocument6 pagesMeaningful Predictive Modeling Week-4 Assignment Cancer Disease PredictionfrankhNo ratings yet
- Assignment 11Document7 pagesAssignment 11ankit mahto100% (1)
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Decision-Tree-Lab 3Document4 pagesDecision-Tree-Lab 3api-559045701No ratings yet
- E21CSEU0770_Lab4Document4 pagesE21CSEU0770_Lab4kumar.nayan26No ratings yet
- 20bce2251 VL2021220503859 Ast02Document10 pages20bce2251 VL2021220503859 Ast02TANMAY MEHROTRANo ratings yet
- Data Preprocessing ML LabDocument6 pagesData Preprocessing ML Labmohan kukrejaNo ratings yet
- Some Important Function of Pandas LibraryDocument24 pagesSome Important Function of Pandas LibraryRania DirarNo ratings yet
- Analyzing California Housing Data with PandasDocument18 pagesAnalyzing California Housing Data with PandasdoudoudzNo ratings yet
- Quantil PanelDocument13 pagesQuantil PanelNorvanBagusRamadhanNo ratings yet
- K nearest neighboursDocument4 pagesK nearest neighboursbunsglazing135No ratings yet
- Ann 2Document8 pagesAnn 21314 Vishakha JagtapNo ratings yet
- Chapter 5Document22 pagesChapter 5Rajat BansalNo ratings yet
- Project-Password Strength ClassifierDocument6 pagesProject-Password Strength ClassifierOlalekan SamuelNo ratings yet
- Hasil RendiDocument11 pagesHasil RendiFitria KintaNo ratings yet
- Import Excel Data and Perform Operations in MatlabDocument6 pagesImport Excel Data and Perform Operations in MatlabSulman ShahzadNo ratings yet
- 20MIS1115 - Matlab CodesDocument64 pages20MIS1115 - Matlab CodesSam100% (4)
- 3 Confussion Matrix Hasil Modelling OKDocument8 pages3 Confussion Matrix Hasil Modelling OKArman Maulana Muhtar100% (1)
- 1 Linear Regression: 1.1 Data ExplorationDocument12 pages1 Linear Regression: 1.1 Data ExplorationXyzNo ratings yet
- Lab10 Regression Evaluation MethodsDocument5 pagesLab10 Regression Evaluation Methodsiffi khanNo ratings yet
- R19C076 - Chanukya Gowda K - Mlda - Assignment-2Document19 pagesR19C076 - Chanukya Gowda K - Mlda - Assignment-2Chanukya Gowda kNo ratings yet
- Tutorial 2 - ClusteringDocument6 pagesTutorial 2 - ClusteringGupta Akshay100% (2)
- Handle The Missing Value: Importing Pandas and Numpy LibsDocument4 pagesHandle The Missing Value: Importing Pandas and Numpy LibsAkshay PatilNo ratings yet
- Y # - Y Matrix SetupDocument11 pagesY # - Y Matrix SetupSeymurH-vNo ratings yet
- Tarea 5Document6 pagesTarea 5Alejandra Hernández ValenzoNo ratings yet
- Uas Algoritma - Novera SafitriDocument3 pagesUas Algoritma - Novera SafitriNOVERA SAFITRINo ratings yet
- Uas Algoritma - Novera SafitriDocument3 pagesUas Algoritma - Novera SafitriNOVERA SAFITRINo ratings yet
- TP RegressionDocument1 pageTP RegressionMOHAMED EL BACHIR BERRIOUA100% (1)
- Data Munging of Housing DatasetDocument4 pagesData Munging of Housing DatasetadhiNo ratings yet
- Assumption of Linear RegressionDocument6 pagesAssumption of Linear RegressionKagade AjinkyaNo ratings yet
- Loading The Dataset: 'Diabetes - CSV'Document4 pagesLoading The Dataset: 'Diabetes - CSV'Divyani ChavanNo ratings yet
- A Vast HeartDocument5 pagesA Vast HeartRadhika KhandelwalNo ratings yet
- 4c Sklearn-Classification-Regression-Bkhw-Spring 2019Document20 pages4c Sklearn-Classification-Regression-Bkhw-Spring 2019Radhika KhandelwalNo ratings yet
- AI - at - Scale - Blog - Jupyter NotebookDocument9 pagesAI - at - Scale - Blog - Jupyter NotebookRadhika KhandelwalNo ratings yet
- Dropout: A Simple Way To Prevent Neural Networks From Over TtingDocument30 pagesDropout: A Simple Way To Prevent Neural Networks From Over TtingJosephNo ratings yet
- Extention of Unit 4Document18 pagesExtention of Unit 4Mehaboob BashaNo ratings yet
- Sarsi Cola Life CycleDocument3 pagesSarsi Cola Life CycleMary Joy Credo LangamanNo ratings yet
- How to Apply for UST College Admission - Attach Photo, Signature, and FormsDocument3 pagesHow to Apply for UST College Admission - Attach Photo, Signature, and FormsCharles GunitaNo ratings yet
- IoTize TapNLink Wins NFC Innovation Award For Best Emerging ConceptDocument2 pagesIoTize TapNLink Wins NFC Innovation Award For Best Emerging ConceptPR.comNo ratings yet
- Big Car Small Car Big Car IiDocument6 pagesBig Car Small Car Big Car IierwinssNo ratings yet
- Ch5 - 4 Design of Sequential CircuitsDocument46 pagesCh5 - 4 Design of Sequential CircuitsMariam ElnourNo ratings yet
- Maths Mensuration Surface Area ConesThe title "TITLEMaths Mensuration Surface Area ConesDocument12 pagesMaths Mensuration Surface Area ConesThe title "TITLEMaths Mensuration Surface Area ConesWafi Bin Hassan The InevitableNo ratings yet
- M Mpa-014Document9 pagesM Mpa-014AakashMalhotraNo ratings yet
- Thermal Contact Resistance PDFDocument7 pagesThermal Contact Resistance PDFfahrgeruste3961No ratings yet
- NetApp NCDA Lab Questions Study GuideDocument2 pagesNetApp NCDA Lab Questions Study GuideSrinivas KumarNo ratings yet
- ESO 208A: Introduction to Computational MethodsDocument26 pagesESO 208A: Introduction to Computational MethodsAswerNo ratings yet
- COMPARING AGRICULTURE EXTENSION SYSTEMSDocument31 pagesCOMPARING AGRICULTURE EXTENSION SYSTEMSshah jahanNo ratings yet
- IHRM Recuritment and Selection Case StudyDocument29 pagesIHRM Recuritment and Selection Case Studymadihahamid100% (1)
- s3 Unit of Work - Maths - Volume and CapacityDocument5 pagess3 Unit of Work - Maths - Volume and Capacityapi-464819855No ratings yet
- MGMT and Cost Accounting - Colin DruryDocument25 pagesMGMT and Cost Accounting - Colin Druryapi-24690719550% (2)
- SAS Universal Viewer 1.2: User's GuideDocument32 pagesSAS Universal Viewer 1.2: User's GuideSmita AgrawalNo ratings yet
- New Microsoft Office Word DocumentDocument6 pagesNew Microsoft Office Word DocumentAjayNo ratings yet
- Unit - 4 - Key AnswersDocument22 pagesUnit - 4 - Key Answerskurd gamerNo ratings yet
- HR - Delhi NCR Sample - Count 8968Document54 pagesHR - Delhi NCR Sample - Count 8968krono123No ratings yet
- Steven Jones Et Al - Fourteen Points of Agreement With Official Government Reports On The World Trade Center DestructionDocument7 pagesSteven Jones Et Al - Fourteen Points of Agreement With Official Government Reports On The World Trade Center DestructionChiodo72No ratings yet
- Between Somaliland and Puntland by Markus Hoehne - RVI Contested Borderlands (2015)Document180 pagesBetween Somaliland and Puntland by Markus Hoehne - RVI Contested Borderlands (2015)Mahad Abdi100% (1)
- QPR - Technical Cleanliness (TC) RequirementsDocument12 pagesQPR - Technical Cleanliness (TC) RequirementsOliver SteinrötterNo ratings yet
- The Oak Island Money Pit: Remote Viewing Summary Sheet © Daz Smith - Do Not Distribute Without PermissionDocument49 pagesThe Oak Island Money Pit: Remote Viewing Summary Sheet © Daz Smith - Do Not Distribute Without PermissionJosh RNo ratings yet
- Spinoza On AffectsDocument8 pagesSpinoza On AffectsIulia MocanuNo ratings yet
- # # Sob PST: Extracting The Square Roots Factoring Completing The SquareDocument4 pages# # Sob PST: Extracting The Square Roots Factoring Completing The SquareVince BonosNo ratings yet
- Exercise 1 Name: Louella M. Ramos Score: - Section: 11-Abigail RatingDocument10 pagesExercise 1 Name: Louella M. Ramos Score: - Section: 11-Abigail RatingJhon Carlo A. AcopraNo ratings yet
- The Qualities of A Good Businessman-Syed Muhammad JubairDocument8 pagesThe Qualities of A Good Businessman-Syed Muhammad JubairAdeel AbdullahNo ratings yet
- For Serving Railway Employees of East Coast RailwayDocument11 pagesFor Serving Railway Employees of East Coast Railwaypunithrgowda22No ratings yet
- Alien Word Choice Lesson by Lindy McBratneyDocument2 pagesAlien Word Choice Lesson by Lindy McBratneyLindy McBratneyNo ratings yet
- Inherited Human Traits Quick Reference - PublicDocument6 pagesInherited Human Traits Quick Reference - PublicFares HowariNo ratings yet