You might also like
- 2 and 3Document6 pages2 and 3Radhika KhandelwalNo ratings yet
- Analisis Granulometrico #De Mallas Abertura Peso Gr. % Peso Ret. % Ac (+) % Ac (-)Document4 pagesAnalisis Granulometrico #De Mallas Abertura Peso Gr. % Peso Ret. % Ac (+) % Ac (-)AnthoniNo ratings yet
- UntitledDocument2 pagesUntitledANDREZA FRARENo ratings yet
- LT231218A 10umDocument2 pagesLT231218A 10umharoldcaNo ratings yet
- Example 11.15Document7 pagesExample 11.15ambreen fatimaNo ratings yet
- Analisis Granulometrico #De Mallas Abertura Peso Gr. % Peso Ret. % Ac (+) % Ac (-)Document4 pagesAnalisis Granulometrico #De Mallas Abertura Peso Gr. % Peso Ret. % Ac (+) % Ac (-)Jhon Mamani QuispeNo ratings yet
- Data ScienceDocument1 pageData Science2001yashkhandelwalNo ratings yet
- Simple Linear regression-LAB4.ipynb - ColaboratoryDocument6 pagesSimple Linear regression-LAB4.ipynb - ColaboratoryPATTABHI RAMANJANEYULUNo ratings yet
- Relajacion CorregidoDocument10 pagesRelajacion CorregidoLaura Benitez LozanoNo ratings yet
- Soal PTK Par 2016Document6 pagesSoal PTK Par 2016Anton PrayogaNo ratings yet
- Bolt Din 931Document3 pagesBolt Din 931anNo ratings yet
- LT231218B 10 UmDocument2 pagesLT231218B 10 UmharoldcaNo ratings yet
- Ejercicios-Asentamientos en Cimientos Poco Profundos 1Document14 pagesEjercicios-Asentamientos en Cimientos Poco Profundos 1Angii RomeroNo ratings yet
- Prova Hidrologia - Amanda LemosDocument12 pagesProva Hidrologia - Amanda LemosAmanda LemosNo ratings yet
- Iniitiation A La PrevisionDocument8 pagesIniitiation A La PrevisionAMEYRENo ratings yet
- Tromp Curve Calculations and ResultsDocument3 pagesTromp Curve Calculations and Resultsrecai100% (3)
- Assigment 2 - Claudia Gilabert PrietoDocument7 pagesAssigment 2 - Claudia Gilabert Prietoclaudia gilabert prietoNo ratings yet
- Practical-5 - Jupyter NotebookDocument8 pagesPractical-5 - Jupyter NotebookHarsha Gohil100% (1)
- Discharge Bend MasterDocument5 pagesDischarge Bend MasteraszlizaNo ratings yet
- Acetone - Methanol, ChloroformDocument6 pagesAcetone - Methanol, ChloroformAlejandra InsuastyNo ratings yet
- Air Pressure, Psi XY X 2 Height of Nail Out of Board, MMDocument13 pagesAir Pressure, Psi XY X 2 Height of Nail Out of Board, MMravindra erabattiNo ratings yet
- LT231218A 20umDocument2 pagesLT231218A 20umharoldcaNo ratings yet
- Curva IDF de CuencaDocument26 pagesCurva IDF de Cuencaandersson rodriguezNo ratings yet
- Project Cost Overrun ScenariosDocument318 pagesProject Cost Overrun ScenariosAli SibtainNo ratings yet
- Project: (G+4) Hotel Owner: Ato Wondafrash Tesfaye Location: Wolega (Gimbi)Document2 pagesProject: (G+4) Hotel Owner: Ato Wondafrash Tesfaye Location: Wolega (Gimbi)Frezer AmareNo ratings yet
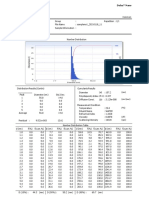
- Delsa™ Nano: (D) (NM) (P.I.) (D) (CM /sec)Document2 pagesDelsa™ Nano: (D) (NM) (P.I.) (D) (CM /sec)Rahmah IdrisNo ratings yet
- LT231218B 20umDocument2 pagesLT231218B 20umharoldcaNo ratings yet
- Covid-19 Prediction - Jupyter NotebookDocument6 pagesCovid-19 Prediction - Jupyter NotebookTEEGALAMEHERRITHWIK 122010320035No ratings yet
- Machine Learnin1Document41 pagesMachine Learnin1Surabhi Kulkarni100% (1)
- Kanu Jain AssignmentDocument5 pagesKanu Jain AssignmentShobha Jain MawandiaNo ratings yet
- Ringformationinkilns 140529065933 Phpapp01Document2 pagesRingformationinkilns 140529065933 Phpapp01Abul Qasim QasimNo ratings yet
- Practica N°08Document1 pagePractica N°08Juancho TusinNo ratings yet
- Matriks Olahan Data Ukur NSP Hamling - Anjasmara - D031211003Document1 pageMatriks Olahan Data Ukur NSP Hamling - Anjasmara - D031211003Anjasmara IdhamNo ratings yet
- Andesite Lab TestsDocument7 pagesAndesite Lab TestsCristian A'cNo ratings yet
- Aduana: Cuadro #15 - Perú: Importación para El Consumo Trimestral Por Aduanas 2014-2015 (Valores en Millones de US $)Document8 pagesAduana: Cuadro #15 - Perú: Importación para El Consumo Trimestral Por Aduanas 2014-2015 (Valores en Millones de US $)Lindzay Guerrero HuamánNo ratings yet
- Preliminary Test Results: Correlation of Geogauge Modulus To That Derived From CBRDocument4 pagesPreliminary Test Results: Correlation of Geogauge Modulus To That Derived From CBRWayjantha Sunethra Bandara JayawardhanaNo ratings yet
- Vapor PressureDocument42 pagesVapor PressureSamuel OnyewuenyiNo ratings yet
- Tensile Test of Reinforcing Bar: Jebone, Einstein Webster J. July 21, 2017 Bsce/ 4 Year German B. Barlis, DTDocument4 pagesTensile Test of Reinforcing Bar: Jebone, Einstein Webster J. July 21, 2017 Bsce/ 4 Year German B. Barlis, DTJebone Stein Web JuarbalNo ratings yet
- Hasil RendiDocument11 pagesHasil RendiFitria KintaNo ratings yet
- Bolt Din 933Document2 pagesBolt Din 933anNo ratings yet
- AASHTO T 307-99: Resilient Modulus of Subgrade Soils and Untreated Base/Subbase MaterialsDocument1 pageAASHTO T 307-99: Resilient Modulus of Subgrade Soils and Untreated Base/Subbase MaterialsJuan Camilo Pérez CantorNo ratings yet
- Ella Joy A. Yee Maed-Biosci: Exercise Number 1Document7 pagesElla Joy A. Yee Maed-Biosci: Exercise Number 1Teresa Marie Yap CorderoNo ratings yet
- Muh - Sofwwan Tahir EOQDocument4 pagesMuh - Sofwwan Tahir EOQOwen TahirNo ratings yet
- X Glo UL 60 IES FileDocument14 pagesX Glo UL 60 IES FileDenny PanjaitanNo ratings yet
- 3Document1 page3David RodriguezNo ratings yet
- E 3.05E+01 3,532,921,654 1,221,044,674 fctm 2.60 37.87 Cracked β 1.00 17.40 L 8.00 X/l Moment ζ α I I M PDocument2 pagesE 3.05E+01 3,532,921,654 1,221,044,674 fctm 2.60 37.87 Cracked β 1.00 17.40 L 8.00 X/l Moment ζ α I I M PAbel BerhanmeskelNo ratings yet
- Tropmh Curve3Document2 pagesTropmh Curve3MuhammadShoaibNo ratings yet
- Direct ShearDocument1 pageDirect Shearyakob mesheshaNo ratings yet
- Valueterms Black Scholes and TreeDocument9 pagesValueterms Black Scholes and TreeBen HollowayNo ratings yet
- Stud Bolts DIN 976-1: 2002-12: 1. ScopeDocument6 pagesStud Bolts DIN 976-1: 2002-12: 1. ScopejayNo ratings yet
- NBA Games Prediction 1683875972Document11 pagesNBA Games Prediction 1683875972luis pozaspalomoNo ratings yet
- CIV 4013-Assignment 2010Document8 pagesCIV 4013-Assignment 2010Virtual RealityNo ratings yet
- Approximate Hardness Conversion Chart For Copper No 102 To 142 InclusiveDocument1 pageApproximate Hardness Conversion Chart For Copper No 102 To 142 Inclusivenhan leNo ratings yet
- Minimos Cuadrados 1Document6 pagesMinimos Cuadrados 1daniel suanchaNo ratings yet
- Rollover Report July 2020 - Aug 2020Document7 pagesRollover Report July 2020 - Aug 2020bbaalluuNo ratings yet
- Concrete MixDocument1 pageConcrete MixKim KpeanNo ratings yet
- Bab V A. Analisa Varian Satu Arah: DescriptivesDocument18 pagesBab V A. Analisa Varian Satu Arah: DescriptivesZellaNo ratings yet
- DATA SCIENCE IDC 302 End Sem ProjectDocument1 pageDATA SCIENCE IDC 302 End Sem Projectsoniakar3000No ratings yet
- Asentamientos Losa Continua: TABLE: Joint Displacements Joint U3Document4 pagesAsentamientos Losa Continua: TABLE: Joint Displacements Joint U3Daniel MendozaNo ratings yet
- VDOT Cube Training FinalDocument164 pagesVDOT Cube Training FinalsuryaNo ratings yet
- E-Waste AssignmentDocument5 pagesE-Waste AssignmentRitesh Rai50% (2)
- BSCS Practicum ManualDocument40 pagesBSCS Practicum ManualRyann Zandueta Elumba100% (2)
- Applied Numerical MethodsDocument1 pageApplied Numerical MethodsAbhinav RajmohanNo ratings yet
- N68SC-M3S Bios 110321Document40 pagesN68SC-M3S Bios 110321agnaldoreis1988No ratings yet
- 3 TransistorsDocument50 pages3 TransistorsUshan AdhikariNo ratings yet
- Step by Step Checklist For Setting Up Your Own Joomla WebsiteDocument3 pagesStep by Step Checklist For Setting Up Your Own Joomla WebsiteMarina PetrovicNo ratings yet
- JVC mx-gb6 mx-gb5 PDFDocument85 pagesJVC mx-gb6 mx-gb5 PDFAbel Gauna0% (1)
- Infosys Technical Interview QuestionsDocument29 pagesInfosys Technical Interview QuestionsHarpreet Singh BaggaNo ratings yet
- Omar CVDocument2 pagesOmar CVomarNo ratings yet
- TT6 FranzSiggDocument5 pagesTT6 FranzSiggRafael PetermannNo ratings yet
- Icons: Cisco Products: Icon LibraryDocument11 pagesIcons: Cisco Products: Icon Librarymsoto20052576No ratings yet
- InventionsDocument49 pagesInventionsEr. Rahul Kumar VermaNo ratings yet
- Two Types of Bureaucracy Enabling and CoerciveDocument30 pagesTwo Types of Bureaucracy Enabling and Coerciveshafique NoorNo ratings yet
- The Yogavacara's Manual of Indian Mysticism, Practiced by Buddhists - Davids (1896)Document153 pagesThe Yogavacara's Manual of Indian Mysticism, Practiced by Buddhists - Davids (1896)WaterwindNo ratings yet
- Vmware Horizon: End-User Computing TodayDocument5 pagesVmware Horizon: End-User Computing TodayDataNo ratings yet
- Protrack App ManualDocument22 pagesProtrack App ManualAizat Sera Suwandi100% (2)
- The Principles of Universal Web DesignDocument2 pagesThe Principles of Universal Web DesignAshraf AmeenNo ratings yet
- Computer Operations and Fundamentals:: The KeyboardDocument41 pagesComputer Operations and Fundamentals:: The KeyboardbriarnoldjrNo ratings yet
- Show 15Document51 pagesShow 15api-3749967100% (2)
- Web Intelligence XI3 On NetWeaver BW (External)Document73 pagesWeb Intelligence XI3 On NetWeaver BW (External)JorgeNo ratings yet
- Summer Training Project Report On India Bulls TarunDocument44 pagesSummer Training Project Report On India Bulls TarunTRAUN KULSHRESTHA100% (25)
- Vrlabsimulation SRD FinalDocument14 pagesVrlabsimulation SRD Finalapi-548719926No ratings yet
- Computer-Aided Design: Matthieu Rauch, Jean-Yves Hascoet, Jean-Christophe Hamann, Yannick PlenelDocument9 pagesComputer-Aided Design: Matthieu Rauch, Jean-Yves Hascoet, Jean-Christophe Hamann, Yannick Plenelshaukat khanNo ratings yet
- Professional Summary: Sasmita MohantaDocument2 pagesProfessional Summary: Sasmita MohantaAnonymous t1ANvlNo ratings yet
- Afc4 ItDocument474 pagesAfc4 ItWaseem KhanNo ratings yet
- ODI Best PracticesDocument50 pagesODI Best Practicesdeaddude100% (1)
- Electricity Theft Detection: Using Machine LearningDocument23 pagesElectricity Theft Detection: Using Machine LearningAnshul Shrivastava 4-Yr B.Tech. Electrical Engg., IIT (BHU) Varanasi100% (1)
- Service Manual: SRF-M55Document12 pagesService Manual: SRF-M55Anonymous Lfgk6vygNo ratings yet
- Dual Power Automatic Transfer SwitchDocument41 pagesDual Power Automatic Transfer Switchتكنو ليفتNo ratings yet