You might also like
- Hybris bestPracticesGuide R21Document68 pagesHybris bestPracticesGuide R21Silviu IfrimNo ratings yet
- Keto Food List: Greens & Veggies FatsDocument2 pagesKeto Food List: Greens & Veggies FatsERE100% (1)
- Workflow Management With SAP® WebFlow® - A Practical Manual (PDFDrive)Document262 pagesWorkflow Management With SAP® WebFlow® - A Practical Manual (PDFDrive)techworldNo ratings yet
- Agile Development Student Handbook v4.2Document498 pagesAgile Development Student Handbook v4.2seeraj4uraj100% (1)
- Module 2 - Business Architecture PDFDocument26 pagesModule 2 - Business Architecture PDFfrom_ac5969100% (1)
- Wireframe40 PDFDocument116 pagesWireframe40 PDFERENo ratings yet
- Understanding CQI-23 Text R1 Sept 2016Document64 pagesUnderstanding CQI-23 Text R1 Sept 2016SteniliMacabataCotejoNo ratings yet
- Naval Ship Concept DesignDocument78 pagesNaval Ship Concept DesignaminNo ratings yet
- Project Report On Sales and Inventory Management SystemDocument87 pagesProject Report On Sales and Inventory Management Systemsolaipandees100% (3)
- RPA Automation AnywhereDocument64 pagesRPA Automation Anywheresahil mathew100% (3)
- Chapter 1 - STI College Vigan Paperless Document Mangement System - Jayson ViernesDocument15 pagesChapter 1 - STI College Vigan Paperless Document Mangement System - Jayson ViernesJayson ViernesNo ratings yet
- Software Testing Guide BookDocument138 pagesSoftware Testing Guide BookreachmsmNo ratings yet
- ISO 13485:2016 Vs MDSAP ChecklistDocument2 pagesISO 13485:2016 Vs MDSAP Checklistda_reaper_das0% (3)
- COTSDocument12 pagesCOTSRanjaniNo ratings yet
- APQP4Wind E-Manual Version 1.2 - Partial PreviewDocument12 pagesAPQP4Wind E-Manual Version 1.2 - Partial PreviewGüner Güvenç0% (1)
- (Semi-) Automatic Categorization of Natural Language RequirementsDocument16 pages(Semi-) Automatic Categorization of Natural Language RequirementsMian HassanNo ratings yet
- MySEC 2011 6140639Document6 pagesMySEC 2011 6140639gorofa9108No ratings yet
- swj248 PDFDocument8 pagesswj248 PDFakttripathiNo ratings yet
- Text Classification MLND Project Report Prasann PandyaDocument17 pagesText Classification MLND Project Report Prasann PandyaRaja PurbaNo ratings yet
- Automation in Requirements Analysis and SpecificationDocument14 pagesAutomation in Requirements Analysis and Specificationkaran_bhalla22No ratings yet
- Assignment CSE 411Document6 pagesAssignment CSE 411asrar tamimNo ratings yet
- A Mixed Method Approach For Efficient Component Retrieval From A Component RepositoryDocument4 pagesA Mixed Method Approach For Efficient Component Retrieval From A Component RepositoryLiaNaulaAjjahNo ratings yet
- A Simple Model For Classifying Web Queries by User IntentDocument6 pagesA Simple Model For Classifying Web Queries by User IntentAdrian D.No ratings yet
- Literature Review Computer Science ProjectsDocument4 pagesLiterature Review Computer Science Projectsc5jxjm5m100% (1)
- Ieee 2012 Projects Software Engineering at Seabirds (Cochin, Thiruvananthapuram, Mysore, Mangalore, Hubli, Chennai, Trichy)Document7 pagesIeee 2012 Projects Software Engineering at Seabirds (Cochin, Thiruvananthapuram, Mysore, Mangalore, Hubli, Chennai, Trichy)sathish20059No ratings yet
- Atde 12 Atde200125Document10 pagesAtde 12 Atde200125Josip StjepandicNo ratings yet
- Optimized Prediction of Hard Keyword Queries Over DatabasesDocument5 pagesOptimized Prediction of Hard Keyword Queries Over DatabasesEditor IJRITCCNo ratings yet
- Document Text Classification Using Support Vector MachineDocument5 pagesDocument Text Classification Using Support Vector MachinerohitNo ratings yet
- Requirements Classification and Reuse: Crossing Domain BoundariesDocument12 pagesRequirements Classification and Reuse: Crossing Domain BoundariesgerardbNo ratings yet
- Thesis Software Engineering TopicsDocument5 pagesThesis Software Engineering Topicsgbwaj17e100% (2)
- Exploring The Intersection Between Software Maintenance and Machine LearningDocument33 pagesExploring The Intersection Between Software Maintenance and Machine Learningsatesh kumarNo ratings yet
- (IJCST-V11I4P8) :nishita Raghavendra, Manushree ShahDocument5 pages(IJCST-V11I4P8) :nishita Raghavendra, Manushree ShahEighthSenseGroupNo ratings yet
- 5417-Article Text-19510-1-10-20211218Document8 pages5417-Article Text-19510-1-10-20211218Touseef TahirNo ratings yet
- 1904 08067Document68 pages1904 08067HiteshNo ratings yet
- A Survey of Various Object Oriented Requirement Engineering MethodsDocument5 pagesA Survey of Various Object Oriented Requirement Engineering MethodsIjact EditorNo ratings yet
- IJCRT2208099Document16 pagesIJCRT2208099moheethsankar2002No ratings yet
- Faqcase: A Textual Case-Based Reasoning System: Aminu Bui Muhammad, Abba AlmuDocument8 pagesFaqcase: A Textual Case-Based Reasoning System: Aminu Bui Muhammad, Abba AlmutheijesNo ratings yet
- Functional Requirements Categorization: Grounded Theory ApproachDocument7 pagesFunctional Requirements Categorization: Grounded Theory ApproachAnonymous mlbU2SNo ratings yet
- A Comparative Study On Different Types of Approaches To The Arabic Text ClassificationDocument12 pagesA Comparative Study On Different Types of Approaches To The Arabic Text ClassificationShravan GawandeNo ratings yet
- Software Engineering Dissertation ExamplesDocument6 pagesSoftware Engineering Dissertation ExamplesBuyDissertationPaperCanada100% (1)
- User Modeling For Personalized Web Search With Self-Organizing MapDocument14 pagesUser Modeling For Personalized Web Search With Self-Organizing MapJaeyong KangNo ratings yet
- Online Handwritten Cursive Word RecognitionDocument40 pagesOnline Handwritten Cursive Word RecognitionkousalyaNo ratings yet
- Achieving High Recall and Precision With HTLM Documents: An Innovation Approach in Information RetrievalDocument6 pagesAchieving High Recall and Precision With HTLM Documents: An Innovation Approach in Information RetrievalBhuvana SakthiNo ratings yet
- Principles of Object Oriented Systems: Software Engineering DepartmentDocument34 pagesPrinciples of Object Oriented Systems: Software Engineering DepartmentQuynh KhuongNo ratings yet
- "Analysis of Quality of Object Oriented Systems Using Object Oriented Metrics", IEEE Conference 2011Document9 pages"Analysis of Quality of Object Oriented Systems Using Object Oriented Metrics", IEEE Conference 2011meena meenakshiNo ratings yet
- Network Design Literature ReviewDocument4 pagesNetwork Design Literature Reviewfvgcaatd100% (1)
- Evaluating The Impact of Different Types of Inheritance On The Object Oriented Software MetricsDocument8 pagesEvaluating The Impact of Different Types of Inheritance On The Object Oriented Software Metricsadmin2146No ratings yet
- Computer Science Project Literature ReviewDocument6 pagesComputer Science Project Literature Reviewaflsbegdo100% (1)
- Paper 35-An Empirical Comparison of Machine Learning AlgorithmsDocument6 pagesPaper 35-An Empirical Comparison of Machine Learning AlgorithmsTouseef TahirNo ratings yet
- What Works Better? A Study of Classifying RequirementsDocument7 pagesWhat Works Better? A Study of Classifying Requirementsai forallNo ratings yet
- Ranking MetricsDocument15 pagesRanking MetricsrobertsharklasersNo ratings yet
- Software Documentation The Practitioners PerspectiveDocument12 pagesSoftware Documentation The Practitioners PerspectiveCeeta QualityNo ratings yet
- Contextual Information Search Based On Domain Using Query ExpansionDocument4 pagesContextual Information Search Based On Domain Using Query ExpansionInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Study of Predicting Fault Prone Software ModulesDocument3 pagesStudy of Predicting Fault Prone Software Moduleseditor_ijarcsseNo ratings yet
- Information Retrieval DissertationDocument5 pagesInformation Retrieval DissertationProfessionalPaperWritersUK100% (1)
- Evaluating Complexity of Task Knowledge Patterns Through Reusability AssessmentDocument17 pagesEvaluating Complexity of Task Knowledge Patterns Through Reusability AssessmentInternational Journal of New Computer Architectures and their Applications (IJNCAA)No ratings yet
- Importance of Similarity Measures in Effective Web Information RetrievalDocument5 pagesImportance of Similarity Measures in Effective Web Information RetrievalEditor IJRITCCNo ratings yet
- PDC Review2Document23 pagesPDC Review2corote1026No ratings yet
- Pascarella2019 Article ClassifyingCodeCommentsInJavaSDocument39 pagesPascarella2019 Article ClassifyingCodeCommentsInJavaSsajidNo ratings yet
- Component Based Software Engineering Research Papers 2013Document5 pagesComponent Based Software Engineering Research Papers 2013fvg93a8vNo ratings yet
- P17 Requirement MeasurementDocument23 pagesP17 Requirement MeasurementRaj VermaNo ratings yet
- A Systematic Literature Review On Convolutional Neural Networks Applied To Single Board ComputersDocument4 pagesA Systematic Literature Review On Convolutional Neural Networks Applied To Single Board Computersmadupiz@gmailNo ratings yet
- Sem Vii Ai 1-8 ExpDocument45 pagesSem Vii Ai 1-8 ExpketanNo ratings yet
- Data Mining in Software Engineering: M. Halkidi, D. Spinellis, G. Tsatsaronis and M. VazirgiannisDocument29 pagesData Mining in Software Engineering: M. Halkidi, D. Spinellis, G. Tsatsaronis and M. VazirgiannisManifa HarramNo ratings yet
- Latest Research Paper Topics in Software EngineeringDocument6 pagesLatest Research Paper Topics in Software EngineeringqhujvirhfNo ratings yet
- RE TutorialDocument20 pagesRE TutorialadvifulNo ratings yet
- Ijcet: International Journal of Computer Engineering & Technology (Ijcet)Document11 pagesIjcet: International Journal of Computer Engineering & Technology (Ijcet)IAEME PublicationNo ratings yet
- A Systematic Literature Review: Software Requirements Prioritization TechniquesDocument6 pagesA Systematic Literature Review: Software Requirements Prioritization TechniquesJanu RomansyahNo ratings yet
- Performance Evaluation of Query Processing Techniques in Information RetrievalDocument6 pagesPerformance Evaluation of Query Processing Techniques in Information RetrievalidescitationNo ratings yet
- Assignment 2Document6 pagesAssignment 2Vardhini AluruNo ratings yet
- Research Paper Topics For Software EngineeringDocument5 pagesResearch Paper Topics For Software Engineeringwroworplg100% (1)
- Case Studies in Just-In-Time Requirements Analysis: NtroductionDocument8 pagesCase Studies in Just-In-Time Requirements Analysis: Ntroductionlindatrummer55No ratings yet
- Document Ranking Using Customizes Vector MethodDocument6 pagesDocument Ranking Using Customizes Vector MethodEditor IJTSRDNo ratings yet
- Dimensionality Reduction in Automated Evaluation of Descriptive Answers Through Zero Variance, Near Zero Variance and Non Frequent Words Techniques - A ComparisonDocument6 pagesDimensionality Reduction in Automated Evaluation of Descriptive Answers Through Zero Variance, Near Zero Variance and Non Frequent Words Techniques - A Comparisonsunil_sixsigmaNo ratings yet
- L4 MacDocument25 pagesL4 MacERENo ratings yet
- Agriculture and Food Systems To 2050Document678 pagesAgriculture and Food Systems To 2050ERENo ratings yet
- A Risk-Based Model For Retirement PlanningDocument15 pagesA Risk-Based Model For Retirement PlanningERENo ratings yet
- Sustainability 12 05817Document26 pagesSustainability 12 05817ERENo ratings yet
- 1540-Văn Bản Của Bài Báo-6239-1-10-20210601Document5 pages1540-Văn Bản Của Bài Báo-6239-1-10-20210601ERENo ratings yet
- Chapter2 CommunicationDocument7 pagesChapter2 CommunicationERENo ratings yet
- Chapter 3 NamingDocument4 pagesChapter 3 NamingERENo ratings yet
- Color-Coding:: Step 1 - Enter Info About Your Company in Yellow Shaded Boxes BelowDocument24 pagesColor-Coding:: Step 1 - Enter Info About Your Company in Yellow Shaded Boxes BelowERENo ratings yet
- Website Usability: - Current Web PresencesDocument10 pagesWebsite Usability: - Current Web PresencesERENo ratings yet
- Asia Pacific Megatrends 2040: Outputs From The First Dialogue of The Asia Pacific Foresight GroupDocument20 pagesAsia Pacific Megatrends 2040: Outputs From The First Dialogue of The Asia Pacific Foresight GroupERENo ratings yet
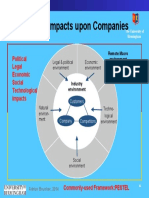
- External Impacts Upon Companies: Political Legal Economic Social Technological ImpactsDocument1 pageExternal Impacts Upon Companies: Political Legal Economic Social Technological ImpactsERENo ratings yet
- The Determination of Optimal Inventory Using Markov Chain: Jurnal Manajemen Teori Dan Terapan Tahun 6. No. 1, April 2013Document12 pagesThe Determination of Optimal Inventory Using Markov Chain: Jurnal Manajemen Teori Dan Terapan Tahun 6. No. 1, April 2013ERENo ratings yet
- Sweetener Conversions C: Sugar 1 TBSP 1/4 Cup 1/3 Cup 1/2 Cup 1 Cup 1 TSPDocument2 pagesSweetener Conversions C: Sugar 1 TBSP 1/4 Cup 1/3 Cup 1/2 Cup 1 Cup 1 TSPERENo ratings yet
- Top 4-2-502Document27 pagesTop 4-2-502bobigenNo ratings yet
- Iso 9001 2015 Mod4 - Clause - 6Document27 pagesIso 9001 2015 Mod4 - Clause - 6Anar Hajiyev100% (1)
- ISTQB Question Paper6Document7 pagesISTQB Question Paper6KapildevNo ratings yet
- 8 Software Requirements Analysis Books For Business AnalystsDocument4 pages8 Software Requirements Analysis Books For Business AnalystsRiaNo ratings yet
- Reg Reporting BADocument2 pagesReg Reporting BAGservices WorksNo ratings yet
- BUS - S302 Study GuideDocument12 pagesBUS - S302 Study GuideAndrewNo ratings yet
- Using Waterfall Iterative and Spiral Models in ERPsystem Implementation Projects Under Uncertaintyjournal of Physics Conference SeriesDocument10 pagesUsing Waterfall Iterative and Spiral Models in ERPsystem Implementation Projects Under Uncertaintyjournal of Physics Conference SeriesJohn JaNo ratings yet
- Quality System Manual DOC. No. QSM - 07 REV. No. 00 Product Realisation Date Page No. 1 of 4Document4 pagesQuality System Manual DOC. No. QSM - 07 REV. No. 00 Product Realisation Date Page No. 1 of 4Sekar KrishNo ratings yet
- ICT Scheme 2020 Batch 5th Term FWC - EnglishDocument12 pagesICT Scheme 2020 Batch 5th Term FWC - Englishஆளப்போறான் தமிழன்No ratings yet
- Workbook Updated To 2008 VerDocument115 pagesWorkbook Updated To 2008 VerIsaiahNo ratings yet
- Programming Methodologies - Quick Guide - TutorialspointDocument25 pagesProgramming Methodologies - Quick Guide - TutorialspointMc Gemrick SantosNo ratings yet
- Course Outline SWDocument2 pagesCourse Outline SWmigadNo ratings yet
- Data Structure and Algorithms Syllabus DrafDocument17 pagesData Structure and Algorithms Syllabus DrafBrittaney BatoNo ratings yet
- Project Proposal On: - Online Health Insurance Information Management System in Worabe CityDocument15 pagesProject Proposal On: - Online Health Insurance Information Management System in Worabe Cityseid mohammed100% (1)
- Sample Proposal 3Document26 pagesSample Proposal 3Ahwera AtensaNo ratings yet
- Risk Management TrainingDocument14 pagesRisk Management TrainingbsjathaulNo ratings yet
- Which One of The Following Is The BEST Definition of An Incremental DevelopmentDocument10 pagesWhich One of The Following Is The BEST Definition of An Incremental DevelopmentReem HaithamNo ratings yet