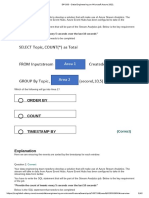
You might also like
- Filmic Pro User Manual V 6Document46 pagesFilmic Pro User Manual V 6rydcocoNo ratings yet
- BCG Matrix PPT of AppleDocument15 pagesBCG Matrix PPT of AppleHEMANSHU JOSHI0% (1)
- NI NewsletterDocument32 pagesNI NewsletterChan Choon KitNo ratings yet
- Iot 5Document10 pagesIot 5Vibha MaithreyiNo ratings yet
- Introduction To IoT PlatformsDocument7 pagesIntroduction To IoT Platformsmohammed.hassanNo ratings yet
- IOT Unit-1 & Unit-3Document124 pagesIOT Unit-1 & Unit-3RavindranathNo ratings yet
- Internship On Industry 4.0 From 12/05/2021 To 12/06/2021 Subject Code: Elis1Document35 pagesInternship On Industry 4.0 From 12/05/2021 To 12/06/2021 Subject Code: Elis1Somesh SinghNo ratings yet
- Bug Tracking System Full DocumentDocument45 pagesBug Tracking System Full Documenthyd javaNo ratings yet
- Intro To Computer Science Assignment Winter SessionDocument6 pagesIntro To Computer Science Assignment Winter Sessionhenry61123No ratings yet
- Iot R16 - Unit-5Document23 pagesIot R16 - Unit-5Surendra KumarNo ratings yet
- Iiaditya Kumam Das CseDocument11 pagesIiaditya Kumam Das Csevishalkumarcs6No ratings yet
- Design Docment Smart Parking System: Ma'am Fakhra AftabDocument13 pagesDesign Docment Smart Parking System: Ma'am Fakhra AftabHaima NaqviNo ratings yet
- Softskill AssignmentDocument5 pagesSoftskill AssignmentSrijan MalNo ratings yet
- CSCC Cloud Customer Architecture For MobileDocument16 pagesCSCC Cloud Customer Architecture For MobilepinardoNo ratings yet
- What Is The IoT TechnologyDocument14 pagesWhat Is The IoT Technologyangopi76No ratings yet
- Cloud Notes 2Document28 pagesCloud Notes 2Ramesh BabuNo ratings yet
- UNIT-3-IOT NotesDocument36 pagesUNIT-3-IOT NotesJay RamNo ratings yet
- Realtime Chat Application Using Client-Server ArchitectureDocument6 pagesRealtime Chat Application Using Client-Server ArchitectureIJRASETPublicationsNo ratings yet
- Major Components of IOTDocument17 pagesMajor Components of IOTPooja PatelNo ratings yet
- IITDocument29 pagesIITAnkita HandaNo ratings yet
- Cloud Computing NotesDocument21 pagesCloud Computing NotesH117 Survase KrutikaNo ratings yet
- Iot ProtocolDocument7 pagesIot ProtocolDivya GoelNo ratings yet
- Digital Technologies – an Overview of Concepts, Tools and Techniques Associated with itFrom EverandDigital Technologies – an Overview of Concepts, Tools and Techniques Associated with itNo ratings yet
- Ca5305.Lecture 4 Levels of Iot Based Systems: Instructor: Dr. M. DeivamaniDocument19 pagesCa5305.Lecture 4 Levels of Iot Based Systems: Instructor: Dr. M. DeivamaniHarini Iyer100% (1)
- IOT-Unit VDocument12 pagesIOT-Unit VBodapati Sai BhargavNo ratings yet
- IOT-Unit VDocument12 pagesIOT-Unit VpavanNo ratings yet
- What Is IT Infrastructure and What Are Its ComponentsDocument7 pagesWhat Is IT Infrastructure and What Are Its ComponentszekariasNo ratings yet
- Design of A Shopping Cart 2Document7 pagesDesign of A Shopping Cart 2d71guhaNo ratings yet
- Md. Moniruzzaman - CC - Assign-1Document4 pagesMd. Moniruzzaman - CC - Assign-1MD Monowar Ul IslamNo ratings yet
- Videoconferencing WebDocument13 pagesVideoconferencing WebCS & ITNo ratings yet
- Extra Reading MaterialDocument36 pagesExtra Reading MaterialchiranssNo ratings yet
- Iot Application Creation Environment: Krish Prabhu, Gian Lecture 5+7Document35 pagesIot Application Creation Environment: Krish Prabhu, Gian Lecture 5+7Surya Ganesh PenagantiNo ratings yet
- Cloud MaterialDocument15 pagesCloud Materialalwinhilton58No ratings yet
- Web Based Collaborative Big Data Analytics On Big Data As A Service PlatformDocument84 pagesWeb Based Collaborative Big Data Analytics On Big Data As A Service PlatformBhavana ReddyNo ratings yet
- A Survey of IoT Cloud ProvidersDocument6 pagesA Survey of IoT Cloud ProvidersAmir AzrenNo ratings yet
- Maa SDocument5 pagesMaa SAhmed ShamsanNo ratings yet
- 题库Document12 pages题库Jon FangNo ratings yet
- A Scalable Framework For Provisioning Large-Scale IoT DeploymentsDocument20 pagesA Scalable Framework For Provisioning Large-Scale IoT Deploymentsselvakrishnan_sNo ratings yet
- Md. Jakir Hossain - CC - Assign-1Document4 pagesMd. Jakir Hossain - CC - Assign-1MD Monowar Ul IslamNo ratings yet
- Internet of Things Platform Approach 0614 1Document13 pagesInternet of Things Platform Approach 0614 1Soumitra DasNo ratings yet
- Application Development - Module 1-2Document10 pagesApplication Development - Module 1-2Jasper Cedrick Lorenzo AbellaNo ratings yet
- Comsware Camera ReadyDocument7 pagesComsware Camera ReadyAhmed RamadanNo ratings yet
- Insetcs ReportDocument37 pagesInsetcs ReportRamesh kNo ratings yet
- Data Handling & Analytics: Unit 5Document18 pagesData Handling & Analytics: Unit 5Arun K KNo ratings yet
- NI Tutorial 3062 enDocument4 pagesNI Tutorial 3062 enkmNo ratings yet
- Business Applications Exam Prep PL-900: Microsoft Power Platform FundamentalsDocument165 pagesBusiness Applications Exam Prep PL-900: Microsoft Power Platform FundamentalsGiancarlo HerreraNo ratings yet
- Online Tracking SystemDocument87 pagesOnline Tracking SystemJaldeepNo ratings yet
- E Challan FIleDocument39 pagesE Challan FIlevishnu075133% (6)
- InsectDocument47 pagesInsectRamesh kNo ratings yet
- Iot Data Collection, Storage and Streaming AnalyticsDocument22 pagesIot Data Collection, Storage and Streaming AnalyticsSurya Ganesh PenagantiNo ratings yet
- Bangladesh University of Professionals (BUP) : Requirements To Transfer Information Technology To A ServiceDocument8 pagesBangladesh University of Professionals (BUP) : Requirements To Transfer Information Technology To A ServiceMD Monowar Ul IslamNo ratings yet
- Compiler Using Cloud ComputingDocument3 pagesCompiler Using Cloud ComputingesatjournalsNo ratings yet
- Embedded Web TechnologyDocument3 pagesEmbedded Web TechnologySneha Nagaruru0% (1)
- Engineering Journal Implementation of Server Side Service Layer in Internet of ThingsDocument3 pagesEngineering Journal Implementation of Server Side Service Layer in Internet of ThingsEngineering JournalNo ratings yet
- 2.1. Organization Profile H-Line Soft Information Technologies Pvt. LTDDocument38 pages2.1. Organization Profile H-Line Soft Information Technologies Pvt. LTDSowjanya RudrojuNo ratings yet
- Midterm Exam Review Questions 1 - NewDocument21 pagesMidterm Exam Review Questions 1 - NewSirus DanhNo ratings yet
- Final Project - Activity RecognitionDocument7 pagesFinal Project - Activity RecognitionElen NguyễnNo ratings yet
- Mobile Botnet DetectionDocument7 pagesMobile Botnet DetectionIJRASETPublicationsNo ratings yet
- 6ed Solutions Chap06Document15 pages6ed Solutions Chap06JesseSpero100% (1)
- GlossaryDocument50 pagesGlossaryparakhurdNo ratings yet
- Design of Android Warehouse Management Software Based On Web ServiceDocument8 pagesDesign of Android Warehouse Management Software Based On Web ServiceAbey DessalegnNo ratings yet
- Computer Science Self Management: Fundamentals and ApplicationsFrom EverandComputer Science Self Management: Fundamentals and ApplicationsNo ratings yet
- Technical Specifications (M1000 Controller) : Control FeaturesDocument2 pagesTechnical Specifications (M1000 Controller) : Control FeaturesHanhan RohandaNo ratings yet
- ID985-E LX Modbus ENG 3-05Document14 pagesID985-E LX Modbus ENG 3-05fabioNo ratings yet
- Chapter 2 Introduction To JavaDocument19 pagesChapter 2 Introduction To JavaAsh LeeNo ratings yet
- Unit 3: Communication Aids and Strategies Using Tools of TechnologyDocument20 pagesUnit 3: Communication Aids and Strategies Using Tools of TechnologyExcenel Lene E. QueralNo ratings yet
- DM LogDocument192 pagesDM LogJasmine HodousNo ratings yet
- AtflDocument12 pagesAtflsujeen killaNo ratings yet
- Data Mining-2-1Document12 pagesData Mining-2-1SOORAJ CHANDRANNo ratings yet
- PH MeterDocument16 pagesPH MeterAmaluddinNo ratings yet
- Operations Reserch Unit 1&2Document35 pagesOperations Reserch Unit 1&2RoNo ratings yet
- E-Healthcare Management System: Final Year ProjectDocument63 pagesE-Healthcare Management System: Final Year ProjectMuhammad AjmalNo ratings yet
- Proof of Correctness - Insertion SortDocument2 pagesProof of Correctness - Insertion SortanjaliNo ratings yet
- Irish Research Council Government of Ireland Postgraduate Scholarship Programme Including Strategic Funding Partner ThemesDocument4 pagesIrish Research Council Government of Ireland Postgraduate Scholarship Programme Including Strategic Funding Partner ThemesRaheem buxNo ratings yet
- 2 Certificate ProblemsDocument1 page2 Certificate Problemsanna8cagiNo ratings yet
- SQL Cheat Sheet:: - by Yash ShirodkarDocument8 pagesSQL Cheat Sheet:: - by Yash ShirodkarUtkarsh HarmukhNo ratings yet
- Pre Upgrade COP 00029 SGN ReadmeDocument5 pagesPre Upgrade COP 00029 SGN ReadmeFlavio AlonsoNo ratings yet
- CCSK OverviewDocument24 pagesCCSK OverviewSaad MotenNo ratings yet
- Assignment 3 Part 1Document20 pagesAssignment 3 Part 1UmairNo ratings yet
- ADC Unit 5 PPT 3Document15 pagesADC Unit 5 PPT 3Himanshu SinghNo ratings yet
- Study Guide: School of Information Technology Department of Computer ScienceDocument12 pagesStudy Guide: School of Information Technology Department of Computer ScienceMadrinaNo ratings yet
- Hybrid PowontrolDocument65 pagesHybrid Powontroljohn alNo ratings yet
- Elite 440 MFM - User - ManualDocument88 pagesElite 440 MFM - User - ManualtusharNo ratings yet
- Yuma Quickstart GuideDocument27 pagesYuma Quickstart GuideAnteJurosNo ratings yet
- Customer Support: Fernando BARRAGAODocument11 pagesCustomer Support: Fernando BARRAGAOTueNo ratings yet
- Summertime Saga All Details and AboutDocument6 pagesSummertime Saga All Details and AboutDavid Luiz Felipe FelianceNo ratings yet
- DP-203 - Data Engineering On Microsoft Azure 2021-1Document42 pagesDP-203 - Data Engineering On Microsoft Azure 2021-1Aayoshi Dutta100% (2)
- Thesis About E-Commerce in The PhilippinesDocument8 pagesThesis About E-Commerce in The Philippineslupitavickreypasadena100% (2)
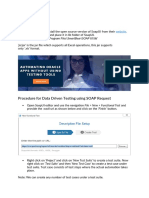
- How To Do Data Driven Testing in SoapUi With GroovyDocument6 pagesHow To Do Data Driven Testing in SoapUi With GroovyGunreddy RamNo ratings yet
- A PRACH Preamble Generation and DetectioDocument8 pagesA PRACH Preamble Generation and DetectioKashif VirkNo ratings yet