
You might also like
- DATA MINING and MACHINE LEARNING: CLUSTER ANALYSIS and kNN CLASSIFIERS. Examples with MATLABFrom EverandDATA MINING and MACHINE LEARNING: CLUSTER ANALYSIS and kNN CLASSIFIERS. Examples with MATLABNo ratings yet
- Methods For Designing Multiple Classifier SystemsDocument10 pagesMethods For Designing Multiple Classifier SystemsRobercy AlvesNo ratings yet
- 2020 Novel Clustering Based Pruning AlgorithmsDocument10 pages2020 Novel Clustering Based Pruning AlgorithmshnavastNo ratings yet
- On Meta-Learning For Dynamic Ensemble Selection: Rafael M. O. Cruz and Robert Sabourin George D. C. CavalcantiDocument6 pagesOn Meta-Learning For Dynamic Ensemble Selection: Rafael M. O. Cruz and Robert Sabourin George D. C. CavalcantiRobercy AlvesNo ratings yet
- META-DES dynamic ensemble selection using meta-learningDocument8 pagesMETA-DES dynamic ensemble selection using meta-learningkakarottoNo ratings yet
- Compressed Sensing EnsembleDocument15 pagesCompressed Sensing EnsembleRathi PriyaNo ratings yet
- A Class-Based Feature Selection Method For Ensemble SystemsDocument6 pagesA Class-Based Feature Selection Method For Ensemble SystemsEbrahim ShiraniNo ratings yet
- (IJCST-V4I4P11) :rajni David Bagul, Prof. Dr. B. D. PhulpagarDocument6 pages(IJCST-V4I4P11) :rajni David Bagul, Prof. Dr. B. D. PhulpagarEighthSenseGroupNo ratings yet
- Ensemble Methods For Classifiers: Department of Industrial Engineering Tel-Aviv UniversityDocument24 pagesEnsemble Methods For Classifiers: Department of Industrial Engineering Tel-Aviv UniversityDiego Ignacio Garcia JuradoNo ratings yet
- PR Assignment 01 - Seemal Ajaz (206979)Document7 pagesPR Assignment 01 - Seemal Ajaz (206979)Azka NawazNo ratings yet
- 1.1 What Is Ensemble Learning: 1.2 Model SelectionDocument18 pages1.1 What Is Ensemble Learning: 1.2 Model SelectionSiva Sankar ChanduNo ratings yet
- Kernel-based fuzzy c-means clustering algorithm optimized by genetic algorithmDocument3 pagesKernel-based fuzzy c-means clustering algorithm optimized by genetic algorithmSelly Anastassia Amellia KharisNo ratings yet
- A Classifier Ensemble of Binary Classifier Ensembles: Hamid Parvin Sajad ParvinDocument8 pagesA Classifier Ensemble of Binary Classifier Ensembles: Hamid Parvin Sajad ParvinijecctNo ratings yet
- A Distance-Based Kernel For Classification Via Support Vector Machines - PMC-19Document1 pageA Distance-Based Kernel For Classification Via Support Vector Machines - PMC-19jefferyleclercNo ratings yet
- A Review of Supervised Learning Based Classification For Text To Speech SystemDocument8 pagesA Review of Supervised Learning Based Classification For Text To Speech SystemInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Pattern Recognition: Rafael M.O. Cruz, Robert Sabourin, George D.C. Cavalcanti, Tsang Ing RenDocument11 pagesPattern Recognition: Rafael M.O. Cruz, Robert Sabourin, George D.C. Cavalcanti, Tsang Ing RenkakarottoNo ratings yet
- Run Xuan Zhang 2007Document11 pagesRun Xuan Zhang 2007VivekNo ratings yet
- Combining Support Vector Machines: 6.1. Introduction and MotivationsDocument20 pagesCombining Support Vector Machines: 6.1. Introduction and MotivationsSummrina KanwalNo ratings yet
- C. Cifarelli Et Al - Incremental Classification With Generalized EigenvaluesDocument25 pagesC. Cifarelli Et Al - Incremental Classification With Generalized EigenvaluesAsvcxvNo ratings yet
- Omega 69 (2017) 126–140 PROMETHEE analysis for ordered multicriteria clusteringDocument15 pagesOmega 69 (2017) 126–140 PROMETHEE analysis for ordered multicriteria clusteringMirna D. OjedaNo ratings yet
- Statistical and Analytical Comparison of Multi-Criteria Decision-Making Techniques Under Fuzzy EnvironmentDocument26 pagesStatistical and Analytical Comparison of Multi-Criteria Decision-Making Techniques Under Fuzzy EnvironmentAdnan FauziRachmanNo ratings yet
- Improvement of K-Means Clustering Algorithm With Better Initial Centroids Based On Weighted AverageDocument5 pagesImprovement of K-Means Clustering Algorithm With Better Initial Centroids Based On Weighted AverageDavid MorenoNo ratings yet
- Cluster 2Document11 pagesCluster 2Vimala PriyaNo ratings yet
- Clusters K ModasDocument13 pagesClusters K Modasjoaquín arrosamenaNo ratings yet
- Optimal Hierarchical Structure Design of Decision Tree SVM Using Distance Based ApproachDocument7 pagesOptimal Hierarchical Structure Design of Decision Tree SVM Using Distance Based ApproachAnonymous lPvvgiQjRNo ratings yet
- Enhancing Decision Combination in Classifier Committee Via Positional VotingDocument11 pagesEnhancing Decision Combination in Classifier Committee Via Positional Votingjacekt89No ratings yet
- Clustering Before ClassificationDocument3 pagesClustering Before Classificationmc awartyNo ratings yet
- Wrapper-Filter Feature Selection Algorithm Using A Memetic FrameworkDocument7 pagesWrapper-Filter Feature Selection Algorithm Using A Memetic FrameworkamitguptakkrnicNo ratings yet
- Objective Criteria for Evaluating Clustering MethodsDocument6 pagesObjective Criteria for Evaluating Clustering Methodsadin80No ratings yet
- Jsen 2020 2985063Document7 pagesJsen 2020 2985063zi yunNo ratings yet
- Classifier Selection For Majority VotingDocument19 pagesClassifier Selection For Majority VotingAhmad ShamyNo ratings yet
- Survey of Clustering Algorithms: Rui Xu, Student Member, IEEE and Donald Wunsch II, Fellow, IEEEDocument34 pagesSurvey of Clustering Algorithms: Rui Xu, Student Member, IEEE and Donald Wunsch II, Fellow, IEEEGülhanEkindereNo ratings yet
- Dynamic Classifier SelectionDocument22 pagesDynamic Classifier SelectionYusuf YeşilyurtNo ratings yet
- Experiential Study of Kernel Functions To Design An Optimized Multi-Class SVMDocument6 pagesExperiential Study of Kernel Functions To Design An Optimized Multi-Class SVMAnonymous lPvvgiQjRNo ratings yet
- Ensemble MethodsDocument15 pagesEnsemble Methodsbrm1shubha100% (1)
- Machine Learning ToolboxDocument10 pagesMachine Learning ToolboxmlaijNo ratings yet
- Deep Convolutional Neural Network Ensembles Using ECOCDocument13 pagesDeep Convolutional Neural Network Ensembles Using ECOCyac bouNo ratings yet
- CRISP-MED-DM A Methodology of Diagnosing Breast CancerDocument13 pagesCRISP-MED-DM A Methodology of Diagnosing Breast CancerInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Ensemble of Machine Learning Algorithms For Intrusion DetectionDocument5 pagesEnsemble of Machine Learning Algorithms For Intrusion DetectioninduvinayNo ratings yet
- Dynamic Selection of Classifiers in Bug Prediction: An Adaptive MethodDocument11 pagesDynamic Selection of Classifiers in Bug Prediction: An Adaptive MethodArijit BNo ratings yet
- ATSC-NEX Automated Time Series Classification With Sequential Model-Based Optimization and Nested Cross-ValidationDocument14 pagesATSC-NEX Automated Time Series Classification With Sequential Model-Based Optimization and Nested Cross-ValidationJuan ZarateNo ratings yet
- Arbelaitz, 2013. Cluster ValidityDocument14 pagesArbelaitz, 2013. Cluster Validityintan wahyuNo ratings yet
- Arbitrating Among Competing Classiers Using Learned RefereesDocument24 pagesArbitrating Among Competing Classiers Using Learned RefereesargamonNo ratings yet
- Gaussian Kernel Optimization For Pattern Classification: Jie Wang, Haiping Lu, Juwei LuDocument28 pagesGaussian Kernel Optimization For Pattern Classification: Jie Wang, Haiping Lu, Juwei LuAnshul SuneriNo ratings yet
- Ensemble LearningDocument21 pagesEnsemble LearningdfnngfffNo ratings yet
- fs/QCA Lecture Notes and ExamplesDocument27 pagesfs/QCA Lecture Notes and ExamplesΤάσος ΚυριακίδηςNo ratings yet
- Supervised Diagnosis of Induction Motor Faults: A Proposed Methodology For An Improved Performance EvaluationDocument7 pagesSupervised Diagnosis of Induction Motor Faults: A Proposed Methodology For An Improved Performance EvaluationboucharebNo ratings yet
- Molecules: Effect of Dataset Size and Train/Test Split Ratios in QSAR/QSPR Multiclass ClassificationDocument16 pagesMolecules: Effect of Dataset Size and Train/Test Split Ratios in QSAR/QSPR Multiclass ClassificationFantaNo ratings yet
- An Effective Support Vector Machines (SVM) Performance Using Hierarchical ClusteringDocument20 pagesAn Effective Support Vector Machines (SVM) Performance Using Hierarchical ClusteringEZ112No ratings yet
- Isntance Selection For Regression Task - Information Fusion JournalDocument11 pagesIsntance Selection For Regression Task - Information Fusion JournalRathi PriyaNo ratings yet
- Fuzzy Clustering Approach To Study The Degree of Aggressiveness in Youth ViolenceDocument5 pagesFuzzy Clustering Approach To Study The Degree of Aggressiveness in Youth ViolenceIIR indiaNo ratings yet
- Determining The Number of Clusterssegments in Hierarchical ClustDocument9 pagesDetermining The Number of Clusterssegments in Hierarchical ClustFabian Isaac Mendoza FloresNo ratings yet
- Lectura 1Document13 pagesLectura 1maria isabel VidalNo ratings yet
- Dechter Constraint ProcessingDocument40 pagesDechter Constraint Processingnani subrNo ratings yet
- Sesmero 2015Document14 pagesSesmero 2015MrPirado 480pNo ratings yet
- Prediction Analysis Techniques of Data Mining: A ReviewDocument7 pagesPrediction Analysis Techniques of Data Mining: A ReviewEdwardNo ratings yet
- Feature Selection Embedded Robust K-Means ClusteringDocument12 pagesFeature Selection Embedded Robust K-Means Clusteringkiran munagalaNo ratings yet
- Unsupervised K-Means Clustering Algorithm Finds Optimal Number of ClustersDocument17 pagesUnsupervised K-Means Clustering Algorithm Finds Optimal Number of ClustersAhmad FaisalNo ratings yet
- Study of Multiclass Classification For Imbalanced Biomedical DataDocument5 pagesStudy of Multiclass Classification For Imbalanced Biomedical DataInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- A Generic Framework For Rule-Based ClassificationDocument18 pagesA Generic Framework For Rule-Based ClassificationTrang VũNo ratings yet
- Using Complexity Measures To Determine The Structure of Directed Acyclic Graphs in Multiclass ClassificationDocument40 pagesUsing Complexity Measures To Determine The Structure of Directed Acyclic Graphs in Multiclass ClassificationedersonschmeingNo ratings yet
- Using Data Complexity Measures For Thresholding in Feature Selection RankersDocument11 pagesUsing Data Complexity Measures For Thresholding in Feature Selection RankersedersonschmeingNo ratings yet
- Using Complexity Measures To Evolve Synthetic Classification DatasetsDocument8 pagesUsing Complexity Measures To Evolve Synthetic Classification DatasetsedersonschmeingNo ratings yet
- The Random Subspace Method For Constructing Decision Forests - HODocument13 pagesThe Random Subspace Method For Constructing Decision Forests - HOedersonschmeingNo ratings yet
- DCC Feature Modeling Explained in 40 CharactersDocument18 pagesDCC Feature Modeling Explained in 40 CharactersedersonschmeingNo ratings yet
- M.tech 1st Year SyllabusDocument13 pagesM.tech 1st Year SyllabusarshiNo ratings yet
- Social Media Integration for EducationDocument19 pagesSocial Media Integration for EducationKizzha GodinezNo ratings yet
- DM GTU Study Material Presentations Unit-5 21052021124400PMDocument63 pagesDM GTU Study Material Presentations Unit-5 21052021124400PMSarvaiya SanjayNo ratings yet
- CS2032 DWM QB PDFDocument5 pagesCS2032 DWM QB PDFvelkarthi92No ratings yet
- ARJUN GIRI Project Report-NielsenDocument52 pagesARJUN GIRI Project Report-NielsenDhanek NathNo ratings yet
- Topic 1: Introduction To Data Mining: Instructor: Chris VolinskyDocument59 pagesTopic 1: Introduction To Data Mining: Instructor: Chris VolinskySalomNo ratings yet
- Amity School of Engineering and Technology: Submitted ToDocument28 pagesAmity School of Engineering and Technology: Submitted ToAishwarya GuptaNo ratings yet
- HMM Credit Card Fraud DetectionDocument20 pagesHMM Credit Card Fraud DetectionvijaybtechNo ratings yet
- Computer Information Systems - EnglishDocument14 pagesComputer Information Systems - EnglishsarahNo ratings yet
- Appendix WekaDocument17 pagesAppendix WekaImranNo ratings yet
- INFORMATICA INTERVIEW QUESTIONSDocument11 pagesINFORMATICA INTERVIEW QUESTIONSmurari_0454168100% (1)
- Data Mining Answer KeyDocument10 pagesData Mining Answer KeyRishabh TiwariNo ratings yet
- Social NetworksDocument5 pagesSocial NetworksDhesa Umali-Ariel Anyayahan100% (1)
- Predicting Start-Up Success With Machine Learning: Francisco Ramadas Da Silva Ribeiro Bento (M2013022)Document98 pagesPredicting Start-Up Success With Machine Learning: Francisco Ramadas Da Silva Ribeiro Bento (M2013022)tushar AgrawalNo ratings yet
- Sentiment Research DFA Review 2Document9 pagesSentiment Research DFA Review 2edo okatiNo ratings yet
- CS413 Q&aDocument31 pagesCS413 Q&adean odeanNo ratings yet
- Ch01.Ppt Data MiningDocument46 pagesCh01.Ppt Data MiningneetamoniNo ratings yet
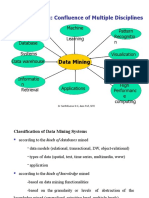
- 4-Confluence of Multiple Disciplines, Classifictaion, Integration-08-Feb-2021Material I 08-Feb-2021 Mod1 Confluence ClassifictaionDocument4 pages4-Confluence of Multiple Disciplines, Classifictaion, Integration-08-Feb-2021Material I 08-Feb-2021 Mod1 Confluence ClassifictaionLikith MallipeddiNo ratings yet
- Data Mining and Business Intelligence AssignmentsDocument2 pagesData Mining and Business Intelligence Assignmentsjerry tomNo ratings yet
- Clustering: K-Means, Agglomerative, DBSCAN: Tan, Steinbach, KumarDocument45 pagesClustering: K-Means, Agglomerative, DBSCAN: Tan, Steinbach, Kumarhub23No ratings yet
- Introduction To Information Technology Turban, Rainer and Potter John Wiley & Sons, IncDocument38 pagesIntroduction To Information Technology Turban, Rainer and Potter John Wiley & Sons, IncAKGNo ratings yet
- Chapter 5Document43 pagesChapter 5Bikila SeketaNo ratings yet
- Exp4 11841524Document8 pagesExp4 11841524catalan153709No ratings yet
- Clustering Analysis of Mall Customer DataDocument15 pagesClustering Analysis of Mall Customer DataMugdha KolheNo ratings yet
- Vol.2 Issue 6Document1,089 pagesVol.2 Issue 6Pragyan Bhattarai100% (1)
- CH 01 - Data and Statistics: Page 1Document35 pagesCH 01 - Data and Statistics: Page 1Hoang Ha100% (2)
- How Can I Become A Data Scientist - QuoraDocument16 pagesHow Can I Become A Data Scientist - QuoraPallav Anand100% (1)
- The Implementation of Decision Tree Algorithm C4.5 Using Rapidminer in Analyzing Dropout StudentsDocument6 pagesThe Implementation of Decision Tree Algorithm C4.5 Using Rapidminer in Analyzing Dropout StudentsFadhil AsyrafNo ratings yet
- Msu Businessanalytics t2Document8 pagesMsu Businessanalytics t2King KhanNo ratings yet
- JSPM'S Bhivarabai Sawant Institute of Technology & Research: Mini Project Report OnDocument33 pagesJSPM'S Bhivarabai Sawant Institute of Technology & Research: Mini Project Report Onkirti reddyNo ratings yet
- Dark Data: Why What You Don’t Know MattersFrom EverandDark Data: Why What You Don’t Know MattersRating: 4.5 out of 5 stars4.5/5 (3)
- Agile Metrics in Action: How to measure and improve team performanceFrom EverandAgile Metrics in Action: How to measure and improve team performanceNo ratings yet
- ITIL 4: Digital and IT strategy: Reference and study guideFrom EverandITIL 4: Digital and IT strategy: Reference and study guideRating: 5 out of 5 stars5/5 (1)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- Mastering PostgreSQL 12 - Third Edition: Advanced techniques to build and administer scalable and reliable PostgreSQL database applications, 3rd EditionFrom EverandMastering PostgreSQL 12 - Third Edition: Advanced techniques to build and administer scalable and reliable PostgreSQL database applications, 3rd EditionNo ratings yet
- Monitored: Business and Surveillance in a Time of Big DataFrom EverandMonitored: Business and Surveillance in a Time of Big DataRating: 4 out of 5 stars4/5 (1)
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLFrom EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLRating: 4.5 out of 5 stars4.5/5 (46)
- IBM DB2 Administration Guide: Installation, Upgrade and Configuration of IBM DB2 on RHEL 8, Windows 10 and IBM Cloud (English Edition)From EverandIBM DB2 Administration Guide: Installation, Upgrade and Configuration of IBM DB2 on RHEL 8, Windows 10 and IBM Cloud (English Edition)No ratings yet
- Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]From EverandMicrosoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]Rating: 5 out of 5 stars5/5 (8)
- Business Intelligence Strategy and Big Data Analytics: A General Management PerspectiveFrom EverandBusiness Intelligence Strategy and Big Data Analytics: A General Management PerspectiveRating: 5 out of 5 stars5/5 (5)
- Joe Celko's SQL for Smarties: Advanced SQL ProgrammingFrom EverandJoe Celko's SQL for Smarties: Advanced SQL ProgrammingRating: 3 out of 5 stars3/5 (1)
- COBOL Basic Training Using VSAM, IMS and DB2From EverandCOBOL Basic Training Using VSAM, IMS and DB2Rating: 5 out of 5 stars5/5 (2)
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureFrom EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureNo ratings yet















































































































![Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]](https://imgv2-2-f.scribdassets.com/img/word_document/610686937/149x198/9ccfa6158e/1713743787?v=1)







