You might also like
- Silicon PhotonicsDocument112 pagesSilicon PhotonicsSabiran GibranNo ratings yet
- ApexCCTV CatalogDocument64 pagesApexCCTV CatalogApexCCTVNo ratings yet
- Surveillance and Target Acquisition Systems (Mark Richardson)Document139 pagesSurveillance and Target Acquisition Systems (Mark Richardson)Daniel CaririNo ratings yet
- Image Super ResolutionDocument8 pagesImage Super ResolutionSam RockNo ratings yet
- Acoustic Emission Testing and Thermographic TestingDocument45 pagesAcoustic Emission Testing and Thermographic TestingShivam GaurNo ratings yet
- E-Learning Material For Aerial Photography & PhotogrammetryDocument141 pagesE-Learning Material For Aerial Photography & PhotogrammetryDr. J. Saravanavel CERS, BDUNo ratings yet
- Applications of Infrared SpectrometryDocument32 pagesApplications of Infrared SpectrometryNgurah MahasviraNo ratings yet
- BiomatricsDocument39 pagesBiomatricsmcahariharanNo ratings yet
- Multi-Grained Attention Network For Infrared and Visible Image FusionDocument12 pagesMulti-Grained Attention Network For Infrared and Visible Image Fusionsamaneh keshavarziNo ratings yet
- A Survey of Image Synthesis and Editing With Generative Adversarial Networks PDFDocument15 pagesA Survey of Image Synthesis and Editing With Generative Adversarial Networks PDFzhenhua wuNo ratings yet
- Infrared and Visible Image Fusion Using A Deep Learning FrameworkDocument6 pagesInfrared and Visible Image Fusion Using A Deep Learning FrameworkSamuele TesfayeNo ratings yet
- Research On GAN-based Image Super-Resolution MethodDocument4 pagesResearch On GAN-based Image Super-Resolution Methodka21ecb0f27No ratings yet
- Infrared and Visible Image Fusion Using A Deep Learning FrameworkDocument6 pagesInfrared and Visible Image Fusion Using A Deep Learning Frameworksamaneh keshavarziNo ratings yet
- 2 - Multi Modality Medical Image Fusion Technique Using Multi Objective Differential Evolution Based Deep Neural NetworksDocument11 pages2 - Multi Modality Medical Image Fusion Technique Using Multi Objective Differential Evolution Based Deep Neural NetworksNguyễn Nhật-NguyênNo ratings yet
- Reviewpaper 2Document3 pagesReviewpaper 2Silvia Satoar PlabonNo ratings yet
- Sensors 23 03282 v2Document22 pagesSensors 23 03282 v2corneli@No ratings yet
- Two-Layer Gaussian Process Regression With Example Selection For Image DehazingDocument13 pagesTwo-Layer Gaussian Process Regression With Example Selection For Image DehazingNew MahoutsukaiNo ratings yet
- Sigasia2018 SVBRDFDocument11 pagesSigasia2018 SVBRDFmoon r jungNo ratings yet
- Advanced Single Image Resolution Upsurging Using A Generative Adversarial NetworkDocument10 pagesAdvanced Single Image Resolution Upsurging Using A Generative Adversarial NetworksipijNo ratings yet
- Ma 等。 - 2020 - Efficient and Fast Real-World Noisy Image DenoisinDocument14 pagesMa 等。 - 2020 - Efficient and Fast Real-World Noisy Image DenoisinNex VinsNo ratings yet
- Unsupervised Densely Attention Network For Infrared and Visible Image FusionDocument12 pagesUnsupervised Densely Attention Network For Infrared and Visible Image Fusionsamaneh keshavarziNo ratings yet
- Forests 14 02188 CompressedDocument17 pagesForests 14 02188 Compresseddarshanmythreya14No ratings yet
- Sensors 23 00043 v2Document15 pagesSensors 23 00043 v2Vikashanand SasikumarNo ratings yet
- LRM: L R M S I 3D: Arge Econstruction Odel For Ingle Mage ToDocument23 pagesLRM: L R M S I 3D: Arge Econstruction Odel For Ingle Mage Tocaxidas953No ratings yet
- (Yuan2018) Image Haze Removal Via Reference Retrieval and Scene PriorDocument15 pages(Yuan2018) Image Haze Removal Via Reference Retrieval and Scene PriorK SavitriNo ratings yet
- Image Restoration Using Deep LearningDocument12 pagesImage Restoration Using Deep LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Ijacsa 1Document8 pagesIjacsa 1WISSALNo ratings yet
- Dwarikanath Mahapatra, Bhavna Antony, Suman Sedai, Rahil GarnaviDocument5 pagesDwarikanath Mahapatra, Bhavna Antony, Suman Sedai, Rahil Garnavisana chibaniNo ratings yet
- Engineering Applications of Artificial Intelligence: Saijie Fan, Wei Liang, Derui Ding, Hui YuDocument11 pagesEngineering Applications of Artificial Intelligence: Saijie Fan, Wei Liang, Derui Ding, Hui YuSameer AhmedNo ratings yet
- A Review On Neural Approaches in Image Processing ApplicationsDocument21 pagesA Review On Neural Approaches in Image Processing ApplicationsIJRASETPublicationsNo ratings yet
- Image Reconstruction Using Deep Neural Networks ModelsDocument7 pagesImage Reconstruction Using Deep Neural Networks ModelsIJRASETPublicationsNo ratings yet
- VoLux-GAN A Generative Model For 3D Face Synthesis With HDRI RelightingDocument17 pagesVoLux-GAN A Generative Model For 3D Face Synthesis With HDRI RelightingFei YinNo ratings yet
- A Generative Adversarial Network With Adaptive ConDocument12 pagesA Generative Adversarial Network With Adaptive ConShrida Prathamesh KalamkarNo ratings yet
- Single Image Dehazing Using Saturation Line PriorDocument16 pagesSingle Image Dehazing Using Saturation Line PriorsrinivasNo ratings yet
- Research Paper Zebra PoseDocument16 pagesResearch Paper Zebra PoseDivyam ShethNo ratings yet
- Remotesensing 13 05111Document21 pagesRemotesensing 13 05111Dragon QueenNo ratings yet
- IET ICETA 2022 - A Conditional Generative Adversarial Network Method For Image Segmentation in Blurry Image - REDUCEDDocument2 pagesIET ICETA 2022 - A Conditional Generative Adversarial Network Method For Image Segmentation in Blurry Image - REDUCEDcinfonNo ratings yet
- Medical Image Fusion Method by Deep LearningDocument9 pagesMedical Image Fusion Method by Deep LearninghgfksqdnhcuiNo ratings yet
- Unet Segmentation Related Works FinDocument5 pagesUnet Segmentation Related Works FinHanane GríssetteNo ratings yet
- Bayesian Fusion For Infrared and Visible ImagesDocument13 pagesBayesian Fusion For Infrared and Visible ImagesSaiprasanth KspNo ratings yet
- Volume GANDocument12 pagesVolume GANFei YinNo ratings yet
- Optik: Hafiz Tayyab Mustafa, Jie Yang, Hamza Mustafa, Masoumeh ZareapoorDocument13 pagesOptik: Hafiz Tayyab Mustafa, Jie Yang, Hamza Mustafa, Masoumeh Zareapoorsamaneh keshavarziNo ratings yet
- Featup - A Model-Agnostic Framework For Features at Any ResolutionDocument27 pagesFeatup - A Model-Agnostic Framework For Features at Any Resolutionbicim22808No ratings yet
- Auto Encoder Driven Hybrid Pipelines For Image Deblurring Using NAFNETDocument6 pagesAuto Encoder Driven Hybrid Pipelines For Image Deblurring Using NAFNETInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- 1 s2.0 S0167739X20330259 MainDocument9 pages1 s2.0 S0167739X20330259 Mainzhujin1121No ratings yet
- Attention-Based Adaptive Feature Selection For Multi-Stage Image DehazingDocument16 pagesAttention-Based Adaptive Feature Selection For Multi-Stage Image Dehazingcodelover0007No ratings yet
- Event Management Using End-To-End Image Encryption A ReviewDocument7 pagesEvent Management Using End-To-End Image Encryption A ReviewIJRASETPublicationsNo ratings yet
- Research Article: Image Classification Algorithm Based On Deep Learning-Kernel FunctionDocument14 pagesResearch Article: Image Classification Algorithm Based On Deep Learning-Kernel FunctionMay Thet TunNo ratings yet
- Large Scale Image Completion Via Co-Modulated Generative Adversarial NetworksDocument25 pagesLarge Scale Image Completion Via Co-Modulated Generative Adversarial Networkstest testNo ratings yet
- Enabling Efficient Deep Convolutional Neural Network-Based Sensor Fusion For Autonomous DrivingDocument6 pagesEnabling Efficient Deep Convolutional Neural Network-Based Sensor Fusion For Autonomous DrivingcthfmzNo ratings yet
- A View-Free Image Stitching Network Based On Global HomographyDocument9 pagesA View-Free Image Stitching Network Based On Global HomographyklammNo ratings yet
- 28548-Article Text-32602-1-2-20240324Document9 pages28548-Article Text-32602-1-2-20240324manik tankalaNo ratings yet
- Research Work 2023Document19 pagesResearch Work 2023Rahul JhaNo ratings yet
- Tip 2021 3051462Document10 pagesTip 2021 3051462murshid zaman bhuiyanNo ratings yet
- Image EnhancementDocument5 pagesImage Enhancementbvkarthik2711No ratings yet
- Joint Learning of Latent Similarity and Local Embedding For Multi-View ClusteringDocument13 pagesJoint Learning of Latent Similarity and Local Embedding For Multi-View ClusteringYijian FanNo ratings yet
- Yaochang 2019Document4 pagesYaochang 2019plovonrNo ratings yet
- Brief Cognizance Into Tampered Image DetectionDocument12 pagesBrief Cognizance Into Tampered Image DetectionIJRASETPublicationsNo ratings yet
- Semantic-Guided Selective Representation For ImageDocument10 pagesSemantic-Guided Selective Representation For ImageTomislav IvandicNo ratings yet
- CAFNET: Cross-Attention Fusion Network For Infrared and Low Illumination Visible-Light ImageDocument15 pagesCAFNET: Cross-Attention Fusion Network For Infrared and Low Illumination Visible-Light ImageokuwobiNo ratings yet
- Kuznetsov 2019 J. Phys. Conf. Ser. 1368 032028Document5 pagesKuznetsov 2019 J. Phys. Conf. Ser. 1368 032028AkshataNo ratings yet
- Nguyen Clusformer A Transformer Based Clustering Approach To Unsupervised Large-Scale Face CVPR 2021 PaperDocument10 pagesNguyen Clusformer A Transformer Based Clustering Approach To Unsupervised Large-Scale Face CVPR 2021 PaperVictor LöfgrenNo ratings yet
- Visual Cross-Image Fusion Using Deep Neural Networks For Image Edge DetectionDocument12 pagesVisual Cross-Image Fusion Using Deep Neural Networks For Image Edge DetectionWilluNo ratings yet
- Realistic Face Image Generation Based On Generative Adversarial NetworkDocument4 pagesRealistic Face Image Generation Based On Generative Adversarial NetworkRaghavendra ShettyNo ratings yet
- Depth Estimation From A Single Image Using Deep Learned Phase Coded MaskDocument12 pagesDepth Estimation From A Single Image Using Deep Learned Phase Coded MaskJ SpencerNo ratings yet
- Generative Adversarial Networks For Image and Video Synthesis: Algorithms and ApplicationsDocument24 pagesGenerative Adversarial Networks For Image and Video Synthesis: Algorithms and ApplicationsHemanth pNo ratings yet
- Global Illumination: Advancing Vision: Insights into Global IlluminationFrom EverandGlobal Illumination: Advancing Vision: Insights into Global IlluminationNo ratings yet
- NNDesignDocument10 pagesNNDesignsamaneh keshavarziNo ratings yet
- Chapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/14/2021Document10 pagesChapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/14/2021samaneh keshavarziNo ratings yet
- Chapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/15/2021Document8 pagesChapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/15/2021samaneh keshavarziNo ratings yet
- Chapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/15/2021Document10 pagesChapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/15/2021samaneh keshavarziNo ratings yet
- Chapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/15/2021Document4 pagesChapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/15/2021samaneh keshavarziNo ratings yet
- Chapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/14/2021Document4 pagesChapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/14/2021samaneh keshavarziNo ratings yet
- Optik: Hafiz Tayyab Mustafa, Jie Yang, Hamza Mustafa, Masoumeh ZareapoorDocument13 pagesOptik: Hafiz Tayyab Mustafa, Jie Yang, Hamza Mustafa, Masoumeh Zareapoorsamaneh keshavarziNo ratings yet
- Unsupervised Densely Attention Network For Infrared and Visible Image FusionDocument12 pagesUnsupervised Densely Attention Network For Infrared and Visible Image Fusionsamaneh keshavarziNo ratings yet
- Chapter 7: Supervised Hebbian Learning: Brandon Morgan 1/13/2021Document2 pagesChapter 7: Supervised Hebbian Learning: Brandon Morgan 1/13/2021samaneh keshavarzi100% (1)
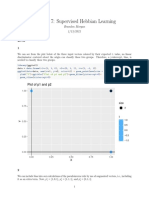
- Chapter 7: Supervised Hebbian Learning: Plot of p1 and p2Document3 pagesChapter 7: Supervised Hebbian Learning: Plot of p1 and p2samaneh keshavarziNo ratings yet
- Chapter 7: Supervised Hebbian Learning: Brandon Morgan 1/13/2021Document2 pagesChapter 7: Supervised Hebbian Learning: Brandon Morgan 1/13/2021samaneh keshavarziNo ratings yet
- Powder Technology: Christian Ullmann, Frank Babick, Robert Koeber, Michael StintzDocument10 pagesPowder Technology: Christian Ullmann, Frank Babick, Robert Koeber, Michael StintzPablo Gomez EcheverriNo ratings yet
- Det Tronics Catalog 2011 2012Document229 pagesDet Tronics Catalog 2011 2012juancko1No ratings yet
- Beauty Catalogo2023 DEFDocument143 pagesBeauty Catalogo2023 DEFzujkajNo ratings yet
- Intelligent Reflecting Surface Aided Wireless Communications: A TutorialDocument74 pagesIntelligent Reflecting Surface Aided Wireless Communications: A TutorialalelignNo ratings yet
- 1565-AAG-FS (OES-Mykonos) IR Inspection - EnglishDocument121 pages1565-AAG-FS (OES-Mykonos) IR Inspection - EnglishRafaelGomesNo ratings yet
- Seeing Heat - Causes of ColorDocument4 pagesSeeing Heat - Causes of ColorCayixNo ratings yet
- Hiasa - 2018 - Bridge Inspection and Condition Assessment Using Image-Based Technologies With UAVsDocument12 pagesHiasa - 2018 - Bridge Inspection and Condition Assessment Using Image-Based Technologies With UAVsBarabingaNo ratings yet
- Camara Dahua Dsdh-Hac-T2a41n-0280bDocument3 pagesCamara Dahua Dsdh-Hac-T2a41n-0280bHenry TorresNo ratings yet
- Infrared System Engineering Infrared System EngineeringDocument2 pagesInfrared System Engineering Infrared System Engineeringgaluh bratalida sNo ratings yet
- Measuring Heat Stress in Industry: Research SummaryDocument12 pagesMeasuring Heat Stress in Industry: Research SummaryIr Moise MatabaroNo ratings yet
- Value Beyond Measure: Updated 7/7/2018Document14 pagesValue Beyond Measure: Updated 7/7/2018AliSultanNo ratings yet
- Physiological Basis of Conducting Physical Education Lessons in Special Conditions of The Outdoor EnvironmentDocument5 pagesPhysiological Basis of Conducting Physical Education Lessons in Special Conditions of The Outdoor EnvironmentAcademic JournalNo ratings yet
- Suas Radiometric Tech Note en PDFDocument4 pagesSuas Radiometric Tech Note en PDFCarlos RiveraNo ratings yet
- CLC Tehnical ReportDocument70 pagesCLC Tehnical ReportAldea CosminNo ratings yet
- Diamond DustDocument2 pagesDiamond DustsashinaNo ratings yet
- Acupuncture Needles and TCM ProductsDocument21 pagesAcupuncture Needles and TCM Productsluke3No ratings yet
- 2 Interaction of Emr With Atomospher, Land, and WaterDocument24 pages2 Interaction of Emr With Atomospher, Land, and WatersahilkaushikNo ratings yet
- Gan Thermal Analysis For High-Performance SystemsDocument15 pagesGan Thermal Analysis For High-Performance SystemsahsoopkNo ratings yet
- A Guide To Lens Selection: AC ( Alternating Current)Document15 pagesA Guide To Lens Selection: AC ( Alternating Current)Anonymous v1oFsM6igNo ratings yet
- How To Write An Scholarship EssayDocument9 pagesHow To Write An Scholarship Essayafabittrf100% (2)
- (AIAA 94-2980) Laser Ignition in Liquid Rocket EnginesDocument13 pages(AIAA 94-2980) Laser Ignition in Liquid Rocket Enginesmaru1318No ratings yet
- Vein Detection Using Infrared For VenepunctureDocument4 pagesVein Detection Using Infrared For VenepunctureAnonymous nM3wBHWxNo ratings yet