You might also like
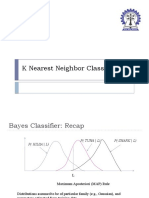
- K Nearest Neighbor ClassificationDocument32 pagesK Nearest Neighbor ClassificationRanjan0% (1)
- ML DSBA Lab4Document5 pagesML DSBA Lab4Houssam FoukiNo ratings yet
- Classifier Conditional Posterior Probabilities: Robert P.W. Duin, David M.J. TaxDocument9 pagesClassifier Conditional Posterior Probabilities: Robert P.W. Duin, David M.J. Taxtidjani86No ratings yet
- Maximum Likelihood Estimation in the Weibull DistributionDocument11 pagesMaximum Likelihood Estimation in the Weibull DistributionRaul DiazNo ratings yet
- Geoff Bohling NonParClassDocument26 pagesGeoff Bohling NonParClassManael RidwanNo ratings yet
- Analysis of Scale Invariance Property Applying HomogeneityDocument6 pagesAnalysis of Scale Invariance Property Applying HomogeneityLuis FuentesNo ratings yet
- 3 Comparison-Of-Conventional-And-Rough-Kmeans-ClusteringDocument8 pages3 Comparison-Of-Conventional-And-Rough-Kmeans-ClusteringAnwar ShahNo ratings yet
- Sis Sonn PDFDocument4 pagesSis Sonn PDFHelloprojectNo ratings yet
- Improved K-Nearest Neighbor Classi"cation: Yingquan Wu, Krassimir Ianakiev, Venu GovindarajuDocument8 pagesImproved K-Nearest Neighbor Classi"cation: Yingquan Wu, Krassimir Ianakiev, Venu GovindarajuTaca RosaNo ratings yet
- PLS-DA for hyperspectral data classificationDocument21 pagesPLS-DA for hyperspectral data classificationJoseNo ratings yet
- Magnetoresistance of Semiconductors Lab ManualDocument24 pagesMagnetoresistance of Semiconductors Lab ManualDhananjay KapseNo ratings yet
- M. B. Yobas, J. N. Crook, D P. Ross - Credit Scoring Using Neural and Evolutionary TechniquesDocument15 pagesM. B. Yobas, J. N. Crook, D P. Ross - Credit Scoring Using Neural and Evolutionary Techniqueshenrique_olivNo ratings yet
- Discrimination and ClassificationDocument7 pagesDiscrimination and ClassificationRushikesh patelNo ratings yet
- Learning Boolean Formulae from ExamplesDocument36 pagesLearning Boolean Formulae from ExamplesAndrei Catalin IlieNo ratings yet
- A Dempster-Shafer Theory: K-Nearest Neighbor Classification Rule Based OnDocument30 pagesA Dempster-Shafer Theory: K-Nearest Neighbor Classification Rule Based OnAhmed SametNo ratings yet
- Nonparametric tests for alternatives with an unknown peak locationDocument14 pagesNonparametric tests for alternatives with an unknown peak locationJames Opoku-AgyapongNo ratings yet
- Kernel Methods in Machine LearningDocument50 pagesKernel Methods in Machine Learningvennela gudimellaNo ratings yet
- Exploring Kernel Density Estimation and Bandwidth Selection MethodsDocument46 pagesExploring Kernel Density Estimation and Bandwidth Selection MethodsOmotayo Abayomi100% (1)
- Chi - Square Test: Dr. Md. NazimDocument9 pagesChi - Square Test: Dr. Md. Nazimdiksha vermaNo ratings yet
- Univariate Density Estimation by Orthogonal Series: Department of Statistics, Oregon State University, CorvallisDocument8 pagesUnivariate Density Estimation by Orthogonal Series: Department of Statistics, Oregon State University, CorvallisJulio SternNo ratings yet
- Goodness-Of-Fit Test For A Logistic Regression Model Fitted Using Survey Sample DataDocument9 pagesGoodness-Of-Fit Test For A Logistic Regression Model Fitted Using Survey Sample DataNigatu AdmasuNo ratings yet
- ChiSquare ExamplesDocument22 pagesChiSquare Examplessrinivasa.reddy1No ratings yet
- Fraiman@email - Unc.edu Lyuben - Lichev@Document12 pagesFraiman@email - Unc.edu Lyuben - Lichev@FRANK BULA MARTINEZNo ratings yet
- JMSS-2013 2Document64 pagesJMSS-2013 2Halil DemolliNo ratings yet
- Fraiman@email - Unc.edu Lyuben - Lichev@Document12 pagesFraiman@email - Unc.edu Lyuben - Lichev@FRANK BULA MARTINEZNo ratings yet
- Random Variables and Probability DistributionsDocument6 pagesRandom Variables and Probability DistributionsYared SisayNo ratings yet
- Nonlinear Observer Design For Smooth SystemsDocument13 pagesNonlinear Observer Design For Smooth Systemsoussama sadkiNo ratings yet
- Dynamic Scaled Sampling For Deterministic ConstraintsDocument9 pagesDynamic Scaled Sampling For Deterministic Constraintsfirefly9xNo ratings yet
- An Improved Algorithm For Imbalanced Data and Small Sample Size ClassificationDocument7 pagesAn Improved Algorithm For Imbalanced Data and Small Sample Size ClassificationvikasbhowateNo ratings yet
- Bondad de AjusteDocument13 pagesBondad de AjusteisristrikisNo ratings yet
- Pattern Recognition Letters: Yong Xu, Qi Zhu, Zizhu Fan, Minna Qiu, Yan Chen, Hong LiuDocument7 pagesPattern Recognition Letters: Yong Xu, Qi Zhu, Zizhu Fan, Minna Qiu, Yan Chen, Hong LiuArsalan TlmNo ratings yet
- A Survey of Dimension Reduction TechniquesDocument18 pagesA Survey of Dimension Reduction TechniquesEulalio Colubio Jr.No ratings yet
- E Classified,: PatternDocument3 pagesE Classified,: Pattern蕭世奇No ratings yet
- 1994 Chen Weighted Sampling Max EntropyDocument14 pages1994 Chen Weighted Sampling Max EntropyRaulNo ratings yet
- Root Finding Methods for Nonlinear EquationsDocument58 pagesRoot Finding Methods for Nonlinear Equationsroysoumyadeep2013No ratings yet
- Logit Models of Individual Choices: Thierry Magnac Université de ToulouseDocument7 pagesLogit Models of Individual Choices: Thierry Magnac Université de ToulouseGerald HartmanNo ratings yet
- International Journal of Pure and Applied Mathematics No. 3 2013, 365-375Document12 pagesInternational Journal of Pure and Applied Mathematics No. 3 2013, 365-375KarthiNo ratings yet
- Kernels and Distances For Structured DataDocument28 pagesKernels and Distances For Structured DataRazzNo ratings yet
- Week 04 Lecture MaterialDocument52 pagesWeek 04 Lecture MaterialMeer HassanNo ratings yet
- A Review of Data Classification Using K-Nearest NeighbourDocument7 pagesA Review of Data Classification Using K-Nearest NeighbourUlmoTolkienNo ratings yet
- Patil Biometrics 1978Document11 pagesPatil Biometrics 1978Feñita Isabêl Arce NuñezNo ratings yet
- HeltonDocument57 pagesHeltonIrenataNo ratings yet
- Nonparametric Density Estimation Nearest Neighbors, KNNDocument31 pagesNonparametric Density Estimation Nearest Neighbors, KNNiam_eckoNo ratings yet
- Jay Orear - Notes On Statistics For Physicists PDFDocument49 pagesJay Orear - Notes On Statistics For Physicists PDFdelenda3No ratings yet
- Part A Statistics Class 1Document3 pagesPart A Statistics Class 1WILMOIS MASTERNo ratings yet
- Lesson 4.1 - Unsupervised Learning Partitioning Methods PDFDocument41 pagesLesson 4.1 - Unsupervised Learning Partitioning Methods PDFTayyaba FaisalNo ratings yet
- Distribution-free Tests for Umbrella AlternativesDocument11 pagesDistribution-free Tests for Umbrella AlternativesJames Opoku-AgyapongNo ratings yet
- Clustering PDFDocument41 pagesClustering PDFMarius_2010No ratings yet
- J. P. Sutcliffe: University of SydneyDocument4 pagesJ. P. Sutcliffe: University of SydneyMd Nazrul Islam MondalNo ratings yet
- Theory For Penalised Spline Regression: Peter - Hall@anu - Edu.auDocument14 pagesTheory For Penalised Spline Regression: Peter - Hall@anu - Edu.auAnn FeeNo ratings yet
- Approximation by Polynomials: Lectures on Approximation by PolynomialsDocument75 pagesApproximation by Polynomials: Lectures on Approximation by PolynomialsLovinf FlorinNo ratings yet
- Feature Selection Via Sensitivity Analysis of SVM Probabilistic OutputsDocument20 pagesFeature Selection Via Sensitivity Analysis of SVM Probabilistic OutputsJoseph JoseNo ratings yet
- Feature Selection For MLP Neural NetworkDocument23 pagesFeature Selection For MLP Neural NetworkaNo ratings yet
- ECE523 Engineering Applications of Machine Learning and Data Analytics - Bayes and Risk - 1Document7 pagesECE523 Engineering Applications of Machine Learning and Data Analytics - Bayes and Risk - 1wandalexNo ratings yet
- Homework QuestionsDocument9 pagesHomework Questionspolar necksonNo ratings yet
- A Cell Growth Model RevisitedDocument16 pagesA Cell Growth Model RevisitedlighthilljNo ratings yet
- K-Nearest Neighbour (KNN)Document14 pagesK-Nearest Neighbour (KNN)Muhammad HaroonNo ratings yet
- A Monte Carlo Algorithm For Simulating Fermions On Lefschetz ThimblesDocument16 pagesA Monte Carlo Algorithm For Simulating Fermions On Lefschetz ThimblesPaulo BedaqueNo ratings yet
- R300 Advanced Econometrics Methods Lecture SlidesDocument362 pagesR300 Advanced Econometrics Methods Lecture SlidesMarco BrolliNo ratings yet
- Plane Stay The AirDocument9 pagesPlane Stay The AirAnonymous 3NmUUDtNo ratings yet
- Tea Master 33139694Document20 pagesTea Master 33139694Anonymous 3NmUUDtNo ratings yet
- 2019-20 Science Olympiad Protein Modeling Event - How To Prepare (Description)Document1 page2019-20 Science Olympiad Protein Modeling Event - How To Prepare (Description)Anonymous 3NmUUDtNo ratings yet
- Julian Gibey TOC NotesDocument1 pageJulian Gibey TOC NotesAnonymous 3NmUUDtNo ratings yet
- 2019-20 Science Olympiad Protein Modeling Event - CRISPR, A Bacterial Adaptive Immunity System (Description)Document1 page2019-20 Science Olympiad Protein Modeling Event - CRISPR, A Bacterial Adaptive Immunity System (Description)Anonymous 3NmUUDtNo ratings yet
- PanopticDocument89 pagesPanopticAnonymous 3NmUUDtNo ratings yet
- 2013 Ul Hasan Icdar Can We Build Lanugage Independent Ocr Using LSTM NetworksDocument6 pages2013 Ul Hasan Icdar Can We Build Lanugage Independent Ocr Using LSTM NetworksAnonymous 3NmUUDtNo ratings yet
- ObjectDocument116 pagesObjectAnonymous 3NmUUDtNo ratings yet
- 2019-20 Science Olympiad Protein Modeling Event - Introduction (Description)Document1 page2019-20 Science Olympiad Protein Modeling Event - Introduction (Description)Anonymous 3NmUUDtNo ratings yet
- Should We Fly in The Lebesgue-Designed Airplane 2007cDocument20 pagesShould We Fly in The Lebesgue-Designed Airplane 2007cAnonymous 3NmUUDtNo ratings yet
- SegmentationDocument36 pagesSegmentationAnonymous 3NmUUDtNo ratings yet
- Ross 2020Document45 pagesRoss 2020Anonymous 3NmUUDtNo ratings yet
- Erlang OTP System Documentation 10.7Document378 pagesErlang OTP System Documentation 10.7Anonymous 3NmUUDtNo ratings yet
- 2 FREE Chapters of Muscle Up Guide PDFDocument30 pages2 FREE Chapters of Muscle Up Guide PDFMarco Torre100% (1)
- Unearthing The Banach-Tarski Paradox (Lebesgue) 0943-0953Document11 pagesUnearthing The Banach-Tarski Paradox (Lebesgue) 0943-0953Anonymous 3NmUUDtNo ratings yet
- Gpu Parallel Program Development CudaDocument477 pagesGpu Parallel Program Development CudaAndrás BenedekNo ratings yet
- Life and Times of Georgy Vorono I (1868-1908) : 1 Ukrainian OriginsDocument30 pagesLife and Times of Georgy Vorono I (1868-1908) : 1 Ukrainian OriginsAnonymous 3NmUUDtNo ratings yet
- Dmathieu Simplest TCP ServerDocument4 pagesDmathieu Simplest TCP ServerAnonymous 3NmUUDtNo ratings yet
- Running A ClusterDocument5 pagesRunning A ClusterAnonymous 3NmUUDtNo ratings yet
- AndyGross Distributed Erlang Systems in OperationDocument16 pagesAndyGross Distributed Erlang Systems in OperationAnonymous 3NmUUDtNo ratings yet
- Learning From Costco's Jim Sinegal: Sol PriceDocument11 pagesLearning From Costco's Jim Sinegal: Sol PriceAnonymous 3NmUUDtNo ratings yet
- Rocket UniVerse Pickuserguide - v1123Document238 pagesRocket UniVerse Pickuserguide - v1123Anonymous 3NmUUDtNo ratings yet
- 2007 - The Structure of Microbial Evolutionary TheoryDocument16 pages2007 - The Structure of Microbial Evolutionary TheoryAnonymous 3NmUUDtNo ratings yet
- Subaru Symmetrical A WD 2Document4 pagesSubaru Symmetrical A WD 2Anonymous 3NmUUDtNo ratings yet
- Damien MATHIEU TCP Server ErlangDocument4 pagesDamien MATHIEU TCP Server ErlangAnonymous 3NmUUDtNo ratings yet
- Changing Cluster InformationDocument8 pagesChanging Cluster InformationAnonymous 3NmUUDtNo ratings yet
- Cardan NotesDocument1 pageCardan NotesAnonymous 3NmUUDtNo ratings yet
- Mixins Considered HarmfulDocument16 pagesMixins Considered HarmfulAnonymous 3NmUUDtNo ratings yet
- The Rise of JavaScript SchedulingDocument8 pagesThe Rise of JavaScript SchedulingAnonymous 3NmUUDtNo ratings yet
- Machine Learning 1Document29 pagesMachine Learning 1Jemin AjudiyaNo ratings yet
- Boosting: 1. What Is The Difference Between Adaboost and Gradient Boosting?Document2 pagesBoosting: 1. What Is The Difference Between Adaboost and Gradient Boosting?JeffNo ratings yet
- First Puc PART-1 STATISTICS FOR ECONOMICSDocument47 pagesFirst Puc PART-1 STATISTICS FOR ECONOMICSjackiechan j100% (1)
- SMS Spam Detection Using Machine LearningDocument9 pagesSMS Spam Detection Using Machine LearningNishant KhandharNo ratings yet
- Data Mining Techniques in Detecting and Predicting Cyber Crimes in Banking SectorDocument5 pagesData Mining Techniques in Detecting and Predicting Cyber Crimes in Banking SectorAll In OneNo ratings yet
- Chi2 Feature Selection and Discretization of Numeric AttributesDocument4 pagesChi2 Feature Selection and Discretization of Numeric AttributesNatsuyuki HanaNo ratings yet
- Machine Learning A Probabilistic ApproachDocument314 pagesMachine Learning A Probabilistic Approachsudhakara.rr359No ratings yet
- MachineLearning Lecture 2Document23 pagesMachineLearning Lecture 2amjad tamishNo ratings yet
- Deep Learning Based Deforestation ClassificationDocument4 pagesDeep Learning Based Deforestation ClassificationM PremNo ratings yet
- Lesson 6 - Unsupervised LearningDocument63 pagesLesson 6 - Unsupervised LearningOmid khosraviNo ratings yet
- Class BasicDocument67 pagesClass Basicbiswajit biswalNo ratings yet
- EPL Prediction Web AppDocument15 pagesEPL Prediction Web AppAashutosh SinhaNo ratings yet
- MachineLearning PresentationDocument71 pagesMachineLearning PresentationRam PrasadNo ratings yet
- Dau PDFDocument227 pagesDau PDFRohit GputaNo ratings yet
- Um Tutorial Usando o Pacote Rminer No Gnu RDocument59 pagesUm Tutorial Usando o Pacote Rminer No Gnu RdbmestNo ratings yet
- NNFL - Psa, PSD, Eds BitsDocument64 pagesNNFL - Psa, PSD, Eds BitsSandeep_Nara_3783No ratings yet
- Assignment 3Document5 pagesAssignment 3Siddhant SanjeevNo ratings yet
- Chapter-2-Methods of Data PresentationDocument17 pagesChapter-2-Methods of Data Presentationkenenisa.abdisastatNo ratings yet
- Sentiment Analysis Using Bert On Yelp Restaurant ReviewsDocument63 pagesSentiment Analysis Using Bert On Yelp Restaurant Reviews19131A05H9 POPURI TRIVENINo ratings yet
- Be The Outlier - How To Ace Data Science Interviews - Shrilata MurthyDocument150 pagesBe The Outlier - How To Ace Data Science Interviews - Shrilata MurthyMa Ga100% (2)
- W7 Weka ExperimenterDocument6 pagesW7 Weka ExperimenterAzfar JijiNo ratings yet
- 2108 ArticleText 3776 1 10 20190403Document13 pages2108 ArticleText 3776 1 10 20190403Shujat Hussain GadiNo ratings yet
- Rosenblatt's Perceptron: Neural Networks and Learning Machines, Third EditionDocument12 pagesRosenblatt's Perceptron: Neural Networks and Learning Machines, Third Editionkaushik73No ratings yet
- IJACSA Volume3No1Document210 pagesIJACSA Volume3No1Editor IJACSANo ratings yet
- Gujarat Technological University: Page 1 of 2Document2 pagesGujarat Technological University: Page 1 of 2Er Umesh ThoriyaNo ratings yet
- Fault Detection System For Centrifugal Pumps Using Neural Networks and Neuro-Fuzzy TechniquesDocument9 pagesFault Detection System For Centrifugal Pumps Using Neural Networks and Neuro-Fuzzy TechniquesTetria AdwineldaNo ratings yet
- Image Steganalysis With Binary Similarity MeasuresDocument9 pagesImage Steganalysis With Binary Similarity MeasuresInformatika Universitas MalikussalehNo ratings yet
- Week 6 Decision TreesDocument47 pagesWeek 6 Decision TreessinanahmedofficalNo ratings yet
- Machine Learning For Hackers PDFDocument5 pagesMachine Learning For Hackers PDFninjapunit0% (4)
- Machine Learning Made Easy: A Review of Scikit-Learn Package in Python Programming LanguageDocument14 pagesMachine Learning Made Easy: A Review of Scikit-Learn Package in Python Programming Languagejuan carlosNo ratings yet