You might also like
- Complete French Learn French With Teach YourselfDocument513 pagesComplete French Learn French With Teach YourselfAnastasi100% (3)
- COT RPMS Rating Sheet For T I III For Sy 2023 2024Document1 pageCOT RPMS Rating Sheet For T I III For Sy 2023 2024Maiden Pascua98% (46)
- Completed Literacy Folio Edu80016Document27 pagesCompleted Literacy Folio Edu80016api-341010652100% (1)
- Image Super ResolutionDocument8 pagesImage Super ResolutionSam RockNo ratings yet
- Ch1 ReviewDocument4 pagesCh1 ReviewElizabeth DentlingerNo ratings yet
- Vision Transformers: Revolutionizing Computer VisionDocument14 pagesVision Transformers: Revolutionizing Computer VisionPremanand SubramaniNo ratings yet
- Program Proposal: St. Paul University Philippines Tuguegarao City, Cagayan 3500Document8 pagesProgram Proposal: St. Paul University Philippines Tuguegarao City, Cagayan 3500Danica Lorine Robino TaguinodNo ratings yet
- Densepose: Dense Human Pose Estimation in The Wild: Seminar: Vision Systems Ma-Inf 4208Document10 pagesDensepose: Dense Human Pose Estimation in The Wild: Seminar: Vision Systems Ma-Inf 4208Jelena TrajkovicNo ratings yet
- From Words To Pictures Artificial Intelligence Based Art GeneratorDocument9 pagesFrom Words To Pictures Artificial Intelligence Based Art GeneratorInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- And The Bit Goes DownDocument11 pagesAnd The Bit Goes Downgireesh123123No ratings yet
- 2021 - AAAI-RpBERT - A Text-Image Relation Propagation-Based BERT Model For Multimodal NERDocument9 pages2021 - AAAI-RpBERT - A Text-Image Relation Propagation-Based BERT Model For Multimodal NERzhao tongNo ratings yet
- NeurIPS 2019 Image Captioning Transforming Objects Into Words PaperDocument11 pagesNeurIPS 2019 Image Captioning Transforming Objects Into Words Paperyazhini shanmugamNo ratings yet
- Text-to-Image Generation Using Deep LearningDocument6 pagesText-to-Image Generation Using Deep Learningexperimental mechanicsNo ratings yet
- Narrative Paragraph GenerationDocument13 pagesNarrative Paragraph Generationsid202pkNo ratings yet
- PGCON Paper FinalDocument4 pagesPGCON Paper FinalArbaaz ShaikhNo ratings yet
- Pami Im2Show and Tell: Lessons Learned From The 2015 MSCOCO Image Captioning ChallengeDocument12 pagesPami Im2Show and Tell: Lessons Learned From The 2015 MSCOCO Image Captioning ChallengeJordan NovetNo ratings yet
- Automated Caption Generator For The Visually Imapired: Abstract: Automated Captioning of Photos Is A Mission ThatDocument6 pagesAutomated Caption Generator For The Visually Imapired: Abstract: Automated Captioning of Photos Is A Mission ThatanchalNo ratings yet
- Textually Enriched Neural Module Networks For Visual Question AnsweringDocument9 pagesTextually Enriched Neural Module Networks For Visual Question AnsweringMattNo ratings yet
- Automatic Image Captioning Combining Natural Language Processing andDocument14 pagesAutomatic Image Captioning Combining Natural Language Processing andMebratu AbuyeNo ratings yet
- Algorithms: A Combined Full-Reference Image Quality Assessment Method Based On Convolutional Activation MapsDocument21 pagesAlgorithms: A Combined Full-Reference Image Quality Assessment Method Based On Convolutional Activation MapsCẩm Tú CầuNo ratings yet
- Multilayer Dense Attention Model For Image CaptionDocument11 pagesMultilayer Dense Attention Model For Image CaptionPallavi BhartiNo ratings yet
- Open Ended VQA Models Using TransformersDocument10 pagesOpen Ended VQA Models Using TransformersRavi KNo ratings yet
- 1 s2.0 S2468502X21000590 MainDocument8 pages1 s2.0 S2468502X21000590 Mainmirandasuryaprakash_No ratings yet
- A Method For Comparing Content Based Image Retrieval MethodsDocument8 pagesA Method For Comparing Content Based Image Retrieval MethodsAtul GuptaNo ratings yet
- Conference Paper A5Document9 pagesConference Paper A520at1a3145No ratings yet
- Project ReportDocument62 pagesProject ReportPulkit ChauhanNo ratings yet
- Text To Image Synthesis Using SelfDocument20 pagesText To Image Synthesis Using SelfPG GuidesNo ratings yet
- Image Caption Generator Final ReportDocument28 pagesImage Caption Generator Final ReportzaaaawarNo ratings yet
- Image Caption Generator Using AI: Review - 1Document9 pagesImage Caption Generator Using AI: Review - 1Anish JamedarNo ratings yet
- M.Phil Computer Science Image Processing ProjectsDocument27 pagesM.Phil Computer Science Image Processing ProjectskasanproNo ratings yet
- Graph TreeDocument20 pagesGraph TreeUyen NhiNo ratings yet
- Wukong-CMNER: A Large-Scale Chinese Multimodal NER Dataset With Images ModalityDocument15 pagesWukong-CMNER: A Large-Scale Chinese Multimodal NER Dataset With Images Modalityzhao tongNo ratings yet
- ResGANet PDFDocument17 pagesResGANet PDFkamrulhasanbdyahoo.comNo ratings yet
- Thesis Report On Image DenoisingDocument8 pagesThesis Report On Image Denoisingafkofcwjq100% (2)
- C R: E R M - F I D G: Ontext EF Valuating Eferenceless ET Rics OR Mage Escription EnerationDocument18 pagesC R: E R M - F I D G: Ontext EF Valuating Eferenceless ET Rics OR Mage Escription Enerationperson4115No ratings yet
- Systematic Evaluation of Convolution Neural Network Advances On The Imagenet-2017Document9 pagesSystematic Evaluation of Convolution Neural Network Advances On The Imagenet-2017Jorge Velasquez RamosNo ratings yet
- Aic - 2022 - 35 2 - Aic 35 2 Aic210172 - Aic 35 Aic210172Document19 pagesAic - 2022 - 35 2 - Aic 35 2 Aic210172 - Aic 35 Aic210172mohamed walidNo ratings yet
- Text-to-Image Generation With Attention Based Recurrent Neural NetworksDocument11 pagesText-to-Image Generation With Attention Based Recurrent Neural Networksİlayda AltunNo ratings yet
- 1.convolutional Neural Networks For Image ClassificationDocument11 pages1.convolutional Neural Networks For Image ClassificationMuhammad ShoaibNo ratings yet
- Convolutional Knowledge Graph EmbeddingsDocument8 pagesConvolutional Knowledge Graph Embeddingsphanpeter_492No ratings yet
- 4924-Article Text-7990-1-10-20190709Document8 pages4924-Article Text-7990-1-10-20190709TushirNo ratings yet
- An Improved Automatic Image Annotation Approach Using Convolutional Neural Network-Slantlet TransformDocument13 pagesAn Improved Automatic Image Annotation Approach Using Convolutional Neural Network-Slantlet TransformsemNo ratings yet
- Sensors: Image Captioning Using Motion-CNN With Object DetectionDocument13 pagesSensors: Image Captioning Using Motion-CNN With Object Detectionmirandasuryaprakash_No ratings yet
- A CNN-RNN Framework For Image Annotation From Visual Cues and Social Network MetadataDocument8 pagesA CNN-RNN Framework For Image Annotation From Visual Cues and Social Network MetadatadoktorgoldfischNo ratings yet
- FlowNet - Learning Optical Flow With CNNDocument9 pagesFlowNet - Learning Optical Flow With CNNsobuz visualNo ratings yet
- Training-Free, Single-Image Super-Resolution Using A Dynamic Convolutional NetworkDocument5 pagesTraining-Free, Single-Image Super-Resolution Using A Dynamic Convolutional NetworkChaitali ParalikarNo ratings yet
- Real Time Object Detection Using CNNDocument5 pagesReal Time Object Detection Using CNNyevanNo ratings yet
- Real-Time Semantic Slam With DCNN-based Feature Point Detection, Matching and Dense Point Cloud AggregationDocument6 pagesReal-Time Semantic Slam With DCNN-based Feature Point Detection, Matching and Dense Point Cloud AggregationJUAN CAMILO TORRES MUNOZNo ratings yet
- Data Science Interview Questions (#Day27)Document18 pagesData Science Interview Questions (#Day27)ARPAN MAITYNo ratings yet
- Multi-Digit Number Recognition From Street View Imagery Using Deep Convolutional Neural NetworksDocument12 pagesMulti-Digit Number Recognition From Street View Imagery Using Deep Convolutional Neural NetworksSalvation TivaNo ratings yet
- Deep Visual-Semantic Alignments For Generating Image DescriptionsDocument17 pagesDeep Visual-Semantic Alignments For Generating Image DescriptionsJosephNo ratings yet
- Segmenting Scenes by Matching Image CompositesDocument9 pagesSegmenting Scenes by Matching Image CompositesmachinelearnerNo ratings yet
- Irjet V6i6499Document7 pagesIrjet V6i6499bossNo ratings yet
- Image Caption Generator: Review - 1Document9 pagesImage Caption Generator: Review - 1Anish JamedarNo ratings yet
- Abstract:: Literature SurveyDocument3 pagesAbstract:: Literature SurveyTirth ShahNo ratings yet
- 4823-Article Text-7889-1-10-20190709Document9 pages4823-Article Text-7889-1-10-20190709Binay AdhikariNo ratings yet
- Science China Information Sciences: Isha PATHAK & Deo Prakash VIDYARTHIDocument12 pagesScience China Information Sciences: Isha PATHAK & Deo Prakash VIDYARTHIAmira AzzezNo ratings yet
- Thesis On Content Based Image RetrievalDocument7 pagesThesis On Content Based Image Retrievalamberrodrigueznewhaven100% (2)
- Report: Trends in Generative ModelsDocument10 pagesReport: Trends in Generative Modelsggmmdd hhhxbNo ratings yet
- Sensors: Depth Estimation and Semantic Segmentation From A Single RGB Image Using A Hybrid Convolutional Neural NetworkDocument20 pagesSensors: Depth Estimation and Semantic Segmentation From A Single RGB Image Using A Hybrid Convolutional Neural NetworkKratika VarshneyNo ratings yet
- Paper 91-Comparative Evaluation of CNN ArchitecturesDocument9 pagesPaper 91-Comparative Evaluation of CNN Architecturessebampitako duncanNo ratings yet
- A Study On Similar Image Finder Using Deep LearningDocument15 pagesA Study On Similar Image Finder Using Deep Learningsahil singhNo ratings yet
- Sketch-To-Face Image Translation and Enhancement Using A Multi-GAN ApproachDocument7 pagesSketch-To-Face Image Translation and Enhancement Using A Multi-GAN ApproachIJRASETPublicationsNo ratings yet
- Major Project On: "Age and Gender Detection Master''Document28 pagesMajor Project On: "Age and Gender Detection Master''Vijay LakshmiNo ratings yet
- Monitoring Tool in EsP 2020Document22 pagesMonitoring Tool in EsP 2020Carina Batin ManzanilloNo ratings yet
- Prime SystemDocument39 pagesPrime SystemThio CurlsNo ratings yet
- Madeline Cho Letter of Recommendation 3Document1 pageMadeline Cho Letter of Recommendation 3api-2965614320% (1)
- 09-11-2011 Weekly EvalDocument3 pages09-11-2011 Weekly Evalapi-105224564No ratings yet
- Guide Book Iiiex 2023Document15 pagesGuide Book Iiiex 2023kanya parameswariNo ratings yet
- Lecture 1 Introduction To Business Research MethodsDocument23 pagesLecture 1 Introduction To Business Research MethodsEng MatanaNo ratings yet
- IMPROVING THE STUDENTS' SPEAKING SKILL THROUGH STORY JOKE TECHNIQUE Chapter IDocument12 pagesIMPROVING THE STUDENTS' SPEAKING SKILL THROUGH STORY JOKE TECHNIQUE Chapter IdwiNo ratings yet
- Bahasa Ancaman Dalam Teks Kaba Sabai Nan Aluih Berbasis Pendekatan Linguistik ForensikDocument17 pagesBahasa Ancaman Dalam Teks Kaba Sabai Nan Aluih Berbasis Pendekatan Linguistik ForensikTentakle YoungNo ratings yet
- TFNDocument21 pagesTFNPrincess Rodginia Mae MagayonNo ratings yet
- 1 MR Mock Interview Questions and EvaluationDocument3 pages1 MR Mock Interview Questions and Evaluationapi-268290595No ratings yet
- MBM Midteerm ExamDocument3 pagesMBM Midteerm ExamLDRRMO RAMON ISABELANo ratings yet
- Conceptualizing Guilt in The Consumer Decision-Making ProcessDocument11 pagesConceptualizing Guilt in The Consumer Decision-Making ProcessNikmatur RahmahNo ratings yet
- Personal Development Chapter 5Document53 pagesPersonal Development Chapter 5Edilene Rosallosa CruzatNo ratings yet
- 4 4 Resilience Circle Time ExtractDocument2 pages4 4 Resilience Circle Time Extractapi-254366715No ratings yet
- DLL 2020 MydevDocument8 pagesDLL 2020 MydevJoseph BirungNo ratings yet
- Presentation On Reading SkillsDocument43 pagesPresentation On Reading SkillsSehar KhanNo ratings yet
- Guia Ingles 1Document28 pagesGuia Ingles 1Lore CeNo ratings yet
- St. Mary's Educational Institute: Online Learning 1Document10 pagesSt. Mary's Educational Institute: Online Learning 1Janine Rose MendozaNo ratings yet
- What Is Attitude?: Paula Exposito Chapter 5 - High Effort AttitudeDocument6 pagesWhat Is Attitude?: Paula Exposito Chapter 5 - High Effort AttitudePaula Expósito CanalNo ratings yet
- Pilar Orero Editor Topics in Audiovisual TranslatiDocument4 pagesPilar Orero Editor Topics in Audiovisual TranslatiWagner NogueiraNo ratings yet
- Factors Affecting The English Proficiency of Junior High StudentsDocument7 pagesFactors Affecting The English Proficiency of Junior High StudentsGertrude Miyacah GomezNo ratings yet
- The Namesake Interactive Novel StudyDocument41 pagesThe Namesake Interactive Novel StudyGeraldine QuirogaNo ratings yet
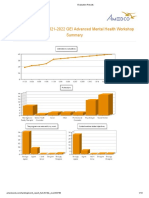
- Advanced Mental Health Evaluation ResultsDocument13 pagesAdvanced Mental Health Evaluation ResultsVictor NamurNo ratings yet
- Using Commands To Direct BehaviorDocument2 pagesUsing Commands To Direct BehaviorVy HạNo ratings yet
- Schools of Educational PhilosophyDocument1 pageSchools of Educational PhilosophyEdwin EstreraNo ratings yet