You might also like
- Online Grocery Recommendation System: January 2016Document5 pagesOnline Grocery Recommendation System: January 2016Manasi BondeNo ratings yet
- CCPS521-WIN2023-Week12 Recommender Systems V02Document52 pagesCCPS521-WIN2023-Week12 Recommender Systems V02Charles KingstonNo ratings yet
- A Proposed Hybrid Book Recommender System: Suhas PatilDocument5 pagesA Proposed Hybrid Book Recommender System: Suhas PatilArnav GudduNo ratings yet
- Recommendation Systems: Department of Computer Science Engineering University School of Information and TechnologyDocument6 pagesRecommendation Systems: Department of Computer Science Engineering University School of Information and Technologyajaykumar_domsNo ratings yet
- Users Ranking Pattern Based Trust Model Regularization in Product RecommendationDocument11 pagesUsers Ranking Pattern Based Trust Model Regularization in Product RecommendationIJRASETPublicationsNo ratings yet
- CCPS521 WIN2023 Week12 Recommender SystemsDocument49 pagesCCPS521 WIN2023 Week12 Recommender SystemsCharles KingstonNo ratings yet
- Survey Paper On Recommendation EngineDocument9 pagesSurvey Paper On Recommendation EngineAnonymous JKGPDGNo ratings yet
- LITERATURE SURVEY ON RECOMMENDATION ENGINEaperDocument9 pagesLITERATURE SURVEY ON RECOMMENDATION ENGINEaperBhupender YadavNo ratings yet
- (IJETA-V3I6P3) :mrs S VidyaDocument9 pages(IJETA-V3I6P3) :mrs S VidyaIJETA - EighthSenseGroupNo ratings yet
- Operations Research and Recommender Systems: June 2014Document12 pagesOperations Research and Recommender Systems: June 2014Hamza MaftahNo ratings yet
- Implementing A Recommender System With Graph Database: SeminarDocument26 pagesImplementing A Recommender System With Graph Database: SeminarVFisaNo ratings yet
- A Hybrid Collaborative Filtering Method For Multiple-Interests and Multiple-Content Recommendation in E-CommerceDocument12 pagesA Hybrid Collaborative Filtering Method For Multiple-Interests and Multiple-Content Recommendation in E-CommerceRean AstawanNo ratings yet
- Recommendation With Data Mining Algorithms For E-Commerce and M-Commerce ApplicationsDocument4 pagesRecommendation With Data Mining Algorithms For E-Commerce and M-Commerce ApplicationsInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Recommender System - Module 1 - Introduction To Recommender SystemDocument49 pagesRecommender System - Module 1 - Introduction To Recommender SystemDainikMitraNo ratings yet
- Cloud-Based Context Aware - Recommender SystemDocument7 pagesCloud-Based Context Aware - Recommender System[04] - Abrar ShahNo ratings yet
- Ijtra 140854Document6 pagesIjtra 140854Akshay Kumar PandeyNo ratings yet
- RS Unit 1Document13 pagesRS Unit 12k21cse093No ratings yet
- AI Recommendation SystemDocument20 pagesAI Recommendation SystemChitra ParsailaNo ratings yet
- 1 s2.0 S1877050915003117 MainDocument9 pages1 s2.0 S1877050915003117 MainSyam sundharNo ratings yet
- A Survey For Personalized Item Based Recommendation SystemDocument3 pagesA Survey For Personalized Item Based Recommendation SystemInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- A Literature Review and Classification of Recommender Systems Research PDFDocument7 pagesA Literature Review and Classification of Recommender Systems Research PDFea6qsxqdNo ratings yet
- Ijaret: International Journal of Advanced Research in Engineering and Technology (Ijaret)Document8 pagesIjaret: International Journal of Advanced Research in Engineering and Technology (Ijaret)IAEME PublicationNo ratings yet
- Recommendation SystemsDocument31 pagesRecommendation Systemsfabrizio01No ratings yet
- Recommender System Using Collaborative Filtering and Demographic Characteristics of UsersDocument7 pagesRecommender System Using Collaborative Filtering and Demographic Characteristics of UsersEditor IJRITCCNo ratings yet
- Personalized Retail Recommendations Using Big DataDocument13 pagesPersonalized Retail Recommendations Using Big DataSMNo ratings yet
- Topic:-Product Recommendation System Using Machine LearningDocument26 pagesTopic:-Product Recommendation System Using Machine LearningNachiket DhampalwarNo ratings yet
- Information Processing and Management: Shu-Hsien Liao, Hsiao-Ko ChangDocument19 pagesInformation Processing and Management: Shu-Hsien Liao, Hsiao-Ko Changbharathi rNo ratings yet
- Recommendation SystemDocument11 pagesRecommendation SystemHugo SouzaNo ratings yet
- Product Review Analysis With Filtering Vulgarity & Ranking System Based On Transaction & OtpDocument4 pagesProduct Review Analysis With Filtering Vulgarity & Ranking System Based On Transaction & OtpijcnesNo ratings yet
- New Recommendation Techniques For Multi-Criteria Rating SystemsDocument28 pagesNew Recommendation Techniques For Multi-Criteria Rating SystemsVaibhav HiwaseNo ratings yet
- Report Movie RecommendationDocument49 pagesReport Movie RecommendationChris Sosa JacobNo ratings yet
- Parameter Influence Analysis of Deep Autoencoder for Recommender SystemsDocument11 pagesParameter Influence Analysis of Deep Autoencoder for Recommender SystemsĐứcĐiệuNo ratings yet
- Module 1Document105 pagesModule 1Sri Karthik AvalaNo ratings yet
- Review of Clustering-Based Recommender Systems: September 2021Document23 pagesReview of Clustering-Based Recommender Systems: September 2021Lê Minh ĐứcNo ratings yet
- Learn About Conjoint Analysis in 40 CharactersDocument3 pagesLearn About Conjoint Analysis in 40 Charactersvedavyas21No ratings yet
- Temporal Recommenders Apply DataDocument1 pageTemporal Recommenders Apply DataSrinivasNo ratings yet
- Recommendation System FinalDocument16 pagesRecommendation System Finalmanoj.s14252No ratings yet
- Connecting Social Media To E-Commerce: Cold-Start Product RecommendationDocument4 pagesConnecting Social Media To E-Commerce: Cold-Start Product RecommendationInternational Journal Of Emerging Technology and Computer ScienceNo ratings yet
- Freemium Economics: Leveraging Analytics and User Segmentation to Drive RevenueFrom EverandFreemium Economics: Leveraging Analytics and User Segmentation to Drive RevenueRating: 4.5 out of 5 stars4.5/5 (2)
- The Design of Web Based Car Recommendation SystemDocument5 pagesThe Design of Web Based Car Recommendation SystemGiovanni FirrincieliNo ratings yet
- Introduction To Rec Om Mender Systems, Algorithms and EvaluationDocument4 pagesIntroduction To Rec Om Mender Systems, Algorithms and EvaluationddeepakkumarNo ratings yet
- Recommendation System On Cloud Environment A Descriptive Study On This Marketing StrategyDocument10 pagesRecommendation System On Cloud Environment A Descriptive Study On This Marketing StrategyIJRASETPublicationsNo ratings yet
- IS ReportDocument5 pagesIS ReportSiddhant KarnaniNo ratings yet
- A Case Study of Exploiting Data Mining TechniquesDocument8 pagesA Case Study of Exploiting Data Mining TechniquesAdam GraphiandanaNo ratings yet
- Recommendations Based on Purchase Patterns: Analyzing Real Transaction Data to Improve Location-Based RecommendationsDocument4 pagesRecommendations Based on Purchase Patterns: Analyzing Real Transaction Data to Improve Location-Based RecommendationsdavidNo ratings yet
- Irjet V8i4168Document5 pagesIrjet V8i4168Bollam Pragnya 518No ratings yet
- ETE 300 Final Report PDFDocument4 pagesETE 300 Final Report PDFETE 18No ratings yet
- Hybrid Recommendation Solution For Online Book PortalDocument7 pagesHybrid Recommendation Solution For Online Book PortalIJRASETPublicationsNo ratings yet
- Project Synopsis PDFDocument11 pagesProject Synopsis PDFHarsh NegiNo ratings yet
- Study of Recommender Systems Techniques: Shreya Gangan, Khyati Pawde, Niharika Purbey, Prof. Sindhu NairDocument4 pagesStudy of Recommender Systems Techniques: Shreya Gangan, Khyati Pawde, Niharika Purbey, Prof. Sindhu NairerpublicationNo ratings yet
- Online Shopping Recommendation Mechanism and Its in Uence On Consumer Decisions and Behaviors: A Causal Map ApproachDocument8 pagesOnline Shopping Recommendation Mechanism and Its in Uence On Consumer Decisions and Behaviors: A Causal Map ApproachTrí VõNo ratings yet
- Group 5: Recommendation Systems: Course Title Course CodeDocument4 pagesGroup 5: Recommendation Systems: Course Title Course CodeTanue Ngu AlfredNo ratings yet
- Decision Support Systems: Xiaolin Zheng, Shuai Zhu, Zhangxi LinDocument12 pagesDecision Support Systems: Xiaolin Zheng, Shuai Zhu, Zhangxi LinRuchika PrasadNo ratings yet
- Trends, Problems and Solutions of Recommender System: ArticleDocument5 pagesTrends, Problems and Solutions of Recommender System: Articleabhinav pachauriNo ratings yet
- A Survey of Azure ML Recommender SystemDocument5 pagesA Survey of Azure ML Recommender SystemEditor IJRITCCNo ratings yet
- KBRS A SurveyDocument24 pagesKBRS A Surveykiet nguyenNo ratings yet
- Nhom 12Document15 pagesNhom 12Cảnh bạchNo ratings yet
- Recommender SystemsDocument6 pagesRecommender SystemsVIVA-TECH IJRINo ratings yet
- The UX Five-Second Rules: Guidelines for User Experience Design's Simplest Testing TechniqueFrom EverandThe UX Five-Second Rules: Guidelines for User Experience Design's Simplest Testing TechniqueNo ratings yet
- Introduction To Algorithms For Behavior Based RecommendationDocument36 pagesIntroduction To Algorithms For Behavior Based Recommendationnormal lochuhsinNo ratings yet
- Folding: Why Good Models Sometimes Make Spurious RecommendationsDocument9 pagesFolding: Why Good Models Sometimes Make Spurious Recommendationsnormal lochuhsinNo ratings yet
- Deep Neural Networks For Youtube Recommendations PDFDocument8 pagesDeep Neural Networks For Youtube Recommendations PDFjaewookchungNo ratings yet
- Kernel Matrix Factorization ModelsDocument8 pagesKernel Matrix Factorization Modelsnormal lochuhsinNo ratings yet
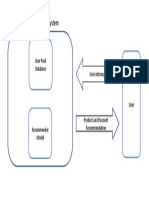
- Recommendation System: User Pixel Database User InformationDocument1 pageRecommendation System: User Pixel Database User Informationnormal lochuhsinNo ratings yet
- Regional Sustainability: Tewodros Abuhay, Endalkachew Teshome, Gashaw MuluDocument12 pagesRegional Sustainability: Tewodros Abuhay, Endalkachew Teshome, Gashaw MuluAbuhay TediNo ratings yet
- Triumph Spitfire MK4 - 1500Document108 pagesTriumph Spitfire MK4 - 1500Ricardo100% (1)
- Template For Preparing TANSCST ProposalDocument6 pagesTemplate For Preparing TANSCST ProposalAntony88% (8)
- LSRetailDataDirector UserGuideDocument89 pagesLSRetailDataDirector UserGuideRock Lee60% (5)
- Automatic Transfer Switch (ATS) : I. History and BackgroundDocument3 pagesAutomatic Transfer Switch (ATS) : I. History and BackgroundJon Lorde BolivarNo ratings yet
- Understanding The American Education SystemDocument6 pagesUnderstanding The American Education SystemCastor JavierNo ratings yet
- Normalization Castuera BSCS2CDocument8 pagesNormalization Castuera BSCS2CRichard, Jr. CastueraNo ratings yet
- World of Steel® - Material Grade PDFDocument35 pagesWorld of Steel® - Material Grade PDFNugraha BintangNo ratings yet
- IBM OpenPages Admin Guide 7.0 PDFDocument822 pagesIBM OpenPages Admin Guide 7.0 PDFMba NaniNo ratings yet
- Seed FilesDocument1 pageSeed Filesارسلان علیNo ratings yet
- Supreme Court upholds return of unrepaired truckDocument35 pagesSupreme Court upholds return of unrepaired truckJeffreyReyesNo ratings yet
- Younis 2020Document5 pagesYounis 2020nalakathshamil8No ratings yet
- Differendial Pressure Flow MetersDocument1 pageDifferendial Pressure Flow Metersborn2engineerNo ratings yet
- Kalokal Barangay Highway HillsDocument35 pagesKalokal Barangay Highway HillsDixie MirandaNo ratings yet
- Apollo Experience Report Lunar Module Landing Gear SubsystemDocument60 pagesApollo Experience Report Lunar Module Landing Gear SubsystemBob Andrepont100% (3)
- Basf TapesDocument3 pagesBasf TapesZoran TevdovskiNo ratings yet
- Agfa CR 10 X User ManualDocument4 pagesAgfa CR 10 X User ManualpietrokoNo ratings yet
- Learn Mobile Packet Core in 5 Hrs - Course Bundle - Mobile Packet CoreDocument10 pagesLearn Mobile Packet Core in 5 Hrs - Course Bundle - Mobile Packet Coremohsen j.No ratings yet
- Crestron Teams HardeningDocument20 pagesCrestron Teams HardeningmanishNo ratings yet
- Genetic Modified FoodDocument16 pagesGenetic Modified FoodKishoNo ratings yet
- Due Diligence InvestmentsDocument6 pagesDue Diligence InvestmentselinzolaNo ratings yet
- How Nokia Failed to Adapt to Market ChangesDocument5 pagesHow Nokia Failed to Adapt to Market ChangesRiangelli ExcondeNo ratings yet
- Cem-FIL GRC Technical DataDocument91 pagesCem-FIL GRC Technical Datacbler100% (1)
- PKG Materials Standards IIP A A JoshiDocument45 pagesPKG Materials Standards IIP A A JoshiDeepak VermaNo ratings yet
- Houghton Mifflin Harcourt Sap Document of UnderstandingDocument10 pagesHoughton Mifflin Harcourt Sap Document of UnderstandingSunil KumarNo ratings yet
- Mode D'emploi 2-43 Operating Instructions 44-85 Manual de Instrucciones 86-127Document43 pagesMode D'emploi 2-43 Operating Instructions 44-85 Manual de Instrucciones 86-127Oleksii_ServiceNo ratings yet
- ACFCS Certification BrochureDocument7 pagesACFCS Certification Brochurebeena pandeyNo ratings yet
- Data Protection Act (DPA)Document14 pagesData Protection Act (DPA)Crypto SavageNo ratings yet
- Wa0031 PDFDocument1 pageWa0031 PDFAnaNo ratings yet
- Upliftment of Recto AveDocument6 pagesUpliftment of Recto AveFrance CortezanoNo ratings yet