You might also like
- Independent Component Analysis: Derek BeatonDocument28 pagesIndependent Component Analysis: Derek BeatonGabriel HumpireNo ratings yet
- R O M H A H A: Educed Rder Odeling Ybrid Pproach Ybrid PproachDocument30 pagesR O M H A H A: Educed Rder Odeling Ybrid Pproach Ybrid PproachLei TuNo ratings yet
- CS5016: Computational Methods and ApplicationsDocument12 pagesCS5016: Computational Methods and ApplicationsBoring PersonNo ratings yet
- Systems Security Lab 2Document34 pagesSystems Security Lab 2asdfqewvgresvgNo ratings yet
- Lect 2 Linear Programming - Graphical MethodDocument22 pagesLect 2 Linear Programming - Graphical MethodAbdulsalam kareemahNo ratings yet
- Duda Solutions PDFDocument77 pagesDuda Solutions PDFR Gowri PrasadNo ratings yet
- Probabilistic Classification ModelsDocument10 pagesProbabilistic Classification ModelsSuchan KhankluayNo ratings yet
- Curs 1 SSL - IntroductionDocument57 pagesCurs 1 SSL - IntroductionMihai IlieNo ratings yet
- ArticleDocument8 pagesArticlejoshjconkinNo ratings yet
- A Robust Real Time Face DetectionDocument55 pagesA Robust Real Time Face DetectionGaurav Veer SinghNo ratings yet
- Lecture Revealed Preference ADocument18 pagesLecture Revealed Preference AAntonio CamposNo ratings yet
- AStudyof Mathematical Modelfor Collaborative FilteringDocument10 pagesAStudyof Mathematical Modelfor Collaborative FilteringCarmelita EsclandaNo ratings yet
- Machine Learning CDocument24 pagesMachine Learning Cskathpalia806No ratings yet
- Estimation Methods of The Parameters in Fuzzy Pareto DistributionDocument9 pagesEstimation Methods of The Parameters in Fuzzy Pareto DistributionIJRASETPublicationsNo ratings yet
- MB0048 or Solved Winter Drive Assignment 2012Document9 pagesMB0048 or Solved Winter Drive Assignment 2012Pawan KumarNo ratings yet
- Artificiality and Mental EconomicsDocument33 pagesArtificiality and Mental Economicsmicamo4711No ratings yet
- Numerical Analysis and ComputingDocument44 pagesNumerical Analysis and ComputingHéctor F BonillaNo ratings yet
- Master OF Business Administration: Second SemesterDocument9 pagesMaster OF Business Administration: Second SemesterHarman ChanderNo ratings yet
- Applied Eco No MetricsDocument75 pagesApplied Eco No MetricsPeach PeaceNo ratings yet
- Batch 5Document26 pagesBatch 5Doctor StrangerNo ratings yet
- MI-364 Mechanics of Materials Spring 13-14 Tutorial 1 Mathematical Preliminaries and Index NotationDocument1 pageMI-364 Mechanics of Materials Spring 13-14 Tutorial 1 Mathematical Preliminaries and Index NotationAmith AaronNo ratings yet
- Linear Prediction of Speech: The Technique and Its ApplicationDocument22 pagesLinear Prediction of Speech: The Technique and Its ApplicationAlex Krockas Botamas ChonnaNo ratings yet
- REPRESENTACIÓN DEL CONOCIMIENTO CON REDES BAYESIANASDocument44 pagesREPRESENTACIÓN DEL CONOCIMIENTO CON REDES BAYESIANASjefersson padillaNo ratings yet
- MainDocument183 pagesMainfrnnasdasdNo ratings yet
- Revealed PreferenceDocument17 pagesRevealed PreferenceSatyabrota DasNo ratings yet
- Empirical Analysis of Detection Cascades of Boosted Classifiers For Rapid Object DetectionDocument8 pagesEmpirical Analysis of Detection Cascades of Boosted Classifiers For Rapid Object DetectionMamik CiamikNo ratings yet
- Python Machine LearningDocument70 pagesPython Machine LearningKai RU100% (1)
- Elg 3126Document6 pagesElg 3126Serigne Saliou Mbacke SourangNo ratings yet
- Bayesian Classifier Implementation Using MATLABDocument21 pagesBayesian Classifier Implementation Using MATLABShabeeb Ali OruvangaraNo ratings yet
- 2-Inductive LearningDocument37 pages2-Inductive LearningKarishma JaniNo ratings yet
- Time Series Analysis: Group Project: 1 Computer ExercisesDocument2 pagesTime Series Analysis: Group Project: 1 Computer ExercisesShwetank PandeyNo ratings yet
- SGN-2556 Pattern Recognition Computer Exercise 1 Bayes ClassifierDocument2 pagesSGN-2556 Pattern Recognition Computer Exercise 1 Bayes ClassifieramitcrathodNo ratings yet
- ACT6100 A2020 Sup 12Document37 pagesACT6100 A2020 Sup 12lebesguesNo ratings yet
- Lecture - Line Scan ConversionDocument46 pagesLecture - Line Scan Conversionsumayya shaikNo ratings yet
- Fairness Lectures-21Document63 pagesFairness Lectures-21Reda JalalNo ratings yet
- Mslab All 2376Document32 pagesMslab All 2376Anubhav KhuranaNo ratings yet
- Package Ica': R Topics DocumentedDocument15 pagesPackage Ica': R Topics DocumentedJulian GonzalezNo ratings yet
- Geometric AlgorithmsDocument37 pagesGeometric AlgorithmsAsafAhmadNo ratings yet
- Fitting Statistical Models With PROC MCMC: Conference PaperDocument27 pagesFitting Statistical Models With PROC MCMC: Conference PaperDimitriosNo ratings yet
- AprioriDocument28 pagesAprioriEdenNo ratings yet
- ML - Co4 EnotesDocument18 pagesML - Co4 EnotesjoxekojNo ratings yet
- Tema5 Teoria-2830Document57 pagesTema5 Teoria-2830Luis Alejandro Sanchez SanchezNo ratings yet
- Some Applications of Bayesian NetworksDocument27 pagesSome Applications of Bayesian NetworksptkngoanNo ratings yet
- BeielsteinPV04a APPL NUM ANAL COMP MATH 1 pp413-433 2004Document21 pagesBeielsteinPV04a APPL NUM ANAL COMP MATH 1 pp413-433 2004Joezerk CarpioNo ratings yet
- MAT-45806/7 Mathematics for PositioningDocument63 pagesMAT-45806/7 Mathematics for PositioningPedro Luis CarroNo ratings yet
- Lecture 1Document30 pagesLecture 1adrienleeNo ratings yet
- Notes MSMDocument66 pagesNotes MSMbhattaramrevanthNo ratings yet
- Chapter 1. Introduction: (Huan - Nguyen@inha - Ac.kr)Document24 pagesChapter 1. Introduction: (Huan - Nguyen@inha - Ac.kr)Nguyễn Công HuấnNo ratings yet
- Daa U-2Document13 pagesDaa U-2bipasanaik282No ratings yet
- An Intuitionistic Fuzzy Multi-Objective Vendor Selection ProblemDocument10 pagesAn Intuitionistic Fuzzy Multi-Objective Vendor Selection ProblemPrabjot Kaur BajajNo ratings yet
- Cpp SarthakDocument52 pagesCpp Sarthakaryannagdev8No ratings yet
- Jinnah University For Women Department of Computer Science & Software EngineeringDocument5 pagesJinnah University For Women Department of Computer Science & Software Engineeringumama amjadNo ratings yet
- Chapter 3 Modeling of Physical SystemsDocument29 pagesChapter 3 Modeling of Physical Systemssaleh1978No ratings yet
- Microeconomics I: Demand Theory, Utility Functions and Choice TheoryDocument36 pagesMicroeconomics I: Demand Theory, Utility Functions and Choice TheoryAriel MorgensternNo ratings yet
- Fourth Sem IT Dept PDFDocument337 pagesFourth Sem IT Dept PDFSangeeta PalNo ratings yet
- Cheat SheetDocument1 pageCheat SheetlucasNo ratings yet
- Statistical Inference in Financial and Insurance Mathematics with RFrom EverandStatistical Inference in Financial and Insurance Mathematics with RNo ratings yet
- Collaborative Recommender Systems Optimize Online Shop SalesDocument13 pagesCollaborative Recommender Systems Optimize Online Shop Salesnormal lochuhsinNo ratings yet
- Folding: Why Good Models Sometimes Make Spurious RecommendationsDocument9 pagesFolding: Why Good Models Sometimes Make Spurious Recommendationsnormal lochuhsinNo ratings yet
- Deep Neural Networks For Youtube Recommendations PDFDocument8 pagesDeep Neural Networks For Youtube Recommendations PDFjaewookchungNo ratings yet
- Kernel Matrix Factorization ModelsDocument8 pagesKernel Matrix Factorization Modelsnormal lochuhsinNo ratings yet
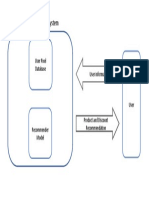
- Recommendation System: User Pixel Database User InformationDocument1 pageRecommendation System: User Pixel Database User Informationnormal lochuhsinNo ratings yet
- UGC List of Journals 20200715Document70 pagesUGC List of Journals 20200715chakradhar JadhavNo ratings yet
- Re-Visits The Grand Theory of Geoffrey Leech: Seven Types of MeaningDocument7 pagesRe-Visits The Grand Theory of Geoffrey Leech: Seven Types of MeaningENG331C F21No ratings yet
- UG Placement Year 2021-2022 List of Students Selected: K. J. Somaiya College of Engineering, Mumbai-77Document7 pagesUG Placement Year 2021-2022 List of Students Selected: K. J. Somaiya College of Engineering, Mumbai-77KhubNo ratings yet
- Rubric A3-HSNS362Document3 pagesRubric A3-HSNS362mandyNo ratings yet
- Machine Learning Notes From AWSDocument5 pagesMachine Learning Notes From AWSTanvi BhanushaliNo ratings yet
- Writing Report Guidelines (39Document5 pagesWriting Report Guidelines (39Rhea Tecson-Saldivar CastilloNo ratings yet
- Community Health Nursing Concepts and TheoriesDocument11 pagesCommunity Health Nursing Concepts and TheoriesKrame G.No ratings yet
- A Study On Job Analysis and It's Effect On Organizational PerformanceDocument72 pagesA Study On Job Analysis and It's Effect On Organizational PerformancePranjal PatilNo ratings yet
- Analyzing The Meaning of The Data and Drawing Conclusions: Prepared By: Rica Eloisa C. LopezDocument25 pagesAnalyzing The Meaning of The Data and Drawing Conclusions: Prepared By: Rica Eloisa C. LopezMarkaton Dihagnos50% (2)
- Role of Political Institutions in Social ChangeDocument3 pagesRole of Political Institutions in Social ChangeSyed Mohsin Mehdi TaqviNo ratings yet
- Robots: Friend or Foe?: Take Off SupersededDocument1 pageRobots: Friend or Foe?: Take Off SupersededKaren Banderas ManzanoNo ratings yet
- Reference - PidcockArticle - InfoGridDocument2 pagesReference - PidcockArticle - InfoGridIhar KuznecovNo ratings yet
- Ib Baccalaureate Germany RecognitionDocument20 pagesIb Baccalaureate Germany Recognitionhalasol2009No ratings yet
- Test Bank For Marriages Families and Relationships Making Choices in A Diverse Society 12th Edition Mary Ann Lamanna Agnes Riedmann Susan D Stewart Isbn 10 1285736974 Isbn 13 9781285736976Document38 pagesTest Bank For Marriages Families and Relationships Making Choices in A Diverse Society 12th Edition Mary Ann Lamanna Agnes Riedmann Susan D Stewart Isbn 10 1285736974 Isbn 13 9781285736976Marlyn Islam100% (34)
- Data Analytics, Data Visualization and Big DataDocument25 pagesData Analytics, Data Visualization and Big DataRajiv RanjanNo ratings yet
- Introduction to Sociology - Culture and Dominant IdeologyDocument9 pagesIntroduction to Sociology - Culture and Dominant IdeologyAli hasanNo ratings yet
- Activity 2: "Mirror, Mirror On The Wall"Document4 pagesActivity 2: "Mirror, Mirror On The Wall"slow dancerNo ratings yet
- Demography and Health Services StatisticsDocument74 pagesDemography and Health Services StatisticsHamse AdenNo ratings yet
- Midterm Week 4 Lesson Addie ModelDocument6 pagesMidterm Week 4 Lesson Addie ModelCecelien Salgado AntonioNo ratings yet
- 6.session PlanDocument7 pages6.session PlanMerly SalvadorNo ratings yet
- ResearchDocument48 pagesResearchCai De JesusNo ratings yet
- Key Players in Learning PartnershipsDocument40 pagesKey Players in Learning PartnershipsEljun delos ReyesNo ratings yet
- Inteligencia Artifical en La Educación Superior de La IndiaDocument17 pagesInteligencia Artifical en La Educación Superior de La IndiaMaría Jose TorresNo ratings yet
- Small Stories of The Greek Crisis On Facebook: Mariza GeorgalouDocument15 pagesSmall Stories of The Greek Crisis On Facebook: Mariza GeorgalouFélix Alexander Ceballos CifuentesNo ratings yet
- Sociology: Final State Exam - Examples of Questions From The Previous YearsDocument3 pagesSociology: Final State Exam - Examples of Questions From The Previous YearsTupac MuzamweseNo ratings yet
- Introduction Report JournalDocument3 pagesIntroduction Report JournalAakash SharmaNo ratings yet
- Bernard - Analyzing Qualitative Data - CAP5Document25 pagesBernard - Analyzing Qualitative Data - CAP5Jhonny B MezaNo ratings yet
- Implementing ERM Strategies in Higher EducationDocument12 pagesImplementing ERM Strategies in Higher EducationAnuja ShuklaNo ratings yet
- Education 2788023Document26 pagesEducation 2788023RasdianaNo ratings yet
- Research ProposalDocument17 pagesResearch Proposalaprile pachecoNo ratings yet