You might also like
- Purdue Basics SIGNALS AND SYSTEMSDocument4 pagesPurdue Basics SIGNALS AND SYSTEMSmdasifhassanapspdclNo ratings yet
- Solution Manual For: Numerical Computing With MATLAB by Cleve B. MolerDocument9 pagesSolution Manual For: Numerical Computing With MATLAB by Cleve B. MolerDavid ChenNo ratings yet
- Unit IV Applications of Laplace Transform PDFDocument43 pagesUnit IV Applications of Laplace Transform PDFSanjay KumarNo ratings yet
- SOLVE ODE BY USING LAPLACE July 2020Document6 pagesSOLVE ODE BY USING LAPLACE July 2020CT MarNo ratings yet
- Boyce ODEch 6 S 4 P 04Document3 pagesBoyce ODEch 6 S 4 P 04Feby ArdhaniNo ratings yet
- Boyce ODEch 6 S 5 P 02Document2 pagesBoyce ODEch 6 S 5 P 02Feby ArdhaniNo ratings yet
- Solution Assignment 2Document7 pagesSolution Assignment 2sushant sharmaNo ratings yet
- 222 ED3BM1.pe21073514.Actividades EDB Dep2 TL 2022 2Document4 pages222 ED3BM1.pe21073514.Actividades EDB Dep2 TL 2022 2Flor Alejandra Piña RodriguezNo ratings yet
- Mert Ozbayram Math219 Assignment Week10 Due 08/22/2016 at 11:59pm EESTDocument1 pageMert Ozbayram Math219 Assignment Week10 Due 08/22/2016 at 11:59pm EESTOrkun AkyolNo ratings yet
- Week 12 SolutionsDocument3 pagesWeek 12 SolutionsjohnpaulshobayanNo ratings yet
- MATH2352 Differential Equations and Applications Name: Coursework 5 ID: Problem 1. Find The Laplace Transform of The Function F (T) 0 T 2 (T 2) T 2Document2 pagesMATH2352 Differential Equations and Applications Name: Coursework 5 ID: Problem 1. Find The Laplace Transform of The Function F (T) 0 T 2 (T 2) T 2John ChanNo ratings yet
- HW1 SolutionsDocument3 pagesHW1 SolutionsMuhammad AbubakerNo ratings yet
- Major Marking SchemeDocument13 pagesMajor Marking Schemejainnupur321No ratings yet
- Module3-Tutorial Sheet-DET-BMAT102LDocument3 pagesModule3-Tutorial Sheet-DET-BMAT102LashishtiwarypcNo ratings yet
- f21 241 Final SolutionDocument2 pagesf21 241 Final Solutionbarre PenroseNo ratings yet
- ECE311S: Dynamic Systems and Control Problem Set 2Document3 pagesECE311S: Dynamic Systems and Control Problem Set 2zoeeeNo ratings yet
- 141021transformation of Initial Value ProblemDocument5 pages141021transformation of Initial Value Problemaye pyoneNo ratings yet
- Boyce ODEch 6 S 2 P 17Document2 pagesBoyce ODEch 6 S 2 P 17Lucas DanielNo ratings yet
- Applications of Laplace TransformsDocument11 pagesApplications of Laplace Transformswealthyjaneabletes12No ratings yet
- Math 201 Lecture 18: Convolution: Refers To The Problem Number Refers To The Problem Number in The 8th EditionDocument9 pagesMath 201 Lecture 18: Convolution: Refers To The Problem Number Refers To The Problem Number in The 8th EditionElena IulyNo ratings yet
- Laplace TransformDocument8 pagesLaplace TransformSumangil, Maria Margarita P.No ratings yet
- Notes LT3Document16 pagesNotes LT3osmanfıratNo ratings yet
- Initial Value Problems and The Laplace TransformDocument7 pagesInitial Value Problems and The Laplace TransformKeith GarridoNo ratings yet
- GOOD - Initial Value Problems and The LaplaceDocument7 pagesGOOD - Initial Value Problems and The LaplaceBelay AyalewNo ratings yet
- Module 4A Inverse Laplace Transform PDFDocument5 pagesModule 4A Inverse Laplace Transform PDFPaolo Angelo GutierrezNo ratings yet
- 1 Problems Laplace Transform: Problem 1Document6 pages1 Problems Laplace Transform: Problem 1KarNo ratings yet
- Math 202 PS-10Document12 pagesMath 202 PS-10asdasdasdNo ratings yet
- Solution A2 NPTEL Control Engg Jan April 2020Document6 pagesSolution A2 NPTEL Control Engg Jan April 2020Akhil NameirakpamNo ratings yet
- 6.4 Differential Equations With Discontinuous Forcing FunctionsDocument8 pages6.4 Differential Equations With Discontinuous Forcing FunctionsJuan Sebastian Ramirez AyalaNo ratings yet
- Mathematical Models of Physical SystemsDocument44 pagesMathematical Models of Physical Systemspersian_prideNo ratings yet
- Math 201 Lecture 12: Cauchy-Euler EquationsDocument8 pagesMath 201 Lecture 12: Cauchy-Euler EquationsPlease ScribdNo ratings yet
- SU3 Worksheet3Document3 pagesSU3 Worksheet3Muavha MadembeNo ratings yet
- BDA14103 Engineering Mathematics 2-Tutorial 4Document2 pagesBDA14103 Engineering Mathematics 2-Tutorial 4KhaiNo ratings yet
- Math 2280 - Practice Exam 4Document7 pagesMath 2280 - Practice Exam 4Helbert PaatNo ratings yet
- The Laplace TransformDocument22 pagesThe Laplace Transformindrayadi2009No ratings yet
- Control ECM2105: Laplace Transform Examples: L (Sinh (At) ) A S A L (Cosh (At) ) - Hint: What IsDocument1 pageControl ECM2105: Laplace Transform Examples: L (Sinh (At) ) A S A L (Cosh (At) ) - Hint: What IsEduardo FerreiraNo ratings yet
- Tutorial Sheet 3Document2 pagesTutorial Sheet 3yash sononeNo ratings yet
- Mert Ozbayram Math219 Assignment Week11 Due 08/23/2016 at 11:59pm EESTDocument2 pagesMert Ozbayram Math219 Assignment Week11 Due 08/23/2016 at 11:59pm EESTOrkun AkyolNo ratings yet
- Math 2280 - Final Exam: University of Utah Fall 2013Document20 pagesMath 2280 - Final Exam: University of Utah Fall 2013Abdesselem BoulkrouneNo ratings yet
- Transfer Function ProsesDocument34 pagesTransfer Function ProsesMalasari NasutionNo ratings yet
- Assignment 4Document3 pagesAssignment 4Kriti GargNo ratings yet
- Test 2Document3 pagesTest 2howard-chan-3022No ratings yet
- Sample Solution 1Document10 pagesSample Solution 1박정현No ratings yet
- 141021transformation of Initial Value ProblemDocument5 pages141021transformation of Initial Value Problemaye pyoneNo ratings yet
- 6.2/6.3 Laplace Transform, Derivatives, Integrals, ODE: Yurii Lyubarskii, NTNUDocument14 pages6.2/6.3 Laplace Transform, Derivatives, Integrals, ODE: Yurii Lyubarskii, NTNUlardhanNo ratings yet
- 1111EM1HW4QDocument4 pages1111EM1HW4QJASON2 CHIBNo ratings yet
- Laplace of Derivatives (DEs)Document6 pagesLaplace of Derivatives (DEs)gnhlanhla98No ratings yet
- Chapter 2 ReviewDocument10 pagesChapter 2 ReviewkareeraisuNo ratings yet
- Module 4 - Solution of Initial Value Problem by Laplace TransformDocument7 pagesModule 4 - Solution of Initial Value Problem by Laplace TransformParth VijayNo ratings yet
- Maths Project WomenDocument10 pagesMaths Project WomenindramuniNo ratings yet
- Dirac Delta FuctionsDocument4 pagesDirac Delta FuctionsorimathsNo ratings yet
- Second Order Differential Part 7Document8 pagesSecond Order Differential Part 7nazirulaliNo ratings yet
- Assignment # 2 (Solution) Exercise 4.4: F T F T FDocument4 pagesAssignment # 2 (Solution) Exercise 4.4: F T F T FGeorge KNo ratings yet
- Final Exam 2010Document15 pagesFinal Exam 2010Rafi Mahmoud SulaimanNo ratings yet
- f (t) = sen (t) t ≤ π f (t) =sen (t) −sen (t) U (t−π) L f (t) s e L sen (t+π) L f (t) s e L sen (t) e s F (s) = sDocument3 pagesf (t) = sen (t) t ≤ π f (t) =sen (t) −sen (t) U (t−π) L f (t) s e L sen (t+π) L f (t) s e L sen (t) e s F (s) = sDiose PaolaNo ratings yet
- Differential EquationsDocument10 pagesDifferential EquationsPatricia PazNo ratings yet
- M 307 Laplace Fact SheetDocument3 pagesM 307 Laplace Fact Sheetstephannie montoyaNo ratings yet
- Señal TransitorioDocument6 pagesSeñal TransitorioSalvador Chairez GarciaNo ratings yet
- Math 2280 - Assignment 10: Dylan Zwick Spring 2014Document19 pagesMath 2280 - Assignment 10: Dylan Zwick Spring 2014Bree ElaineNo ratings yet
- Tables of Generalized Airy Functions for the Asymptotic Solution of the Differential Equation: Mathematical Tables SeriesFrom EverandTables of Generalized Airy Functions for the Asymptotic Solution of the Differential Equation: Mathematical Tables SeriesNo ratings yet
- Solution of ECE 315 Test 2 F06: A 7 and B 3Document9 pagesSolution of ECE 315 Test 2 F06: A 7 and B 3Ajeet KumarNo ratings yet
- 1 Homework #2Document24 pages1 Homework #2Ajeet KumarNo ratings yet
- Worksheet 88 1Document101 pagesWorksheet 88 1Ajeet KumarNo ratings yet
- Maths Question Paper - QuestionDocument12 pagesMaths Question Paper - QuestionAjeet KumarNo ratings yet
- Proposed Building ON PLOT NO.-D-166, Sec 105 Noida: SectionDocument1 pageProposed Building ON PLOT NO.-D-166, Sec 105 Noida: SectionAjeet KumarNo ratings yet
- Reasoning and Aptitude: Time: 1Hr MM: 100 Marking Scheme: (+4 For Correct and - 1 Incorrect) Qualifying Marks: 60%Document7 pagesReasoning and Aptitude: Time: 1Hr MM: 100 Marking Scheme: (+4 For Correct and - 1 Incorrect) Qualifying Marks: 60%Ajeet KumarNo ratings yet
- Verify The Receipt by Clicking Status Verify Receipt On Vahan Online Services Portal atDocument1 pageVerify The Receipt by Clicking Status Verify Receipt On Vahan Online Services Portal atAjeet KumarNo ratings yet
- Brainly - NDA (SMEs) - 2021Document6 pagesBrainly - NDA (SMEs) - 2021Ajeet KumarNo ratings yet
- Health Wallet BrochureDocument8 pagesHealth Wallet BrochureAjeet KumarNo ratings yet
- LeastsqDocument54 pagesLeastsqAjeet KumarNo ratings yet
- LeastsqDocument54 pagesLeastsqAjeet KumarNo ratings yet
- Latihan Uas-1Document3 pagesLatihan Uas-1Ajeet KumarNo ratings yet
- NotesDocument20 pagesNotesGuillano DorasamyNo ratings yet
- Shear Stress in BeamsDocument8 pagesShear Stress in BeamsNaveen UndrallaNo ratings yet
- Ch3 Munson BDocument31 pagesCh3 Munson BMaryam ArifNo ratings yet
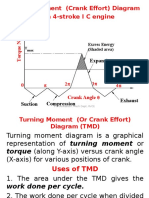
- Turning Moment Diagram & FlywheelDocument88 pagesTurning Moment Diagram & FlywheelAshishAgarwal100% (1)
- Basic Concepts of ProbabilityDocument36 pagesBasic Concepts of ProbabilityChiragNo ratings yet
- Foundations For Industrial Machines: Handbook For Practising EngineersDocument1 pageFoundations For Industrial Machines: Handbook For Practising EngineerssrieeNo ratings yet
- FINE - Neutral RelationsDocument34 pagesFINE - Neutral Relationsgia.daniNo ratings yet
- Combinatorial Identities Project Vol. 2Document17 pagesCombinatorial Identities Project Vol. 2Sam KarasNo ratings yet
- Integral Geometry & Geometric Probability: Andrejs TreibergsDocument64 pagesIntegral Geometry & Geometric Probability: Andrejs Treibergskaveh_cNo ratings yet
- Sciencedirect: Impact of Sub Seismic Heterogeneity On Co InjectivityDocument11 pagesSciencedirect: Impact of Sub Seismic Heterogeneity On Co InjectivityMaylin GarciaNo ratings yet
- Midterm Exam in GEC 4 BSCSDocument4 pagesMidterm Exam in GEC 4 BSCSRex GamingNo ratings yet
- Ada NotesDocument16 pagesAda NotesRenukaNo ratings yet
- HMELEC2 Week 1-4Document14 pagesHMELEC2 Week 1-4Rachel Ann IntiaNo ratings yet
- 10 Math 3rdgrading Divide Numbers FoundDocument27 pages10 Math 3rdgrading Divide Numbers FoundArgine CastilloNo ratings yet
- Mathematics Without Borders Age Group 7 SPRING 2019: PermissionDocument3 pagesMathematics Without Borders Age Group 7 SPRING 2019: PermissionElevenPlus ParentsNo ratings yet
- New Exact Solutions For Inflationary Cosmological PerturbationsDocument13 pagesNew Exact Solutions For Inflationary Cosmological PerturbationsBergas FrenliNo ratings yet
- Chapter 1 - Introduction To Machinery PrinciplesDocument27 pagesChapter 1 - Introduction To Machinery PrinciplesYousab CreatorNo ratings yet
- (Category Theory Homological Al) Marco Grandis - Category Theory and Applications - A Textbook For Beginners-World Scientific Pub Co Inc (2018)Document304 pages(Category Theory Homological Al) Marco Grandis - Category Theory and Applications - A Textbook For Beginners-World Scientific Pub Co Inc (2018)johnnicholasrosettiNo ratings yet
- AQA Maths For A-Level Science TestDocument5 pagesAQA Maths For A-Level Science TestHena AfridiNo ratings yet
- CSC 35Document4 pagesCSC 35Nguyen NguyenNo ratings yet
- Observer Based Adaptive Neural Network Backstepping Sliding Mode Control For Switched Fractional Order Uncertain Nonlinear Systems With Unmeasured StatesDocument14 pagesObserver Based Adaptive Neural Network Backstepping Sliding Mode Control For Switched Fractional Order Uncertain Nonlinear Systems With Unmeasured StatesGzam RaïfaNo ratings yet
- Acceleration: Velocity VectorDocument16 pagesAcceleration: Velocity Vectorblowmeasshole1911No ratings yet
- PR2 - SLHT 1 - January 4 To 8Document5 pagesPR2 - SLHT 1 - January 4 To 8JESSA SUMAYANGNo ratings yet
- Bowling Ball Laboratory: PSI Physics - KinematicsDocument4 pagesBowling Ball Laboratory: PSI Physics - KinematicsBrandonNo ratings yet
- 3.IV. MatrixOperationsDocument26 pages3.IV. MatrixOperationsDaniel KozakevichNo ratings yet
- Jan 2019 CSEC Maths P2 SolutionsDocument21 pagesJan 2019 CSEC Maths P2 SolutionsKimone HallNo ratings yet
- Conversion of MeasurementsDocument8 pagesConversion of MeasurementsRICHELLE L. HERNANDEZNo ratings yet
- Permutation CombinationDocument8 pagesPermutation CombinationReina Alliyah GonzalesNo ratings yet
- Case: When Order Size Q and Amount of The Shortage S Are The Decision VariableDocument5 pagesCase: When Order Size Q and Amount of The Shortage S Are The Decision VariableRisshi AgrawalNo ratings yet
- U-1 L-7 Eccentic Connections - Bracket Connections1Document46 pagesU-1 L-7 Eccentic Connections - Bracket Connections1Nishanth NishiNo ratings yet