You might also like
- Detecting Faces in Images Survey Methods Metrics BenchmarksDocument25 pagesDetecting Faces in Images Survey Methods Metrics Benchmarksالدنيا لحظهNo ratings yet
- Face Recognition Techniques and Its ApplicationDocument3 pagesFace Recognition Techniques and Its ApplicationInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Face Tracking and Robot Shoot: International Journal of Application or Innovation in Engineering & Management (IJAIEM)Document9 pagesFace Tracking and Robot Shoot: International Journal of Application or Innovation in Engineering & Management (IJAIEM)International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- A Survey On Face Recognition TechniquesDocument5 pagesA Survey On Face Recognition TechniquesIJSTENo ratings yet
- Eigenfaces For Face Recognition: ECE 533 Final Project Report, Fall 03Document20 pagesEigenfaces For Face Recognition: ECE 533 Final Project Report, Fall 03Youssef KamounNo ratings yet
- Redundancy in Face Image RecognitionDocument4 pagesRedundancy in Face Image RecognitionIJAERS JOURNALNo ratings yet
- Face Tracking and Robot Shoot Using Adaboost MethodDocument7 pagesFace Tracking and Robot Shoot Using Adaboost MethodInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Matlab Face Recognition using PCADocument45 pagesMatlab Face Recognition using PCASuresh MgNo ratings yet
- Face Detection and Recognition - A ReviewDocument8 pagesFace Detection and Recognition - A ReviewHenry MagdayNo ratings yet
- Face Recognition Literature ReviewDocument7 pagesFace Recognition Literature Reviewaflsqrbnq100% (1)
- Face Recognition Using Neural Network and Eigenvalues With Distinct Block ProcessingDocument12 pagesFace Recognition Using Neural Network and Eigenvalues With Distinct Block Processingsurendiran123No ratings yet
- Introduction To Innovative Projects Face Recognition (Opencv)Document20 pagesIntroduction To Innovative Projects Face Recognition (Opencv)karthik vajjaNo ratings yet
- A Survey On Face Recognition TechniquesDocument7 pagesA Survey On Face Recognition TechniquesAlexander DeckerNo ratings yet
- Face Detection and Its Applications: ISSN: 2320 - 8791Document10 pagesFace Detection and Its Applications: ISSN: 2320 - 8791anon_303010132No ratings yet
- B2Document44 pagesB2orsangobirukNo ratings yet
- Face DetectionDocument21 pagesFace Detectionعلم الدين خالد مجيد علوانNo ratings yet
- Assisting Blind Using Facial Recognition and Voice AssistanceDocument5 pagesAssisting Blind Using Facial Recognition and Voice AssistanceEditor IJRITCCNo ratings yet
- Detecting Faces in Images: A SurveyDocument25 pagesDetecting Faces in Images: A SurveySetyo Nugroho100% (17)
- 1.1. Overview: Department of Computer Science & Engineering, VITS, Satna (M.P.) IndiaDocument36 pages1.1. Overview: Department of Computer Science & Engineering, VITS, Satna (M.P.) IndiamanuNo ratings yet
- A Survey of Feature Base Methods For Human Face Detection: Hiyam Hatem, Zou Beiji and Raed MajeedDocument18 pagesA Survey of Feature Base Methods For Human Face Detection: Hiyam Hatem, Zou Beiji and Raed MajeedRolandoRamosConNo ratings yet
- Forensic Face Recognition SurveyDocument19 pagesForensic Face Recognition SurveyDon BarloneNo ratings yet
- F F R: A S: Orensic ACE Ecognition UrveyDocument19 pagesF F R: A S: Orensic ACE Ecognition UrveyDon BarloneNo ratings yet
- Face Recognition Report 1Document26 pagesFace Recognition Report 1Binny DaraNo ratings yet
- Eigedces Recognition: Matthew Alex PentlandDocument69 pagesEigedces Recognition: Matthew Alex PentlandrequestebooksNo ratings yet
- Effect of Distance Measures in Pca Based Face: RecognitionDocument15 pagesEffect of Distance Measures in Pca Based Face: Recognitionadmin2146No ratings yet
- 10 Chapter2Document25 pages10 Chapter2quinnn tuckyNo ratings yet
- Research Paper - Human Face DetectionDocument8 pagesResearch Paper - Human Face DetectionPremchand LukramNo ratings yet
- 2017 - FaceRecognitionPattern&Fabiola Becerra-Riera - , Annette Morales-González - Heydi Méndez-VázquezDocument7 pages2017 - FaceRecognitionPattern&Fabiola Becerra-Riera - , Annette Morales-González - Heydi Méndez-VázquezJuan Felipe Lopez RestrepoNo ratings yet
- Combining Facial Dynamics With Appearance For Age EstimationDocument16 pagesCombining Facial Dynamics With Appearance For Age EstimationArmağan FidanNo ratings yet
- Real Time Face Detection and Tracking Using Opencv: Mamata S.KalasDocument4 pagesReal Time Face Detection and Tracking Using Opencv: Mamata S.KalasClevin CkNo ratings yet
- A Fuzzy Logic Based Human Behavioural Analysis Model Using Facial Feature Extraction With Perceptual ComputingDocument6 pagesA Fuzzy Logic Based Human Behavioural Analysis Model Using Facial Feature Extraction With Perceptual ComputingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Robust Decision Making System Based On Facial Emotional ExpressionsDocument6 pagesRobust Decision Making System Based On Facial Emotional ExpressionsInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Intro Face Detect RecognitionDocument43 pagesIntro Face Detect RecognitionHao YuNo ratings yet
- V3i3 1331Document8 pagesV3i3 1331Ha TranNo ratings yet
- The Use of Neural Networks in Real-Time Face DetectionDocument16 pagesThe Use of Neural Networks in Real-Time Face Detectionkaushik73No ratings yet
- Alamaldin Face DetectionDocument21 pagesAlamaldin Face Detectionعلم الدين خالد مجيد علوانNo ratings yet
- Face Detection and Face RecognitionDocument7 pagesFace Detection and Face RecognitionPranshu AgrawalNo ratings yet
- Emotion Detection From Frontal Facial Image: Thesis ReportDocument28 pagesEmotion Detection From Frontal Facial Image: Thesis ReportsaidaNo ratings yet
- Review of Face Detection Systems Based Artificial Neural Networks AlgorithmsDocument16 pagesReview of Face Detection Systems Based Artificial Neural Networks AlgorithmsIJMAJournalNo ratings yet
- Is There Any Hope For Face Recognition?: Technical University of Catalonia, Barcelona, Spain Luis@gps - Tsc.upc - EsDocument3 pagesIs There Any Hope For Face Recognition?: Technical University of Catalonia, Barcelona, Spain Luis@gps - Tsc.upc - EsMahadevNo ratings yet
- Gender and Age Estimation Based On Facial ImagesDocument5 pagesGender and Age Estimation Based On Facial Imagesshital shermaleNo ratings yet
- Literature Review On Facial RecognitionDocument5 pagesLiterature Review On Facial Recognitionea726gej100% (1)
- Face DetectionDocument49 pagesFace DetectionMohammed RaihanNo ratings yet
- Review of Face Detection System Using Neural NetworkDocument5 pagesReview of Face Detection System Using Neural NetworkVIVA-TECH IJRINo ratings yet
- Intro Face Detect RecognitionDocument43 pagesIntro Face Detect RecognitionSudipta BhadraNo ratings yet
- Thesis On Face Recognition PDFDocument8 pagesThesis On Face Recognition PDFScott Bou100% (1)
- Emotion Detection From Frontal Facial Image: Thesis ReportDocument28 pagesEmotion Detection From Frontal Facial Image: Thesis Reportjack frostNo ratings yet
- Literature Review On Face Recognition TechnologyDocument7 pagesLiterature Review On Face Recognition Technologyc5hfb2ct100% (1)
- Enhancing Face Identification Using Local Binary Patterns and K-Nearest NeighborsDocument12 pagesEnhancing Face Identification Using Local Binary Patterns and K-Nearest NeighborsNancyNo ratings yet
- Literature Review Face Recognition SystemDocument6 pagesLiterature Review Face Recognition Systemafdtytird100% (1)
- Literature Review On Face Recognition SystemDocument6 pagesLiterature Review On Face Recognition Systemafdtsdece100% (1)
- Automated Facial Recognition Entry Management System Using Image Processing TechniqueDocument6 pagesAutomated Facial Recognition Entry Management System Using Image Processing TechniqueosinoluwatosinNo ratings yet
- Emotion Sensing Facial Recognition Using Machine LearningDocument7 pagesEmotion Sensing Facial Recognition Using Machine LearningRama DeviNo ratings yet
- 10 Chapter1 PDFDocument5 pages10 Chapter1 PDFTony ChopperNo ratings yet
- Literature Review of Face DetectionDocument5 pagesLiterature Review of Face Detectionc5rfkq8n100% (1)
- A Pyramid Multi-Level Face Descriptor: Application To Kinship VerificationDocument20 pagesA Pyramid Multi-Level Face Descriptor: Application To Kinship VerificationRashad NoureddineNo ratings yet
- Cl311-Face Recognition SystemDocument24 pagesCl311-Face Recognition SystemBhavik2002No ratings yet
- Face Recognition Across Pose A ReviewDocument21 pagesFace Recognition Across Pose A Reviewoumaima arbiNo ratings yet
- Mcqs 1Document12 pagesMcqs 1Ralitsa DeeDee Wilcox100% (1)
- A. Null and Alternate Hypothesis: Post-Assessment-Written OutputsDocument6 pagesA. Null and Alternate Hypothesis: Post-Assessment-Written OutputsAngelika FerrerNo ratings yet
- Statistics LectureDocument35 pagesStatistics LectureEPOY JERSNo ratings yet
- Exact Definition of Mathematics: February 2017Document10 pagesExact Definition of Mathematics: February 2017Loraine TubigNo ratings yet
- JIT For Lean Manufacturing FinalDocument83 pagesJIT For Lean Manufacturing FinalMusical CorruptionNo ratings yet
- SQL Assignments1Document3 pagesSQL Assignments1Manraj Singh33% (3)
- Differential Equation-03-Exercise - 1Document20 pagesDifferential Equation-03-Exercise - 1Raju SinghNo ratings yet
- Equations and Subject of The Formula Worksheet With SolutionsDocument11 pagesEquations and Subject of The Formula Worksheet With SolutionsCamille ComasNo ratings yet
- Chap 15ha OscillationsDocument61 pagesChap 15ha OscillationsXahid HasanNo ratings yet
- MTH3011 Exercise Sheet 03 2015Document3 pagesMTH3011 Exercise Sheet 03 2015jeffNo ratings yet
- OF Laws:: Michael Satosi WatanabeDocument60 pagesOF Laws:: Michael Satosi WatanabecdcrossroaderNo ratings yet
- An Asymmetric TSP With Time WindowsDocument14 pagesAn Asymmetric TSP With Time WindowsMiguel Ángel Jiménez AchinteNo ratings yet
- Geomechanics NotesDocument72 pagesGeomechanics NotesCarlos Plúa GutiérrezNo ratings yet
- Department of Finance and Banking Faculty of Business Studies Begum Rokeya University, Rangpur. Master of Business Administration (MBA) SyllabusDocument18 pagesDepartment of Finance and Banking Faculty of Business Studies Begum Rokeya University, Rangpur. Master of Business Administration (MBA) SyllabusFuturesow support zone BangladeshNo ratings yet
- Programmed InstructionDocument28 pagesProgrammed InstructionPriya Singh100% (2)
- Iep Edu 203Document16 pagesIep Edu 203api-580105196No ratings yet
- 2 Hernandez Et Al 2005 Polychaeta BiogeographyDocument11 pages2 Hernandez Et Al 2005 Polychaeta BiogeographyViskar RyuuNo ratings yet
- SAT Chemistry TextbookDocument112 pagesSAT Chemistry TextbookSai Sagireddy100% (2)
- MSA (Atributos)Document3 pagesMSA (Atributos)José Marcos Vázquez RodríguezNo ratings yet
- Multiple Regression AnalysisDocument41 pagesMultiple Regression AnalysisAmisha PandeyNo ratings yet
- HOKLAS calibration uncertainty policyDocument3 pagesHOKLAS calibration uncertainty policyCarson ChowNo ratings yet
- ME 612 Sheet Metal Bending Theory and Plasticity GuideDocument19 pagesME 612 Sheet Metal Bending Theory and Plasticity GuideAbdullah Al FikriNo ratings yet
- Mathematical Anxiety and Mathematical CompetenceDocument81 pagesMathematical Anxiety and Mathematical CompetenceAsus LaptopNo ratings yet
- API 610 Notes PDFDocument0 pagesAPI 610 Notes PDFkkabbara100% (2)
- Basic Mathematics 2011-QNDocument5 pagesBasic Mathematics 2011-QNEmanuel John BangoNo ratings yet
- Esm410 Assignment 1 Portfolio VersionDocument12 pagesEsm410 Assignment 1 Portfolio Versionapi-282084309No ratings yet
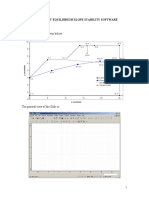
- Slide TutorialDocument28 pagesSlide TutorialAS V KameshNo ratings yet
- Emily Tao Summary of Analysis of Premium Liabilities For Australian Lines of BusinessDocument11 pagesEmily Tao Summary of Analysis of Premium Liabilities For Australian Lines of Businesszafar1976No ratings yet
- Future Worth Analysis + Capitalized CostDocument19 pagesFuture Worth Analysis + Capitalized CostjefftboiNo ratings yet