Professional Documents
Culture Documents
Lenart
Lenart
Uploaded by
arjunOriginal Description:
Copyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
Lenart
Lenart
Uploaded by
arjunCopyright:
Available Formats
A 2048 complex point FFT processor for
acceleration in Digital Holographic Imaging
Thomas Lenart and Viktor Öwall
Digital Holographic Imaging FFT Implementation
In Digital Holographic Imaging, a high throughput FFT is required. 2D FFT transforms
of up to 2048x2048 complex points should be calculated in real-time. There are many
”A key component in a digital holographic imaging system is the holographic video
different ways to implement an FFT processor. The computations can be done in a number
camera. The purpose of the camera is to record the hologram on a solid-state sensor and
of iterations by time multiplexing a single memory and arithmetic unit (a), or by using a
digitally construct the image. The image construction is very computational expensive
pipelined architecture (b).
involving large 2-dimensional FFT calculations. A major task of designing the camera
system will thus be to design the ASIC, which will perform the image reconstruction.” a) do
0
b) FIFO
FIFO FIFO
FIFO FIFO
FIFO FIFO
FIFO
BF
BF
BF
BF
BF
BF
BF
BF
Memory
Memory
di
Hologram
addr
Control
Control &&twiddle
twiddlefactor
factor ROM
ROM Stage 1 Stage 2 Stage 3 Stage 4
Object Algorithm + Compact design + High throughput
+ + Flexible - Large design
- Low throughput
Reference
The achieve a high throughput, a pipelined architecture is selected. The implementation
ASIC is based on the Radix-22 decimation-in-frequency algorithm with a single path delay
Result
feedback.
Data scaling in pipelined architectures Data scaling - Convergent block floating point
The problem with a fixed point FFT is to a) b)
Existing approach:
20 # output bits from the butterfly
Large intermediate buffer
maintain the accuracy and preserve the # exponent bits
The basic idea is that the output from a radix-4 stage is a
dynamic range at the same time. One W(n)
set of 4 independent groups that can use different scale
15
way to achieve a high signal-to-noise factors. This will converge in the pipeline towards one
Trunc
Delay
Trunc
10 10
Delay
ratio is to increase the internal word exponent for each output sample from a pipelined FFT. 4log ( N ) −stage
4
length for every stage in the pipelined 5 5
The problem is the large memory requirements, caused
21 output bits
12 output bits
10 input bits
10 input bits
FFT (variable datapath), i.e. the word
0 0 by the intermediate buffers between the FFT stages, Controller
Controller
length will be wider at the output than at
required for storing one complete group before rescaling
Stage 1
Stage 2
Stage 3
Stage 4
Stage 5
Stage 6
Stage 1
Stage 2
Stage 3
Stage 4
Stage 5
Stage 6
the input (a).
can be performed. Another drawback is increased delay
Another way to improve the signal-to-noise ratio without increasing the internal word in the pipeline.
length is to use data scaling (b). One example of data scaling is block floating point that
decoder
Final decoder
uses exponents, or scaling factors, for internal representation to improve the SNR. The
CBFP
CBFP
CBFP
CBFP
CBFP
CBFP
CBFP
CBFP
CBFP
CBFP
Stage
Stage11 Stage
Stage22 Stage
Stage 33 Stage
Stage 44 Stage
Stage 55 Stage
Stage66
exponents are usually shared between the real and imaginary part of a complex value,
Final
(radix-2)
or even shared among a set of complex values, unlike normal floating point
representation. Delay
Delay Delay
Delay Delay
Delay Delay
Delay
Data scaling - Hybrid floating point Delay feedback implementation
Area comparison
1.8
Presented approach: 1.6
Flip-flops
Dual port memory
a) b) Single port memory
1.4 Double width memory
Stage 1 Stage 2 Stage 3 Stage 4 Stage 5 Stage 6 Single
Singleport
portRAM
RAM 0 31:16 31:16
0
32x16
32x16 1 1.2
Single
Singleport
portRAM
Size in mm2
1 RAM
32x32
32x32
MUL
MUL
MUL
MUL
MUL
1
MBF
MBF
MBF
MBF
MBF
MBF
MBF
MBF
MBF
MBF
MUL
MUL
MUL
MUL
MUL
IBF
IBF
Single
Singleport
portRAM
RAM 15:0 15:0
32x16
32x16 ADDR nWE 0.8
0.6
Address
Address counter
counter Address
Addresscounter
counter 0.4
IBF MUL MBF
0.2
FIFO
FIFO FIFO
FIFO
FIFO
FIFO 0
Different approaches:
0 500 1000 1500 2000 2500 3000 3500 4000 4500
Normalizer
exponent exponent
Normalizer
exponent exponent Memory bits
Equalizer
Equalizer
Equalizer
Equalizer
Butterfly
Butterfly
(BF)
(BF) BF
BF BF
BF 1. Dual port memory connected to an address generator. This allows simultaneous reads
W(n) -j-j
and writes to any memory location. Requires larger area than single port memories.
Normal butterfly unit Complex multiplier
and normalizing unit
Modified butterfly using equalizers to align the
data. FIFO’s with scale factor representation
2. Two single port memories, alternating between reading and writing every clock cycle
(a). The drawback is duplication of the address logic when using two memories
The proposed solution is to rescale data on the fly and minimize the memory instead of one.
requirements. No changes are required of the complex adders/multipliers due to the 3. Only one single port memory but with double word length (b). This is possible, due
simple scaling logic using normalizers and equalizing units. The scaling logic uses only to the consecutive addressing scheme used in the delay feedback. In addition to
one scale factor for representing both the real and imaginary part of a complex value. removing the duplicated address logic, the total number of memories for placement
will be reduced.
Precision Memory and area requirements
The proposed FFT processor generates a constant Signal-to-Noise ratio for all kinds of For a 2048 complex point FFT processor, the memory occupies approximately 55% of
input signals due to the scaling logic in each pipeline stage. An FFT processor using the chip area. Reducing the memory requirement will therefore significantly affect the
variable datapath produces a higher SNR if the input signal utilizes the full dynamic total size of the design. Our approach is both memory efficient and accurate.
range, but for arbitrary input signals, scaling can be used to improve the Signal-to-Noise 160
Variable data path
11
Variable data path
ratio. One of the reasons that CBFP is not capable of keeping a constant SNR is that there 140 Convergent block floating point
Our approach
Our approach using RDL
10 Convergent block floating point
Our approach
120 9
is usually no CBFP logic in the first radix-2 stage due to the high memory requirements.
Kbits of memory
60
2
Size in mm
100 8
50
% of resources
80 7 40
1 60
60 6 30
40 5 20
50
20 4 10
points points 0
0 3 FIFO memory Complex MUL + ROM Butterfly Equalizer Normalizer
40 512 1024 2048 4096 512 1024 2048 4096
Memory requirements Total chip size Resource allocation
Amplitude
SNR (dB)
0 30
20
Conclusion
Constant data path
Variable data path
An FFT processor using a novel data scaling approach that can operate on a wide range
of input signals, keeping the SNR at a constant level, has been presented. Compared to
10 Convergent block floating point
Our approach without VDL
Our approach with VDL
-1 0
1 1/2 1/4 1/8 1/16 1/32 1/64
block scaling approaches, such as CBFP, the proposed design requires significantly
smaller chip area due to the reduced memory requirements. At the same time it is
input amplitude
Arbitrary input signals with different amplitudes SNR for different amplitudes
capable of producing a higher SNR since scaling is applied in all pipeline stages.
You might also like
- Albay Numeracy Assessment Tools ALNAT ManualDocument31 pagesAlbay Numeracy Assessment Tools ALNAT ManualJuliet Echo November100% (5)
- Fundamentals of Creating A Great UI - UXDocument31 pagesFundamentals of Creating A Great UI - UXMd Rodi Bidin100% (4)
- Scorpion B-Scan Manual Rev 6.0 PDFDocument63 pagesScorpion B-Scan Manual Rev 6.0 PDFAsish desaiNo ratings yet
- PIC18F27 47 57Q84 Data Sheet 40002213DDocument1,146 pagesPIC18F27 47 57Q84 Data Sheet 40002213DGuilherme Leite JSNo ratings yet
- Capture One 22 User GuideDocument781 pagesCapture One 22 User GuideAnonymous vypymttdCONo ratings yet
- (E-House) Catalog EN 201912Document12 pages(E-House) Catalog EN 201912Design RhineNo ratings yet
- Multisim DIGITAl CircuitDocument22 pagesMultisim DIGITAl Circuitmichaeledem_royal100% (1)
- Application of Block Chain To Smart ContractsDocument16 pagesApplication of Block Chain To Smart Contractshagar sudhaNo ratings yet
- ERP Evaluation TemplateDocument5 pagesERP Evaluation Templatejancukjancuk50% (2)
- AWM TrianglesDocument196 pagesAWM TrianglesSamwell ZukNo ratings yet
- A Complete Design Flow For Silicon PhotonicsDocument17 pagesA Complete Design Flow For Silicon PhotonicsnowdayNo ratings yet
- SSP403 2.0 TDI Engine With Common Rail PDFDocument68 pagesSSP403 2.0 TDI Engine With Common Rail PDFChengdong WuNo ratings yet
- The Impact of Learning Management SystemDocument12 pagesThe Impact of Learning Management SystemGelyn Malabanan De MesaNo ratings yet
- A Fully Synthesized All-Digital VCO-Based Analog-to-Digital ConverterDocument4 pagesA Fully Synthesized All-Digital VCO-Based Analog-to-Digital Convertervinod kumar100% (1)
- Quantum Autoencoders With Enhanced Data EncodingDocument7 pagesQuantum Autoencoders With Enhanced Data EncodingfoobarukNo ratings yet
- Deep Learning-Based Semantic Segmentation in Autonomous DrivingDocument7 pagesDeep Learning-Based Semantic Segmentation in Autonomous Drivingprajna acharyaNo ratings yet
- Josephstalin BoschDocument3 pagesJosephstalin BoschJosep Stalin SNo ratings yet
- 04-2022 WIFS Y BelousovDocument6 pages04-2022 WIFS Y BelousovRémi CogranneNo ratings yet
- Enet pp005 - en eDocument4 pagesEnet pp005 - en esoayNo ratings yet
- Configuring A Poe Ip Camera: Executive SummaryDocument8 pagesConfiguring A Poe Ip Camera: Executive SummarySiddesh NevagiNo ratings yet
- Skills Profile: BSC So&Ware Engineering - Swansea UniversityDocument2 pagesSkills Profile: BSC So&Ware Engineering - Swansea UniversityhuiNo ratings yet
- Schematic Diagram: 7-1 Circuit DescriptionDocument8 pagesSchematic Diagram: 7-1 Circuit Descriptionoppa BaruNo ratings yet
- Ts 2014 109 Matrics RF FpgaDocument4 pagesTs 2014 109 Matrics RF FpgaTarun CousikNo ratings yet
- Beckhoff Main Catalog 2016 PDFDocument1,009 pagesBeckhoff Main Catalog 2016 PDFChi Lac PhungNo ratings yet
- Smart Cameras As Embedded Systems-REPORTDocument17 pagesSmart Cameras As Embedded Systems-REPORTRajalaxmi Devagirkar Kangokar100% (1)
- SSD1963 LCD Controller Graphics Card: DM320210 DM320113 DM320209 AC320005-4 AC320005-5Document6 pagesSSD1963 LCD Controller Graphics Card: DM320210 DM320113 DM320209 AC320005-4 AC320005-5syed umarjunaidNo ratings yet
- Srinivasa Rao 2016Document4 pagesSrinivasa Rao 2016Shashi KantNo ratings yet
- PosterDocument1 pagePosternazmussadiqNo ratings yet
- Real-Time Photoshop - ECE 5760Document16 pagesReal-Time Photoshop - ECE 5760Juan Sebastián PatarroyoNo ratings yet
- 600C - Users - Manual - UK DE FR IT ESDocument1 page600C - Users - Manual - UK DE FR IT ESJai Sri HariNo ratings yet
- TT710 (4GE+CATV+2WIFI xPON ONU) Datasheet-V1.0Document7 pagesTT710 (4GE+CATV+2WIFI xPON ONU) Datasheet-V1.0nguyenbaviet89No ratings yet
- Add Sector: ANTOML/MI/ME/MUDocument129 pagesAdd Sector: ANTOML/MI/ME/MUshashank.prajapati9389No ratings yet
- Marvellous Logic Building Asignment - 10Document5 pagesMarvellous Logic Building Asignment - 10Saurabh DhokeNo ratings yet
- Question-Bank Cloud ComputingDocument3 pagesQuestion-Bank Cloud ComputingHanar AhmedNo ratings yet
- 00 F 5 Sebk 320Document40 pages00 F 5 Sebk 320Mr.K chNo ratings yet
- 37522340294Document4 pages37522340294Gautam RavikumarNo ratings yet
- Video ControllerDocument57 pagesVideo ControllerCharbel TadrosNo ratings yet
- VoipDocument1 pageVoipAdeel ShamsiNo ratings yet
- Experiment Title: Uploading Sparks NotebookDocument7 pagesExperiment Title: Uploading Sparks NotebookManan SharmaNo ratings yet
- DMZ Switches: Wireless SwitchDocument1 pageDMZ Switches: Wireless SwitchAir TopNo ratings yet
- O'Sullivan Hogan Final ReportDocument65 pagesO'Sullivan Hogan Final ReportPJ O’SullivanNo ratings yet
- User Manual McMiller G1Document200 pagesUser Manual McMiller G1Tabah TricahyadiNo ratings yet
- PIC18F26 46 56Q83 Data Sheet 40002253C-3366868Document1,129 pagesPIC18F26 46 56Q83 Data Sheet 40002253C-3366868vinjopa.aaNo ratings yet
- Maths Yr 8 Block Test - Summer Term 1, Practice Version 2Document7 pagesMaths Yr 8 Block Test - Summer Term 1, Practice Version 2nomisrNo ratings yet
- Rainfall PredictionDocument8 pagesRainfall PredictionANIKET DUBEYNo ratings yet
- Facial Recognition 219Document10 pagesFacial Recognition 219Tushar RajputNo ratings yet
- Minix Neo U1Document1 pageMinix Neo U1URCOBONNo ratings yet
- VL2022230504342 DaDocument2 pagesVL2022230504342 DaRahul GuptaNo ratings yet
- Nokia Optical Networking Portfolio Poster Graphic ENDocument1 pageNokia Optical Networking Portfolio Poster Graphic ENtariqehsan168878No ratings yet
- vthl884 EnglishDocument6 pagesvthl884 Englishtammam shamiNo ratings yet
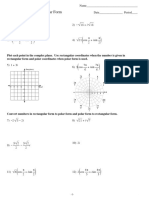
- Complex Numbers and Polar Form: ImaginaryDocument4 pagesComplex Numbers and Polar Form: ImaginaryJullifer Joseph TubaNo ratings yet
- 06 - Complex Numbers and Polar FormDocument4 pages06 - Complex Numbers and Polar FormMatematika SsvNo ratings yet
- Complex Numbers and Polar Form: ImaginaryDocument4 pagesComplex Numbers and Polar Form: ImaginaryFumira MisataNo ratings yet
- 00 Intro Dis-Embodied Minds PDFDocument2 pages00 Intro Dis-Embodied Minds PDFKyriaki DeliyiannidouNo ratings yet
- In BioDocument3 pagesIn BiolwinnaingooNo ratings yet
- Publi 6615Document5 pagesPubli 6615Bhargav ChiruNo ratings yet
- American PresidentDocument4 pagesAmerican PresidentSushanth S AnchanNo ratings yet
- GSX8-PLC Setup V103BDocument64 pagesGSX8-PLC Setup V103BvictorNo ratings yet
- Auto Mechanic Assessment Package in UrduDocument29 pagesAuto Mechanic Assessment Package in UrduInfinity School of Engineering LahoreNo ratings yet
- Rogers Wright-22.06.2020Document11 pagesRogers Wright-22.06.2020best essaysNo ratings yet
- Python Exp6 20BCS4130Document8 pagesPython Exp6 20BCS4130Manan SharmaNo ratings yet
- IOT SyllabusDocument3 pagesIOT SyllabusSarswati Bal Vidhhya Mandir Sr Sec SchoolNo ratings yet
- 5. Religion & महाजनपदDocument9 pages5. Religion & महाजनपदi35938156No ratings yet
- Lect06 PDFDocument37 pagesLect06 PDFgouthami reddyNo ratings yet
- HTB Bolt WriteupDocument24 pagesHTB Bolt Writeupdark robertNo ratings yet
- 527512437ATTRACTIONDocument9 pages527512437ATTRACTIONAmanda WandaNo ratings yet
- Telnet TNA820A20 170801 EN PDFDocument3 pagesTelnet TNA820A20 170801 EN PDFangicarNo ratings yet
- Oracle® Process Manufacturing: Product Development User's Guide Release 12.1Document390 pagesOracle® Process Manufacturing: Product Development User's Guide Release 12.1mahfuzNo ratings yet
- Telephone Etiquette: Answering CallsDocument2 pagesTelephone Etiquette: Answering CallsRICHDALE DEJITONo ratings yet
- Design Project Paper Latest 7 10 22Document29 pagesDesign Project Paper Latest 7 10 22francis john gotomangaNo ratings yet
- Emotional Viola ManualDocument18 pagesEmotional Viola ManualSebastián BisbanoNo ratings yet
- Collaborative Planning, Forecasting, and Replenishment: CPFR OriginsDocument14 pagesCollaborative Planning, Forecasting, and Replenishment: CPFR Originsshubhra_jais6888100% (1)
- The Summary Godzilla Vs KongDocument2 pagesThe Summary Godzilla Vs Kongmvpaap246810No ratings yet
- Processes 07 00938Document22 pagesProcesses 07 00938zayyanu yunusaNo ratings yet
- Telkom Contract and Service Cancellation Form PDFDocument1 pageTelkom Contract and Service Cancellation Form PDFEslam A. AliNo ratings yet
- Brightpancar Catalog PDFDocument125 pagesBrightpancar Catalog PDFBobby RajNo ratings yet
- TeX Forever! FineDocument10 pagesTeX Forever! FineSándor Nagy100% (1)
- Speed Control FinalDocument37 pagesSpeed Control FinalPrints BindingsNo ratings yet
- ADM 016 ACRS Certification Agreement (Version 3.1) WebDocument23 pagesADM 016 ACRS Certification Agreement (Version 3.1) WebMonica SinghNo ratings yet
- Genesis R90 Spare Parts Manual: Starting With Serial Number G900497Document56 pagesGenesis R90 Spare Parts Manual: Starting With Serial Number G900497NizarChoucheneNo ratings yet
- Ball Valve - An Overview - ScienceDirect TopicsDocument23 pagesBall Valve - An Overview - ScienceDirect TopicsMalik DaniyalNo ratings yet
- APMM Sustainability Report 2018Document24 pagesAPMM Sustainability Report 2018FL 564No ratings yet
- Sample Test: Page 1 - 4Document4 pagesSample Test: Page 1 - 4Nguyễn Quốc Phương UyênNo ratings yet
- Product Data Sheet: Easypact CVS - CVS100B TM100D Circuit Breaker - 3P/3dDocument2 pagesProduct Data Sheet: Easypact CVS - CVS100B TM100D Circuit Breaker - 3P/3dLorena OrtizNo ratings yet
- MUZZY BBC All Languages - MUZZY BBC Language Learning For ChildrenDocument6 pagesMUZZY BBC All Languages - MUZZY BBC Language Learning For ChildrenlisaNo ratings yet
- TW Three-Port Self-Acting Control Valve For Liquid Systems: DescriptionDocument2 pagesTW Three-Port Self-Acting Control Valve For Liquid Systems: DescriptionSenol SeidaliNo ratings yet
- GCT1 CompsDocument7 pagesGCT1 CompsDelta VisionNo ratings yet
- Plate No. 9 & 10 - Plan For Dreamhouse - 1051845990Document15 pagesPlate No. 9 & 10 - Plan For Dreamhouse - 1051845990Jessoliver GalvezNo ratings yet