You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Indian History 4Document4 pagesIndian History 4NAVYA TadisettyNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- RPF SyllabusDocument3 pagesRPF SyllabusNAVYA TadisettyNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Removed Few Points in ResumeDocument4 pagesRemoved Few Points in ResumeNAVYA TadisettyNo ratings yet
- Final - AI Associate DumpDocument108 pagesFinal - AI Associate DumpNAVYA TadisettyNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Winter 24 Key PointsDocument56 pagesWinter 24 Key PointsNAVYA TadisettyNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- 2+ Salesforce ResumeDocument4 pages2+ Salesforce ResumeNAVYA TadisettyNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- DatapreprocessingDocument8 pagesDatapreprocessingNAVYA TadisettyNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Python IntroductionDocument29 pagesPython IntroductionNAVYA TadisettyNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- ITB1 Documentation Detection of Phishing Website Using MLDocument49 pagesITB1 Documentation Detection of Phishing Website Using MLNAVYA TadisettyNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- V.K.R, V.N.B & A.G.K College of Engineering: Explain The Two Uses of Features in Machine LearningDocument2 pagesV.K.R, V.N.B & A.G.K College of Engineering: Explain The Two Uses of Features in Machine LearningNAVYA TadisettyNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Machine Learning Most Compressive Perfect BookDocument136 pagesMachine Learning Most Compressive Perfect BookNAVYA TadisettyNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
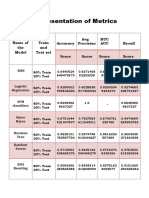
- Representation of Metrics: Name of The Model Train and Test Set Accuracy Avg Precision RUC AUC RecallDocument3 pagesRepresentation of Metrics: Name of The Model Train and Test Set Accuracy Avg Precision RUC AUC RecallNAVYA TadisettyNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Blood Relations GECDocument1 pageBlood Relations GECNAVYA TadisettyNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Pothole Guidelines PDFDocument45 pagesPothole Guidelines PDFNAVYA TadisettyNo ratings yet
- Pothole Detection and Notification System Ijariie8222 PDFDocument6 pagesPothole Detection and Notification System Ijariie8222 PDFNAVYA TadisettyNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- CJT CONN BroschureDocument756 pagesCJT CONN BroschureOzanNo ratings yet
- Adams Solver GuideDocument111 pagesAdams Solver GuideAvk SanjeevanNo ratings yet
- 7085 SolutionDocument87 pages7085 SolutionTaseer IqbalNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Exceltoci Troubleshooting GuideDocument20 pagesExceltoci Troubleshooting Guidemicheledorsey1922No ratings yet
- What Are TessellationsDocument4 pagesWhat Are Tessellationshusni centreNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Sumobot CodeDocument5 pagesSumobot Codeabubakar_13No ratings yet
- Flir E6 + Wifi - (63907-0704)Document4 pagesFlir E6 + Wifi - (63907-0704)Walter Guardia FariasNo ratings yet
- Intelligence Officer Weekly Test 01Document16 pagesIntelligence Officer Weekly Test 01onlyforacademy13No ratings yet
- Fake News Detection - ReportDocument59 pagesFake News Detection - ReportSANGEETHKUMAR C100% (1)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Further Pure Mathematics F1: Pearson EdexcelDocument32 pagesFurther Pure Mathematics F1: Pearson EdexcelLukeTayNo ratings yet
- I/O Basics: Ports Data, Control, and Status BitsDocument11 pagesI/O Basics: Ports Data, Control, and Status BitsNikhil GobhilNo ratings yet
- Computer Systems Servicing DLLDocument11 pagesComputer Systems Servicing DLLFhikery ArdienteNo ratings yet
- Sterile Tube Fuser - DRY: GE Healthcare Life SciencesDocument50 pagesSterile Tube Fuser - DRY: GE Healthcare Life SciencesCarlos Alberto Ramirez GarciaNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- PDFDocument188 pagesPDFA S Salam AliNo ratings yet
- EXPERIMNET 0: (Environment Configuration & Sample Program)Document7 pagesEXPERIMNET 0: (Environment Configuration & Sample Program)jfkajlfjNo ratings yet
- Exstream05Content03Doc PDFDocument198 pagesExstream05Content03Doc PDFAymen EL ARBINo ratings yet
- Chapter 2Document31 pagesChapter 2pavanikaveesha9562No ratings yet
- Modelo Ecm370Document420 pagesModelo Ecm370RENO100% (2)
- 271 7Document0 pages271 7Usman Sabir100% (1)
- DBM CSC FormDocument4 pagesDBM CSC FormJing Goal Merit0% (1)
- Smart Parking and Reservation System For Qr-Code Based Car ParkDocument6 pagesSmart Parking and Reservation System For Qr-Code Based Car ParkMinal ShahakarNo ratings yet
- CST363 Final Exam HuyNguyenDocument9 pagesCST363 Final Exam HuyNguyenHuy NguyenNo ratings yet
- 07-Huawei FTTO Solution IMaster NCE Platform V1.3- 5月26日Document75 pages07-Huawei FTTO Solution IMaster NCE Platform V1.3- 5月26日Digits HomeNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Globalization Syllabus S22Document11 pagesGlobalization Syllabus S22Manit ShahNo ratings yet
- Revision For SBADocument9 pagesRevision For SBABoriss NovichkovsNo ratings yet
- Swpe06 en Pss e Iec 60909 Fault Calculations s4Document2 pagesSwpe06 en Pss e Iec 60909 Fault Calculations s4Fitz Gerald Vidal100% (1)
- Medecare E-MAR Training ManualDocument121 pagesMedecare E-MAR Training ManualTechTotalNo ratings yet
- 400, 800, 2300, 2300D Series: Small, Two-Piece, Nonmetallic Raceway SystemsDocument8 pages400, 800, 2300, 2300D Series: Small, Two-Piece, Nonmetallic Raceway SystemsMohanathan VCNo ratings yet
- Pneumatic Forging MachineDocument28 pagesPneumatic Forging MachineSaravanan Viswakarma83% (6)
- IAL Mathematics Sample Assessment MaterialDocument460 pagesIAL Mathematics Sample Assessment MaterialMohamed Naaif100% (3)
- Four Battlegrounds: Power in the Age of Artificial IntelligenceFrom EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceRating: 5 out of 5 stars5/5 (5)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet