You might also like
- UntitledDocument56 pagesUntitledblue CuteeNo ratings yet
- Ultimate guide for being anonymous: Avoiding prison time for fun and profitFrom EverandUltimate guide for being anonymous: Avoiding prison time for fun and profitRating: 4.5 out of 5 stars4.5/5 (7)
- PHISHING WEBSITE DETECTION USING MACHINE LEARNING - COMPLETED (1) FullDocument73 pagesPHISHING WEBSITE DETECTION USING MACHINE LEARNING - COMPLETED (1) Fullpkaentertainment2905No ratings yet
- Raika ShahLJdADocument8 pagesRaika ShahLJdAYashwanth B KNo ratings yet
- A N A P V C: Ovel NTI Hishing Framework Based On Isual RyptographyDocument12 pagesA N A P V C: Ovel NTI Hishing Framework Based On Isual Ryptographytariq76No ratings yet
- Performance Analysis of Data Mining, Machine Learning and Fuzzy Logic Algorithms For Detecting PhishDocument10 pagesPerformance Analysis of Data Mining, Machine Learning and Fuzzy Logic Algorithms For Detecting PhishAshmeetNo ratings yet
- Detect Phishing Websites Using MLDocument6 pagesDetect Phishing Websites Using MLHarikrishnan ShunmugamNo ratings yet
- Cyber Security Tips to Prevent Insider ThreatsDocument7 pagesCyber Security Tips to Prevent Insider ThreatsCrAziie NeLlNo ratings yet
- Detecting_phishing_website_with_Code_ImplementationDocument13 pagesDetecting_phishing_website_with_Code_Implementationsandeepghodeswar86No ratings yet
- Synopsis of Project On Automatic Phishing Email Website Detection System Using Fuzzy TechniquesDocument20 pagesSynopsis of Project On Automatic Phishing Email Website Detection System Using Fuzzy Techniquesaccord123No ratings yet
- Framework For Detection and Prevention of Phishing Website Using Machine Learning ApproachDocument18 pagesFramework For Detection and Prevention of Phishing Website Using Machine Learning ApproachKiran MudaliyarNo ratings yet
- A Framework For Predicting Phishing Websites Using Neural NetworksDocument7 pagesA Framework For Predicting Phishing Websites Using Neural NetworksdhineshpNo ratings yet
- Detect Phishing Attacks OnlineDocument6 pagesDetect Phishing Attacks OnlineSai SrinivasNo ratings yet
- Web Security Using Visual Cryptography Against Phishing: Anjali Jose and S. Vinoth LakshmiDocument7 pagesWeb Security Using Visual Cryptography Against Phishing: Anjali Jose and S. Vinoth LakshmiDheeraj13No ratings yet
- Phishing Attacks and Effective CountermeasuresDocument14 pagesPhishing Attacks and Effective CountermeasuresjeremykjmNo ratings yet
- File ServeDocument5 pagesFile ServeramyaNo ratings yet
- Enhanced Phishing Website Detection: Leveraging Random Forest and XGBoost Algorithms With Hybrid FeaturesDocument4 pagesEnhanced Phishing Website Detection: Leveraging Random Forest and XGBoost Algorithms With Hybrid FeaturesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Detection of URL Based Phishing Websites Using Machine LearningDocument6 pagesDetection of URL Based Phishing Websites Using Machine LearningEditor IJTSRDNo ratings yet
- ADVANCED E-SECURITY: DYNAMIC SECURITY SKINS PREVENT PHISHINGDocument14 pagesADVANCED E-SECURITY: DYNAMIC SECURITY SKINS PREVENT PHISHINGMuthu SelvaNo ratings yet
- Detection of Phishing Websites Using PSO and Machine Learning FrameworksDocument3 pagesDetection of Phishing Websites Using PSO and Machine Learning FrameworksInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Intelligent Phishing Website Detection and Prevention System by Using Link Guard AlgorithmDocument9 pagesIntelligent Phishing Website Detection and Prevention System by Using Link Guard Algorithmsagar sagNo ratings yet
- Classification of Features For Detecting Phishing Web Sites Based On Machine Learning TechniquesDocument51 pagesClassification of Features For Detecting Phishing Web Sites Based On Machine Learning TechniquesRavi Kiran RajbhureNo ratings yet
- Detection of Phishing AttackDocument46 pagesDetection of Phishing Attacksuresh mpNo ratings yet
- Phishing Website Detectiion SynopsisDocument2 pagesPhishing Website Detectiion Synopsisrajneeshverma3816No ratings yet
- Intelligent Phishing Website Detection and Prevention System by Using Link Guard AlgorithmDocument9 pagesIntelligent Phishing Website Detection and Prevention System by Using Link Guard AlgorithmInternational Organization of Scientific Research (IOSR)No ratings yet
- Fake UrlDocument64 pagesFake UrlChaitan BruceNo ratings yet
- Machine Learning Approach To Phishing Detection: Arvind Rekha Sura Jyoti Kini Kishan AthreyDocument7 pagesMachine Learning Approach To Phishing Detection: Arvind Rekha Sura Jyoti Kini Kishan AthreyRed NyNo ratings yet
- Web Browser To Prevent Phishing and Sybil AttacksDocument4 pagesWeb Browser To Prevent Phishing and Sybil AttacksInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- A Machine Learning Approach For Detection of Phished Websites Using Neural NetworksDocument5 pagesA Machine Learning Approach For Detection of Phished Websites Using Neural NetworksrebwarpcNo ratings yet
- Digital Footprint - White PaperDocument5 pagesDigital Footprint - White PaperTrip KrantNo ratings yet
- An Ideal Approach For Detection and Prevention ofDocument11 pagesAn Ideal Approach For Detection and Prevention ofBhargavi YerramNo ratings yet
- Detection of Phishing Websites Using An Efficient FeatureDocument11 pagesDetection of Phishing Websites Using An Efficient FeatureKpsmurugesan KpsmNo ratings yet
- Review On Phishing Attack Detection Using Recurrent Neural NetworkDocument6 pagesReview On Phishing Attack Detection Using Recurrent Neural NetworkIJRASETPublicationsNo ratings yet
- Detection of Phishing WebsiteDocument12 pagesDetection of Phishing WebsiteOm RautNo ratings yet
- Phishing SeminarDocument19 pagesPhishing SeminarAditya ghadgeNo ratings yet
- Oppa MailDocument70 pagesOppa MailmonumoluNo ratings yet
- Detection of Phishing URLs Using Machine LearningDocument6 pagesDetection of Phishing URLs Using Machine LearningRokibul hasanNo ratings yet
- Credit Card Fraud DetectionDocument72 pagesCredit Card Fraud DetectionRomeo DeepakNo ratings yet
- My WorkDocument50 pagesMy WorkProsper NwambuNo ratings yet
- Phishing Website Detection Using Fuzzy Logic: Twinkll Sisodia Simran ChoudharyDocument6 pagesPhishing Website Detection Using Fuzzy Logic: Twinkll Sisodia Simran ChoudharyTwinkllNo ratings yet
- Detection of PhishingDocument7 pagesDetection of Phishingpriya manasaNo ratings yet
- Literature Survey PNT2022TMID35524Document6 pagesLiterature Survey PNT2022TMID35524Cine Talikes TamilNo ratings yet
- Anti Phishing AttacksDocument58 pagesAnti Phishing AttacksSneha Gupta0% (1)
- Expert Systems With Applications: Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir, Banu DiriDocument13 pagesExpert Systems With Applications: Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir, Banu DiriSantosh KBNo ratings yet
- Unlicensed RahulDocument8 pagesUnlicensed RahulRahul BHatnagarNo ratings yet
- PUMMP: Phishing URL Detection Using Machine Learning With Monomorphic and Polymorphic Treatment of FeaturesDocument20 pagesPUMMP: Phishing URL Detection Using Machine Learning With Monomorphic and Polymorphic Treatment of FeaturesAIRCC - IJCNCNo ratings yet
- Phishing Website Detector Using MLDocument8 pagesPhishing Website Detector Using MLIJRASETPublicationsNo ratings yet
- Synopsis: PROJECT TITLE: "Securing Online Transaction Using Face Recognition"Document7 pagesSynopsis: PROJECT TITLE: "Securing Online Transaction Using Face Recognition"Akshu SushiNo ratings yet
- Detection of Phishing Websites Using Machine Learning: Specialusis Ugdymas / Special Education 2022 1Document7 pagesDetection of Phishing Websites Using Machine Learning: Specialusis Ugdymas / Special Education 2022 1cristo555625No ratings yet
- Ethical Hacking A Licence To HackDocument21 pagesEthical Hacking A Licence To HackAseem15No ratings yet
- Foot PrintingDocument4 pagesFoot Printingaabidmahat144No ratings yet
- Seminar PPT TI19Document19 pagesSeminar PPT TI19Aditya ghadgeNo ratings yet
- IJCRT2106008Document6 pagesIJCRT2106008vssNo ratings yet
- Detection of Url Based Phishing Attacks Using Machine Learning IJERTV8IS110269Document8 pagesDetection of Url Based Phishing Attacks Using Machine Learning IJERTV8IS110269ITWorldNo ratings yet
- Phishing Website Detection Using Machine Learning AlgorithmsDocument4 pagesPhishing Website Detection Using Machine Learning AlgorithmsTrịnh Văn ThoạiNo ratings yet
- Running Head: Cyber Crime: HackingDocument8 pagesRunning Head: Cyber Crime: HackingNiomi GolraiNo ratings yet
- Classification of Phishing Website Using Hybrid Machine Learning TechniquesDocument6 pagesClassification of Phishing Website Using Hybrid Machine Learning TechniquesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Technical Solution Document: Version Number: 0.0 Version Date: May 9, 2016Document20 pagesTechnical Solution Document: Version Number: 0.0 Version Date: May 9, 2016Aakash ParwaniNo ratings yet
- Project Report1Document83 pagesProject Report1devilNo ratings yet
- Integration Patterns and PracticesDocument67 pagesIntegration Patterns and PracticesJose De La TorreNo ratings yet
- 2+ Salesforce ResumeDocument4 pages2+ Salesforce ResumeNAVYA TadisettyNo ratings yet
- Winter 24 Key PointsDocument56 pagesWinter 24 Key PointsNAVYA TadisettyNo ratings yet
- Removed Few Points in ResumeDocument4 pagesRemoved Few Points in ResumeNAVYA TadisettyNo ratings yet
- Final - AI Associate DumpDocument108 pagesFinal - AI Associate DumpNAVYA TadisettyNo ratings yet
- Paper 2-Phishing Websites Detection Using Machine LearningDocument6 pagesPaper 2-Phishing Websites Detection Using Machine LearningNAVYA TadisettyNo ratings yet
- Get Started With SalesforceDocument269 pagesGet Started With Salesforcetwinkle.salesforceNo ratings yet
- Final - AI Associate DumpDocument108 pagesFinal - AI Associate DumpNAVYA TadisettyNo ratings yet
- Formulas Cheat SheetDocument2 pagesFormulas Cheat SheetRohit EdnaniNo ratings yet
- V.K.R, V.N.B & A.G.K COLLEGE OF ENGINEERING ML questionsDocument2 pagesV.K.R, V.N.B & A.G.K COLLEGE OF ENGINEERING ML questionsNAVYA TadisettyNo ratings yet
- CT ICCC2013 Phishing PDFDocument7 pagesCT ICCC2013 Phishing PDFnani yagantiNo ratings yet
- CT ICCC2013 Phishing PDFDocument7 pagesCT ICCC2013 Phishing PDFnani yagantiNo ratings yet
- DatapreprocessingDocument8 pagesDatapreprocessingNAVYA TadisettyNo ratings yet
- Phishing Websites Detection Using Machine Learning: R. Kiruthiga, D. AkilaDocument4 pagesPhishing Websites Detection Using Machine Learning: R. Kiruthiga, D. AkilaNAVYA TadisettyNo ratings yet
- 180 - 11 - 208355 - 1610176884 - BPU Course Participation CertificateDocument1 page180 - 11 - 208355 - 1610176884 - BPU Course Participation CertificateNAVYA TadisettyNo ratings yet
- VHJGDHJDocument41 pagesVHJGDHJneeraj sharmaNo ratings yet
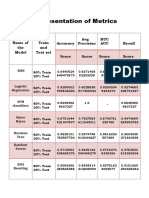
- Representation of Metrics: Name of The Model Train and Test Set Accuracy Avg Precision RUC AUC RecallDocument3 pagesRepresentation of Metrics: Name of The Model Train and Test Set Accuracy Avg Precision RUC AUC RecallNAVYA TadisettyNo ratings yet
- Wrong Number SeriesDocument43 pagesWrong Number SeriesMahendraKumar100% (1)
- Python IntroductionDocument29 pagesPython IntroductionNAVYA TadisettyNo ratings yet
- Machine Learning Most Compressive Perfect BookDocument136 pagesMachine Learning Most Compressive Perfect BookNAVYA TadisettyNo ratings yet
- HCIA-AI V1.0 Training MaterialsDocument429 pagesHCIA-AI V1.0 Training Materialsmulte123No ratings yet
- HCIA-AI V1.0 Lab GuideDocument124 pagesHCIA-AI V1.0 Lab Guidemulte123No ratings yet
- 5 6301081717495038123Document53 pages5 6301081717495038123Aaron VedanayagamNo ratings yet
- HCIA-AI V1.0 Lab GuideDocument124 pagesHCIA-AI V1.0 Lab Guidemulte123No ratings yet
- Wrong Number SeriesDocument43 pagesWrong Number SeriesMahendraKumar100% (1)
- Appendix A Oracle PLSQLDocument66 pagesAppendix A Oracle PLSQLdiego ojedaNo ratings yet
- Key - Blood Relations KeyDocument2 pagesKey - Blood Relations KeyNAVYA TadisettyNo ratings yet
- Key - Mixtures&Alligations-keyDocument3 pagesKey - Mixtures&Alligations-keyNAVYA TadisettyNo ratings yet
- Key - AveragesDocument2 pagesKey - AveragesNAVYA TadisettyNo ratings yet
- Sta733 AukDocument3 pagesSta733 AukJhon Arenas100% (1)
- It Governance According To CobitDocument67 pagesIt Governance According To CobitAyif FirmansyahNo ratings yet
- M1-Assignment Solution-AlgorithmDocument2 pagesM1-Assignment Solution-AlgorithmRaman deepNo ratings yet
- Inventor AddINDocument27 pagesInventor AddINgwyderNo ratings yet
- Unit VI 80386DX Signals, Bus Cycles, 80387 CoprocessorDocument26 pagesUnit VI 80386DX Signals, Bus Cycles, 80387 CoprocessorShanti GuruNo ratings yet
- Primavera P6 Exercise WorksheetDocument48 pagesPrimavera P6 Exercise WorksheetMuhammad Bilal100% (2)
- Licensed X-ray Equipment Manufacturers ListDocument3 pagesLicensed X-ray Equipment Manufacturers ListVishnu0049No ratings yet
- KingView 6.52 Introduction PDFDocument108 pagesKingView 6.52 Introduction PDFconan lcNo ratings yet
- Hotels Sector Analysis Report: SupplyDocument7 pagesHotels Sector Analysis Report: SupplyArun AhirwarNo ratings yet
- Chinese Remainder Theorem PDFDocument5 pagesChinese Remainder Theorem PDFAnish RayNo ratings yet
- WASH Plan Guideline-Nepali-March 2020-final-29-03-2020Document74 pagesWASH Plan Guideline-Nepali-March 2020-final-29-03-2020moushamacharya5No ratings yet
- PotencialFlowF - White Fluid Mechanics 2009Document29 pagesPotencialFlowF - White Fluid Mechanics 2009Eldin Celo Celebic100% (1)
- Promis User ManualDocument56 pagesPromis User ManualErnest V SNo ratings yet
- Essential of Marketing DigitalDocument7 pagesEssential of Marketing DigitalSuntrackCorporaçãoNo ratings yet
- CrashDocument4 pagesCrashzDarkCodexNo ratings yet
- The Implementation of Phasor Measurement TechnologyDocument6 pagesThe Implementation of Phasor Measurement TechnologyTravis WoodNo ratings yet
- Chapter 2 Criteria For DecisionDocument10 pagesChapter 2 Criteria For DecisionMohamed El KhojaNo ratings yet
- Neon and Unique Custom Car Colors for GTA OnlineDocument2 pagesNeon and Unique Custom Car Colors for GTA OnlineProto NeturiuNo ratings yet
- New Microsoft Office Excel WorksheetDocument1,194 pagesNew Microsoft Office Excel WorksheetSrikanth ChintaNo ratings yet
- IncomingDocument8 pagesIncomingvg_vvgNo ratings yet
- Game Art A Manifesto by Matteo BittantiDocument5 pagesGame Art A Manifesto by Matteo BittantiAnna KozlovaNo ratings yet
- Online MetroCard Recharge - TutorialsDuniyaDocument36 pagesOnline MetroCard Recharge - TutorialsDuniyaGurkirat SinghNo ratings yet
- Neil Landeen and Arizona Department of Public Safety Employee CoorespondenceDocument34 pagesNeil Landeen and Arizona Department of Public Safety Employee CoorespondenceForBlueNo ratings yet
- 800xa - Information - Management - Configuration 5.1Document650 pages800xa - Information - Management - Configuration 5.1RahulKoriNo ratings yet
- Latest Yahoo Format 2020. Format For Billing Clients and PDF DownloadDocument2 pagesLatest Yahoo Format 2020. Format For Billing Clients and PDF DownloadRoyal T85% (71)
- Microsoft: AZ-303 ExamDocument140 pagesMicrosoft: AZ-303 ExamGhanshyam KhetanNo ratings yet
- AssignmentDocument8 pagesAssignmentdillumiya132No ratings yet
- Cryptographer's Way - Bradford Hardie IIIDocument100 pagesCryptographer's Way - Bradford Hardie IIIiTiSWRiTTENNo ratings yet
- Transmision PDFDocument26 pagesTransmision PDFAirton Ahyrton Macazana HuaringaNo ratings yet
- CCL to Upload Download CNC Console Fanuc 6M/GN6Document2 pagesCCL to Upload Download CNC Console Fanuc 6M/GN6Zoran SpiroskiNo ratings yet