You might also like
- Latin America: Top 10.000 ScientistsDocument753 pagesLatin America: Top 10.000 ScientistsFelipe KaewNo ratings yet
- Zhu Han - Dusit Niyato - Walid Saad - Tamer Basar - Game Theory For Next Generation Wireless and Communication Networks - Modeling, Analysis, and Design (2019, Cambridge University Press)Document507 pagesZhu Han - Dusit Niyato - Walid Saad - Tamer Basar - Game Theory For Next Generation Wireless and Communication Networks - Modeling, Analysis, and Design (2019, Cambridge University Press)Felipe KaewNo ratings yet
- Dgalab: An Extensible Software Implementation For Dga: Saleh I. Ibrahim, Sherif S.M. Ghoneim, Ibrahim B.M. TahaDocument8 pagesDgalab: An Extensible Software Implementation For Dga: Saleh I. Ibrahim, Sherif S.M. Ghoneim, Ibrahim B.M. TahaFelipe KaewNo ratings yet
- Fault Diagnosis of Power Transformer Based On Multi-Layer SVM ClassifierDocument7 pagesFault Diagnosis of Power Transformer Based On Multi-Layer SVM ClassifierFelipe KaewNo ratings yet
- Power Transformer Fault Diagnosis Considering Data Imbalance and Data Set FusionDocument12 pagesPower Transformer Fault Diagnosis Considering Data Imbalance and Data Set FusionFelipe KaewNo ratings yet
- Case Study On Power Transformer Usingdissolved Gas Analysis TechniqueDocument4 pagesCase Study On Power Transformer Usingdissolved Gas Analysis TechniqueFelipe KaewNo ratings yet
- Fusao de SensoresDocument15 pagesFusao de SensoresFelipe KaewNo ratings yet
- Fault Prediction of Transformer Using Machine Learning and DGADocument5 pagesFault Prediction of Transformer Using Machine Learning and DGAFelipe KaewNo ratings yet
- Electrical Power and Energy Systems: Sherif S.M. Ghoneim, Ibrahim B.M. TahaDocument10 pagesElectrical Power and Energy Systems: Sherif S.M. Ghoneim, Ibrahim B.M. TahaFelipe KaewNo ratings yet
- Statistical Machine Learning and Dissolved Gas Analysis - A Review - Mirowski - LeCunDocument9 pagesStatistical Machine Learning and Dissolved Gas Analysis - A Review - Mirowski - LeCunFelipe KaewNo ratings yet
- A Novel Extension Method For Transformer Fault Diagnosis: Mang-Hui Wang, Member, IEEEDocument6 pagesA Novel Extension Method For Transformer Fault Diagnosis: Mang-Hui Wang, Member, IEEEFelipe KaewNo ratings yet
- Improving Diagnostic Performance of A Power Transformer Using An Adaptive Over-Sampling Method For Imbalanced DataDocument9 pagesImproving Diagnostic Performance of A Power Transformer Using An Adaptive Over-Sampling Method For Imbalanced DataFelipe KaewNo ratings yet
- Research Article: Dissolved Gas Analysis of Insulating Oil in Electric Power Transformers: A Case Study Using SDAE-LSTMDocument10 pagesResearch Article: Dissolved Gas Analysis of Insulating Oil in Electric Power Transformers: A Case Study Using SDAE-LSTMFelipe KaewNo ratings yet
- A Century of Dissolved Gas Analysis - Part IiiDocument9 pagesA Century of Dissolved Gas Analysis - Part IiiFelipe KaewNo ratings yet
- A Method For Dissolved Gas Forecasting in Power Transformers Using LS-SVMDocument8 pagesA Method For Dissolved Gas Forecasting in Power Transformers Using LS-SVMFelipe KaewNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5806)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (589)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (842)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Control Software For Radian Research DytronicDocument64 pagesControl Software For Radian Research DytronicLia Aithana HiNo ratings yet
- Turing Machine (Solved Examples) .mp4Document8 pagesTuring Machine (Solved Examples) .mp4SATYAM MISHRANo ratings yet
- KNIME Introduction 2023-07Document52 pagesKNIME Introduction 2023-07John KimutaiNo ratings yet
- By The Name of ALLAH The Most Merciful and Mighty: MacsymaDocument70 pagesBy The Name of ALLAH The Most Merciful and Mighty: MacsymaJunaid khan100% (2)
- FFT - Basics - B&KDocument45 pagesFFT - Basics - B&KjohnnyjNo ratings yet
- Compiler Construction CS-4207: Instructor Name: Atif IshaqDocument13 pagesCompiler Construction CS-4207: Instructor Name: Atif IshaqFaisal ShehzadNo ratings yet
- AAI Process DiscoveryDocument22 pagesAAI Process DiscoveryMartiniano MallavibarrenaNo ratings yet
- Chromebook User GuideDocument1 pageChromebook User GuideПолина МиховаNo ratings yet
- Microsoft Commerce Server 2009 Installation and Configuration GuideDocument118 pagesMicrosoft Commerce Server 2009 Installation and Configuration GuideksarrafiNo ratings yet
- ST Lab ManualDocument52 pagesST Lab ManualPqrsNo ratings yet
- IT6602 SA Coaching Class QuestionsDocument3 pagesIT6602 SA Coaching Class QuestionsvinothNo ratings yet
- Getting Started With SimicsDocument77 pagesGetting Started With Simicsprathap13No ratings yet
- RTOS and IDE For Embedded System DesignDocument31 pagesRTOS and IDE For Embedded System DesignNITISH SHETNo ratings yet
- Final Mini Project PPT (d8) PDFDocument29 pagesFinal Mini Project PPT (d8) PDFSowmya LakshmiNo ratings yet
- Forensic APFS File Recovery: Jonas Plum Andreas DewaldDocument11 pagesForensic APFS File Recovery: Jonas Plum Andreas DewaldJunetouNo ratings yet
- XFile3 Userman 5.2Document198 pagesXFile3 Userman 5.2Arunkumar KNo ratings yet
- Runescape Spreading GuideDocument7 pagesRunescape Spreading GuideGUy FawkesNo ratings yet
- Cópia de Hytera HP70X Uv&V1 Service Manual V01 - EngDocument189 pagesCópia de Hytera HP70X Uv&V1 Service Manual V01 - EngALEX FERNANDESNo ratings yet
- Imx 8 MncecDocument114 pagesImx 8 MncecNoel LiarteNo ratings yet
- Timers in 8051 - NotesDocument13 pagesTimers in 8051 - NotesPeaceNo ratings yet
- Software Requirement Eng NotesDocument4 pagesSoftware Requirement Eng NotesHafsaparkerNo ratings yet
- 1 Sem M.tech SyllabusDocument9 pages1 Sem M.tech SyllabusAbhay BhagatNo ratings yet
- 95-06360 REV. J INSERT-Epic 950 Spare Parts GuideDocument30 pages95-06360 REV. J INSERT-Epic 950 Spare Parts GuideSTEVEN WUNo ratings yet
- Mesa County Database and System AnalysisDocument22 pagesMesa County Database and System AnalysisElectionFraud20.orgNo ratings yet
- Camouflage Technique Based Multifunctional Army RobotDocument3 pagesCamouflage Technique Based Multifunctional Army RobotKarthik SNo ratings yet
- Cps Pointers and Preprocessor Vtu NotesDocument9 pagesCps Pointers and Preprocessor Vtu Notesß.shashank mallyaNo ratings yet
- GEM Premier 3500 - Interface ProtocolDocument136 pagesGEM Premier 3500 - Interface ProtocolJoão VictorNo ratings yet
- Dell Networking s4048 On Spec SheetDocument4 pagesDell Networking s4048 On Spec Sheetlakis lalakis888No ratings yet
- Basics of Routing: Link StateDocument33 pagesBasics of Routing: Link StateJef BenNo ratings yet
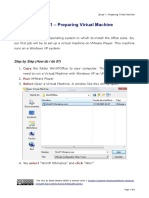
- Script 1 - Preparing Virtual Machine: Step by Step (How Do I Do It?)Document5 pagesScript 1 - Preparing Virtual Machine: Step by Step (How Do I Do It?)nbarreiroNo ratings yet