You might also like
- Commercial Drivers License (CDL) Study GuideDocument20 pagesCommercial Drivers License (CDL) Study GuideMcRee Learning Center0% (1)
- Lecture Notes: Psychological AssessmentDocument20 pagesLecture Notes: Psychological Assessmenttaylor alison swift100% (3)
- Lecture 7.descriptive and Inferential StatisticsDocument44 pagesLecture 7.descriptive and Inferential StatisticsKhurram SherazNo ratings yet
- SOP 20-005 Sampling InspectionDocument9 pagesSOP 20-005 Sampling InspectionsushmaxNo ratings yet
- T TestDocument16 pagesT TestMohammad Abdul OhabNo ratings yet
- A Failure Surface For Caisson Foundations in Undrained Soils.Document7 pagesA Failure Surface For Caisson Foundations in Undrained Soils.franciscoerezNo ratings yet
- In Hypothesis TestingDocument20 pagesIn Hypothesis TestingDhara TandonNo ratings yet
- Hypothesis Testing GDocument28 pagesHypothesis Testing GRenee Jezz LopezNo ratings yet
- Presentation T TestDocument31 pagesPresentation T TestEe HAng Yong0% (1)
- RSDQ ModelDocument29 pagesRSDQ Modelabhi22smartyNo ratings yet
- 1technical English 4 Teacher S BookDocument136 pages1technical English 4 Teacher S BookОся Далакова75% (8)
- T03 Risk Assessment MethodologyDocument26 pagesT03 Risk Assessment MethodologyandrelorandiNo ratings yet
- 3 Reiss, Steven-The Sixteen Strivings For GodDocument0 pages3 Reiss, Steven-The Sixteen Strivings For GodPunnakayamNo ratings yet
- T TEST LectureDocument26 pagesT TEST LectureMax SantosNo ratings yet
- Analysis of VarianceDocument82 pagesAnalysis of VarianceshilpeekumariNo ratings yet
- Paired Sample T-TestDocument23 pagesPaired Sample T-TestMuhamad Razif Kassim100% (1)
- Safety ChecklistDocument8 pagesSafety ChecklistdharmaNo ratings yet
- Statistics ReportDocument64 pagesStatistics ReportCarmela CampomanesNo ratings yet
- Chapter 008-Data Analysis Techniques-UpdateDocument32 pagesChapter 008-Data Analysis Techniques-UpdateSuryanti TsangNo ratings yet
- HR Analytics Applications of Comparison of Means and ANOVADocument25 pagesHR Analytics Applications of Comparison of Means and ANOVAChallaKoundinyaVinayNo ratings yet
- Assignment Topic: T-Test: Department of Education Hazara University MansehraDocument5 pagesAssignment Topic: T-Test: Department of Education Hazara University MansehraEsha EshaNo ratings yet
- 3 - Data Analysis - Tests of DifferencesDocument50 pages3 - Data Analysis - Tests of Differencesmnrk 1997No ratings yet
- Dewi Prita Statistic 4DDocument7 pagesDewi Prita Statistic 4DSihatNo ratings yet
- Hypothesis Testing Parametric and Non Parametric TestsDocument14 pagesHypothesis Testing Parametric and Non Parametric Testsreeya chhetriNo ratings yet
- Non Parametric Test: Business Research MethodsDocument26 pagesNon Parametric Test: Business Research MethodsVaishnavi khotNo ratings yet
- Research Methods Unit 4Document6 pagesResearch Methods Unit 4MukulNo ratings yet
- Multivariate AnalysisDocument11 pagesMultivariate AnalysisCerlin PajilaNo ratings yet
- Research MethodologyDocument23 pagesResearch MethodologynuravNo ratings yet
- Student's T-Test FINALDocument26 pagesStudent's T-Test FINALMarwa MohamedNo ratings yet
- Exp 3Document35 pagesExp 3Bakchodi WalaNo ratings yet
- T-Test Vs ANOVADocument3 pagesT-Test Vs ANOVAsomiNo ratings yet
- Research Methodology - Module: 3: Prepare By: Prof. Vijay BhatuDocument75 pagesResearch Methodology - Module: 3: Prepare By: Prof. Vijay BhatuMRDIYA DHARMIKNo ratings yet
- Parametric and Non-Parametric Tests of Numerical VariablesDocument18 pagesParametric and Non-Parametric Tests of Numerical Variablesahi5No ratings yet
- Final ExamDocument47 pagesFinal ExamGerald HernandezNo ratings yet
- Inferential StatisticsDocument19 pagesInferential StatisticsJandy CastilloNo ratings yet
- Notes Unit-4 BRMDocument10 pagesNotes Unit-4 BRMDr. Moiz AkhtarNo ratings yet
- One Way Analysis of Variance Tech PaperDocument10 pagesOne Way Analysis of Variance Tech PaperPriyanka Vijaya KumarNo ratings yet
- Analysis of VarianceDocument12 pagesAnalysis of VariancesyedamiriqbalNo ratings yet
- 1) One-Sample T-TestDocument5 pages1) One-Sample T-TestShaffo KhanNo ratings yet
- BRM Unit-3Document22 pagesBRM Unit-3K R SAI LAKSHMINo ratings yet
- Chapter 4. Non-Parametric Test: Second Semester 2019 - 2020Document7 pagesChapter 4. Non-Parametric Test: Second Semester 2019 - 2020Duay Guadalupe VillaestivaNo ratings yet
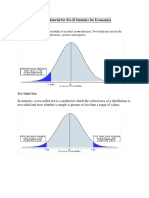
- Study Material For BA-II Statistics For Economics: One Tailed TestDocument9 pagesStudy Material For BA-II Statistics For Economics: One Tailed TestC.s TanyaNo ratings yet
- L 11, One Sample TestDocument10 pagesL 11, One Sample TestShan AliNo ratings yet
- Session 10 Bivariate Statistical AnalysisDocument72 pagesSession 10 Bivariate Statistical Analysis庄敏敏No ratings yet
- Session 10 Bivariate Statistical AnalysisDocument72 pagesSession 10 Bivariate Statistical Analysis庄敏敏No ratings yet
- SPSS AssignmentDocument6 pagesSPSS Assignmentaanya jainNo ratings yet
- Be A 65 Ads Exp 4Document17 pagesBe A 65 Ads Exp 4Ritika dwivediNo ratings yet
- Testing The Difference - T Test ExplainedDocument17 pagesTesting The Difference - T Test ExplainedMary Mae PontillasNo ratings yet
- StatDocument70 pagesStatcj_anero67% (3)
- Parametric and Non Parametric TestsDocument4 pagesParametric and Non Parametric TestsZubaria KhanamNo ratings yet
- Main Title: Planning Data Analysis Using Statistical DataDocument40 pagesMain Title: Planning Data Analysis Using Statistical DataRuffa L100% (1)
- 3.1 Comparing Two MeansDocument26 pages3.1 Comparing Two MeansPramey JainNo ratings yet
- Spss 3Document27 pagesSpss 3Eleni BirhanuNo ratings yet
- Test On Variables: in Surveys, The Foolish Ask Questions, Wise Cannot AnswersDocument24 pagesTest On Variables: in Surveys, The Foolish Ask Questions, Wise Cannot AnswersNirmal ModhNo ratings yet
- Mann Whitney U Test: ENS 185 - Data AnalysisDocument100 pagesMann Whitney U Test: ENS 185 - Data AnalysisClarkNo ratings yet
- Chapter 13: Introduction To Analysis of VarianceDocument26 pagesChapter 13: Introduction To Analysis of VarianceAlia Al ZghoulNo ratings yet
- Q. 1 How Is Mode Calculated? Also Discuss Its Merits and Demerits. AnsDocument13 pagesQ. 1 How Is Mode Calculated? Also Discuss Its Merits and Demerits. AnsGHULAM RABANINo ratings yet
- Business Research Methods: MBA - FALL 2014Document32 pagesBusiness Research Methods: MBA - FALL 2014Mahum KamilNo ratings yet
- Collection and Presentation of DatafinalDocument95 pagesCollection and Presentation of DatafinalYvonne Alonzo De BelenNo ratings yet
- T-Test For Uncorrelated Samples: Presented By: Mark Nelson Adrian Dela Cruz Kim David A. AbuqueDocument13 pagesT-Test For Uncorrelated Samples: Presented By: Mark Nelson Adrian Dela Cruz Kim David A. AbuqueNel zyNo ratings yet
- Presentation Mbs712 08Document43 pagesPresentation Mbs712 08Lizel MorcillaNo ratings yet
- Unit VDocument93 pagesUnit VShay ShayNo ratings yet
- Saghar 8612-2Document22 pagesSaghar 8612-2Anila zafarNo ratings yet
- Summary SPSS BramDocument39 pagesSummary SPSS BramSuzan van den WinkelNo ratings yet
- Unit-4 Hypothesis Testing F T Z Chi TestDocument17 pagesUnit-4 Hypothesis Testing F T Z Chi TestVipin SinghNo ratings yet
- Summary SPSS BramDocument39 pagesSummary SPSS BramSuzan van den WinkelNo ratings yet
- Allama Iqbal Open University Islamabad: Muhammad AshrafDocument25 pagesAllama Iqbal Open University Islamabad: Muhammad AshrafHafiz M MudassirNo ratings yet
- Identifying The Barriers Affecting Quality in Maintenance Within Manufacturing OrganisationDocument260 pagesIdentifying The Barriers Affecting Quality in Maintenance Within Manufacturing OrganisationGyogi MitsutaNo ratings yet
- Ankit Soni: Education Personal InfoDocument1 pageAnkit Soni: Education Personal InfoMd Asif AlamNo ratings yet
- Bba ProjectDocument36 pagesBba ProjectShubham TrivediNo ratings yet
- 8 Normal DistributionDocument7 pages8 Normal DistributionSudibyo GunawanNo ratings yet
- Effect of Sports Participation On Social Development in Children Ages 6-14Document4 pagesEffect of Sports Participation On Social Development in Children Ages 6-14estradahoneyrheynNo ratings yet
- Global ChellengesDocument15 pagesGlobal ChellengesrafiqqaisNo ratings yet
- Students' Perception Towards Financial Literacy and Saving BehaviourDocument9 pagesStudents' Perception Towards Financial Literacy and Saving BehaviourAirish MacamNo ratings yet
- Roller Coaster Project 16Document13 pagesRoller Coaster Project 16api-320383606No ratings yet
- Contracts, Delays and Claims With Primavera P6Document2 pagesContracts, Delays and Claims With Primavera P6Muhammad Abdul Wajid RaiNo ratings yet
- Highland Park Water Crisis InfoDocument3 pagesHighland Park Water Crisis InfoAnonymous rkHJ3LzoBNo ratings yet
- Functional Nature of The Philosophical CategoriesDocument239 pagesFunctional Nature of The Philosophical CategoriestTTNo ratings yet
- Get Your ZZZsDocument1 pageGet Your ZZZsThe State NewspaperNo ratings yet
- Cash Flow Management in The Contemporary Ways of CDocument5 pagesCash Flow Management in The Contemporary Ways of CInes MiladiNo ratings yet
- Credit Risk Modelling Literature ReviewDocument5 pagesCredit Risk Modelling Literature Reviewea3h1c1p100% (1)
- Life Cycle Assessment of A Solar Thermal Collector: Sensitivity Analysis, Energy and Environmental BalancesDocument22 pagesLife Cycle Assessment of A Solar Thermal Collector: Sensitivity Analysis, Energy and Environmental Balancesjuan ceronNo ratings yet
- Harding 2004 Losing Our CoolDocument22 pagesHarding 2004 Losing Our CoolDaniel OliveiraNo ratings yet
- GADHALUNDDocument26 pagesGADHALUNDManoj SinhaNo ratings yet
- Leadership NotesDocument3 pagesLeadership NotesNaeem Ud DinNo ratings yet
- Total FixDocument132 pagesTotal FixNursalinaNo ratings yet
- Hockey Hypothesis Test PaperDocument2 pagesHockey Hypothesis Test Paperapi-345354701No ratings yet
- POL9Document39 pagesPOL9Mehmet RıfatNo ratings yet