You might also like
- Java: Advanced Guide to Programming Code with Java: Java Computer Programming, #4From EverandJava: Advanced Guide to Programming Code with Java: Java Computer Programming, #4No ratings yet
- Cloud Computing Unit 3Document21 pagesCloud Computing Unit 3kejagoNo ratings yet
- Coretools Reference PDFDocument1,918 pagesCoretools Reference PDFbrk_318100% (1)
- Recursive Least-Squares FIR Adaptive Filter - MATLAB AdaptfiltDocument3 pagesRecursive Least-Squares FIR Adaptive Filter - MATLAB AdaptfiltdialauchennaNo ratings yet
- FilteredspeakertoolkitDocument27 pagesFilteredspeakertoolkitapi-239074172No ratings yet
- VB Unit3 AssignmentDocument12 pagesVB Unit3 AssignmentMehul PatelNo ratings yet
- C Language Interview QuestionsDocument38 pagesC Language Interview QuestionsMd Suhas100% (1)
- Working With TextDocument19 pagesWorking With Textapi-3792621No ratings yet
- 3.11. Java Standard Tag Library (JSTL) : Internet Programming With Java CourseDocument22 pages3.11. Java Standard Tag Library (JSTL) : Internet Programming With Java CourseAlex NbNo ratings yet
- 6.4. Building Display Filter ExpressionsDocument8 pages6.4. Building Display Filter ExpressionsalaritooNo ratings yet
- Phpexcel Autofilter Reference: Author: DateDocument20 pagesPhpexcel Autofilter Reference: Author: DateMaria Ignacia Jofre ValladaresNo ratings yet
- Unit - 02Document70 pagesUnit - 02Bhavya ParikhNo ratings yet
- Topic Content Search: Patni ConfidentialDocument10 pagesTopic Content Search: Patni ConfidentialRaghav KonidenaNo ratings yet
- 15 Runtime EnvironmentsDocument8 pages15 Runtime EnvironmentsSrini VasNo ratings yet
- Project 2Document4 pagesProject 2headgoonNo ratings yet
- C LangDocument32 pagesC LangHARESHNo ratings yet
- 4130-Rc032-010d-Hibernate Search 0 1Document6 pages4130-Rc032-010d-Hibernate Search 0 1AndreiNo ratings yet
- Inbound 2696445817745910253Document10 pagesInbound 2696445817745910253kristyllemaebNo ratings yet
- Exercises: What Are Regular Expressions?Document2 pagesExercises: What Are Regular Expressions?marco rossiNo ratings yet
- BaanDocument3 pagesBaanrforrajeshNo ratings yet
- Cfmesh - Short IntroductionDocument7 pagesCfmesh - Short Introductiongego477No ratings yet
- Differential EvolutionDocument11 pagesDifferential EvolutionDuško TovilovićNo ratings yet
- 01 - Initialization ParametersDocument11 pages01 - Initialization ParameterstolukesNo ratings yet
- Ab InitioDocument4 pagesAb Initiokavitha221No ratings yet
- Journal Pone 0244471 s001Document7 pagesJournal Pone 0244471 s001raja sekhara reddy ravuriNo ratings yet
- 1.what Does Static Variable Mean? Ans: StaticDocument3 pages1.what Does Static Variable Mean? Ans: Staticrupesh310rakesh100% (1)
- SigmaInfoSolution - Hussain Akhtar WahidDocument31 pagesSigmaInfoSolution - Hussain Akhtar WahidHussain Akhtar WahidNo ratings yet
- Designing B TEX Styles: 5 Bibliography-Style HackingDocument10 pagesDesigning B TEX Styles: 5 Bibliography-Style HackingNewbie ShyNo ratings yet
- $RJZCT1VDocument2,057 pages$RJZCT1VLorena CabreraNo ratings yet
- Abinitio ComponentsDocument10 pagesAbinitio Componentssai.abinitio99No ratings yet
- R Random Forest GuideDocument8 pagesR Random Forest GuideOrangeBoscoNo ratings yet
- Ars 8100 FTSDocument20 pagesArs 8100 FTSJesús Belda NetoNo ratings yet
- C Interview Questions and AnswersDocument9 pagesC Interview Questions and Answersmanohar1310No ratings yet
- SV 4 Variables Database ENUDocument72 pagesSV 4 Variables Database ENUspctinNo ratings yet
- Ab-Initio Interview QuesDocument39 pagesAb-Initio Interview Queshem77750% (2)
- Ab Initio Faqs - v03Document8 pagesAb Initio Faqs - v03giridhar_007No ratings yet
- Meta ArgumentsDocument3 pagesMeta Argumentskunta.srujan5No ratings yet
- Resume DemoDocument9 pagesResume DemoNeha VermaNo ratings yet
- QuestionsDocument5 pagesQuestionsRavi ChythanyaNo ratings yet
- Bloom Filters and Their ApplicationsDocument5 pagesBloom Filters and Their Applicationsanon_268252666No ratings yet
- Les04 LimitingAndGroupingDataDocument43 pagesLes04 LimitingAndGroupingDataVõ Lê Quy NhơnNo ratings yet
- Oracle Explain Plans EXPLAINEDDocument35 pagesOracle Explain Plans EXPLAINEDgerharda9867100% (1)
- Oracle Forms QuesDocument13 pagesOracle Forms QuesSubhamoy RoyNo ratings yet
- Ab Initio Interview QuestionsDocument6 pagesAb Initio Interview Questionskamnagarg87No ratings yet
- Programming Notes Unit 2Document5 pagesProgramming Notes Unit 2Kunal BhaiNo ratings yet
- Extents in OracleDocument3 pagesExtents in OracleMayur N MalviyaNo ratings yet
- Erlang - Parsetools-1.4Document16 pagesErlang - Parsetools-1.4rodrigoNo ratings yet
- Analysing Genome Alignments With GubbinsDocument10 pagesAnalysing Genome Alignments With Gubbinscesar JuniorNo ratings yet
- XGBoost Parameters - Xgboost 1.5.0-Dev Documentation (Dragged) 2Document2 pagesXGBoost Parameters - Xgboost 1.5.0-Dev Documentation (Dragged) 2siper34606No ratings yet
- Spring and Spring Boot Related Interview QuestionsDocument5 pagesSpring and Spring Boot Related Interview Questionstorrent downloaderNo ratings yet
- Excel 2007VBADocument108 pagesExcel 2007VBAjiguparmar1516No ratings yet
- Distribución Probab NormalDocument2 pagesDistribución Probab NormalDeyver Jandwer Chavez CordovaNo ratings yet
- BigData - Course ContentDocument5 pagesBigData - Course ContentkumarNo ratings yet
- S. No. Particulars Applicability RemarksDocument2 pagesS. No. Particulars Applicability RemarkskumarNo ratings yet
- Career Precis:: A Succinct Competence Profile of Pavan Kumar KattaDocument13 pagesCareer Precis:: A Succinct Competence Profile of Pavan Kumar KattakumarNo ratings yet
- Course Content - SparkScalaDocument1 pageCourse Content - SparkScalakumarNo ratings yet
- Lecture 23: Pig: Making Hadoop Easy (Slides Provided By: Alan Gates, Yahoo!Research)Document22 pagesLecture 23: Pig: Making Hadoop Easy (Slides Provided By: Alan Gates, Yahoo!Research)kumarNo ratings yet
- Advanced Pig Programming 2:30-3:30pmDocument52 pagesAdvanced Pig Programming 2:30-3:30pmkumarNo ratings yet
- FS Jecintha-Paulin - VincentDocument2 pagesFS Jecintha-Paulin - VincentkumarNo ratings yet
- FS Jecintha-Paulin - VincentDocument2 pagesFS Jecintha-Paulin - VincentkumarNo ratings yet
- Cs341 HiveDocument30 pagesCs341 HiveShivaprasadNo ratings yet
- 0-Lec10 1 PDFDocument47 pages0-Lec10 1 PDFsureshrockzNo ratings yet
- Hadoop For DummiesDocument67 pagesHadoop For DummiesKiran100% (2)
- Server - Based Work Ow Engine: OozieDocument25 pagesServer - Based Work Ow Engine: OoziekumarNo ratings yet
- Import Org - Apache.Hadoop - Filecache.DistributedcacheDocument2 pagesImport Org - Apache.Hadoop - Filecache.DistributedcachekumarNo ratings yet
- HIVE - ImpalaDocument1 pageHIVE - ImpalakumarNo ratings yet
- TOGAF 9.2 OverviewDocument16 pagesTOGAF 9.2 Overviewcris100% (1)
- Iterator Enumeraton: Concurrentmodificationexception Fail Safe - Don'T Throw ExceptionDocument2 pagesIterator Enumeraton: Concurrentmodificationexception Fail Safe - Don'T Throw ExceptionkumarNo ratings yet
- An Introduction To The Togaf Standard, Version 9.2: A White Paper byDocument22 pagesAn Introduction To The Togaf Standard, Version 9.2: A White Paper byKAYRA272530No ratings yet
- Logging in Hive: Hive - Root.logger WARN, DRFA Hive - Log.dir /TMP/$ (User - Name) Hive - Log.file Hive - Log Log4j.threshhold WARNDocument3 pagesLogging in Hive: Hive - Root.logger WARN, DRFA Hive - Log.dir /TMP/$ (User - Name) Hive - Log.file Hive - Log Log4j.threshhold WARNkumarNo ratings yet
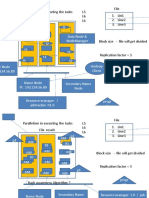
- Lin1 2. Line2 3. Line3 Parallelism in Executing The Tasks File L5 L6 L6Document2 pagesLin1 2. Line2 3. Line3 Parallelism in Executing The Tasks File L5 L6 L6kumarNo ratings yet
- Text Evaluate (Text STR, Stripchars) (: Class X Extens Uds PublicDocument1 pageText Evaluate (Text STR, Stripchars) (: Class X Extens Uds PublickumarNo ratings yet
- The Architecture Development Method: Personal PDF EditionDocument18 pagesThe Architecture Development Method: Personal PDF Editionkumar100% (1)
- Technology ArchitectureDocument1 pageTechnology ArchitecturekumarNo ratings yet
- Togaf 9.2 - RecapDocument7 pagesTogaf 9.2 - RecapkumarNo ratings yet
- Bank Account Opening ProcessDocument1 pageBank Account Opening ProcesskumarNo ratings yet
- Application ArchitectureDocument1 pageApplication ArchitecturekumarNo ratings yet
- Business Value AssessmentDocument1 pageBusiness Value AssessmentkumarNo ratings yet
- Target Architecture Eliminated Services Baseline ArchitectureDocument1 pageTarget Architecture Eliminated Services Baseline ArchitecturekumarNo ratings yet
- Data ArchitectureDocument1 pageData ArchitecturekumarNo ratings yet
- Important Question For DBMSDocument34 pagesImportant Question For DBMSpreet patelNo ratings yet
- Learn SQL - Multiple Tables Cheatsheet - CodecademyDocument2 pagesLearn SQL - Multiple Tables Cheatsheet - Codecademykartik8586No ratings yet
- Conductor LogDocument17 pagesConductor LogSai Siva RohithNo ratings yet
- Oracle AssignmentDocument31 pagesOracle AssignmentComfort JohnsonNo ratings yet
- Big Data EssentialsDocument25 pagesBig Data EssentialsSanthosh VinayakNo ratings yet
- Introduction To Structured Query Language (SQL) : E. F. CoddDocument32 pagesIntroduction To Structured Query Language (SQL) : E. F. CoddBhanvi VermaNo ratings yet
- MS SQL Server - Transact-SQL Topics: IF A Condition Is TrueDocument14 pagesMS SQL Server - Transact-SQL Topics: IF A Condition Is TruevkscribdindNo ratings yet
- Lecture 02Document20 pagesLecture 02Islam SaleemNo ratings yet
- Databases: Starting Out With Java: From Control Structures Through Objects Fifth EditionDocument70 pagesDatabases: Starting Out With Java: From Control Structures Through Objects Fifth EditionAna Da SilvaNo ratings yet
- Loca DgfdgdfgfdglhostDocument193 pagesLoca DgfdgdfgfdglhostsustachaNo ratings yet
- Unit 1 Understanding Database System - Part 15 - Normalization - 1 NF and Functional DependencyDocument12 pagesUnit 1 Understanding Database System - Part 15 - Normalization - 1 NF and Functional DependencyAsmatullah KhanNo ratings yet
- Wendy Afreza (LinkedinIs)Document4 pagesWendy Afreza (LinkedinIs)muhyukholisNo ratings yet
- Website: VCE To PDF Converter: Facebook: Twitter:: Number: 1z0-083 Passing Score: 800 Time Limit: 120 MinDocument28 pagesWebsite: VCE To PDF Converter: Facebook: Twitter:: Number: 1z0-083 Passing Score: 800 Time Limit: 120 MinDenazareth JesusNo ratings yet
- Db2 For Z - OS - Application Programming WorkshopDocument2 pagesDb2 For Z - OS - Application Programming WorkshopMarco Antonio AraujoNo ratings yet
- 12 C AdminDocument73 pages12 C AdminSurapong Naowasate0% (1)
- RH 302Document3 pagesRH 302mitrasamrat20026085No ratings yet
- Database Solutions: OracleDocument20 pagesDatabase Solutions: OracleDinu ChackoNo ratings yet
- An Efficient Pharse Based Pattern Taxonomy Deploying Method For Text Document MiningDocument9 pagesAn Efficient Pharse Based Pattern Taxonomy Deploying Method For Text Document MiningEditor IJTSRDNo ratings yet
- Fact Sheets - Data DirectorDocument2 pagesFact Sheets - Data DirectorthisisonlygoingtobeatestNo ratings yet
- 4 (B) - Data Preprocessing and VisualizationDocument6 pages4 (B) - Data Preprocessing and VisualizationSukhpreet SinghNo ratings yet
- MCQ Type QuestionsDocument24 pagesMCQ Type QuestionsGuruprasad VijayakumarNo ratings yet
- Fundamentals of Apache Sqoop NotesDocument66 pagesFundamentals of Apache Sqoop Notesparamreddy2000No ratings yet
- Lab 1 Introduction To SQL Tools (Xampp, MySQL, PHPMyAdmin) and Data Defination Language (CREATE)Document32 pagesLab 1 Introduction To SQL Tools (Xampp, MySQL, PHPMyAdmin) and Data Defination Language (CREATE)Misbah UllahNo ratings yet
- Data Visualization and HadoopDocument34 pagesData Visualization and Hadooptoon townNo ratings yet
- Query Builder OverviewDocument13 pagesQuery Builder Overview44452555No ratings yet
- DBMS ProjectDocument14 pagesDBMS ProjectNishant GaonkarNo ratings yet
- SAP Sybase ASE Warm Standby Database Using Replication Server - Database TutorialsDocument7 pagesSAP Sybase ASE Warm Standby Database Using Replication Server - Database TutorialsivanNo ratings yet
- Unit 18 - Data Types and OrganizationDocument16 pagesUnit 18 - Data Types and OrganizationCLARA D SOUZA THOMASNo ratings yet
- Backup Related IssuesDocument5 pagesBackup Related IssuesghanshyamkhetanNo ratings yet