You might also like
- Pig & Pig Optimizations: Thejas Nair Dev in Pig Team at Yahoo! Apache Pig PMC MemberDocument23 pagesPig & Pig Optimizations: Thejas Nair Dev in Pig Team at Yahoo! Apache Pig PMC MemberthejasmnNo ratings yet
- HadoopDocument51 pagesHadoopRavitej TadinadaNo ratings yet
- 6 - Simple WordcountDocument2 pages6 - Simple WordcountXavier TxANo ratings yet
- Hadoop Configuration and Single Node SetupDocument61 pagesHadoop Configuration and Single Node SetupParthNo ratings yet
- Apasoft BigData Practices MapReduce JobDocument3 pagesApasoft BigData Practices MapReduce JobChristiam NiñoNo ratings yet
- ADA Lab ManualDocument34 pagesADA Lab Manualnalluri_08No ratings yet
- MapReduce ExampleDocument3 pagesMapReduce ExampleRavi ChanderNo ratings yet
- Exp 4 Word CountDocument4 pagesExp 4 Word Countmunish kumar agarwalNo ratings yet
- BDA3Document7 pagesBDA3nikithakatta0No ratings yet
- Import Import Import Import Import Import Import Import Public Class Extends ImplementsDocument7 pagesImport Import Import Import Import Import Import Import Public Class Extends ImplementsSARAVANANNo ratings yet
- Bda Final 11janDocument7 pagesBda Final 11janG dileep KumarNo ratings yet
- Big Data Word Count MapReduce ExampleDocument6 pagesBig Data Word Count MapReduce ExampleJajang NurjamanNo ratings yet
- WordcountDocument3 pagesWordcount21020279 Trần Diệu AnhNo ratings yet
- WordCount Program Hadoop Task 2Document7 pagesWordCount Program Hadoop Task 220261A6757 VIJAYAGIRI ANIL KUMARNo ratings yet
- Web-Scale Data Processing: Christopher Olston and Many OthersDocument32 pagesWeb-Scale Data Processing: Christopher Olston and Many OthersSaid LoboNo ratings yet
- BDA Unit 4 NotesDocument20 pagesBDA Unit 4 NotesduraisamyNo ratings yet
- Hadoop Training in HyderabadDocument49 pagesHadoop Training in HyderabadkellytechnologiesNo ratings yet
- BDALab Assn4Document9 pagesBDALab Assn4Deepti AgrawalNo ratings yet
- BDA LabManualDocument20 pagesBDA LabManualposprojectzNo ratings yet
- Lab ManualDocument86 pagesLab Manualpthuynh709No ratings yet
- Big DataDocument25 pagesBig DataAnu GraphicsNo ratings yet
- BDA Lab 8 ManualDocument7 pagesBDA Lab 8 ManualMydah NasirNo ratings yet
- Import Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsDocument6 pagesImport Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsSARAVANANNo ratings yet
- Pyspark-1 6 1Document32 pagesPyspark-1 6 1Matthew ReachNo ratings yet
- BDF Lab1Document6 pagesBDF Lab1shaliniiiiNo ratings yet
- BDALab Assn4Document9 pagesBDALab Assn4Deepti AgrawalNo ratings yet
- Develop Simple MapReduce WordCountDocument22 pagesDevelop Simple MapReduce WordCountKaushal PrajapatiNo ratings yet
- Hadoop Matrix MultiplicationDocument1 pageHadoop Matrix MultiplicationMisson CondorNo ratings yet
- CS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011Document13 pagesCS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011smitanair143No ratings yet
- Analyzing The Data With HadoopDocument13 pagesAnalyzing The Data With HadoopVyshnavi ThottempudiNo ratings yet
- Hadoop and Map ReduceDocument27 pagesHadoop and Map Reducearshpreetmundra14No ratings yet
- Assignment 2-033Document13 pagesAssignment 2-033DHARSHANA C PNo ratings yet
- Map reduceDocument4 pagesMap reducechetanruparel07awsNo ratings yet
- To Count Using Map and Reduce Program: Wordcount - JavaDocument2 pagesTo Count Using Map and Reduce Program: Wordcount - JavaRamya DeviNo ratings yet
- Codigo HaddopDocument3 pagesCodigo HaddopLiliana Munar MuñozNo ratings yet
- Cloudera Academic Partnership 4 PDFDocument38 pagesCloudera Academic Partnership 4 PDFEL MAMOUN ABDELLAHNo ratings yet
- Tutorial-Counting Words in File (S) Using Mapreduce: PrerequisitesDocument11 pagesTutorial-Counting Words in File (S) Using Mapreduce: PrerequisitessaiconzeNo ratings yet
- Word Count Program With MapReduce and JavaDocument7 pagesWord Count Program With MapReduce and JavachetnaNo ratings yet
- PalakDocument10 pagesPalakDolly MehraNo ratings yet
- BDT Lab ManualDocument48 pagesBDT Lab ManualVishnu Vardhan HNo ratings yet
- Map ReduceDocument3 pagesMap ReduceRiya JanaNo ratings yet
- Java CustomWritablesDocument6 pagesJava CustomWritablesPrem SosaNo ratings yet
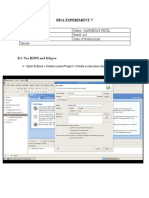
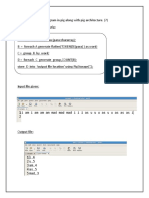
- Bda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeDocument8 pagesBda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeAlkaNo ratings yet
- Hadoop Administrator Training - Lab Hand BookDocument12 pagesHadoop Administrator Training - Lab Hand BookdebkrcNo ratings yet
- Word CountDocument3 pagesWord Countniharika sunkaraNo ratings yet
- Hadoop Streaming Hadoop Pipes Swig: 4 Inputs and OutputsDocument1 pageHadoop Streaming Hadoop Pipes Swig: 4 Inputs and Outputsp001No ratings yet
- HADOOP AND BIG DATA - FinalDocument26 pagesHADOOP AND BIG DATA - FinalDeeq HuseenNo ratings yet
- Run WordcountDocument3 pagesRun WordcountKhushi PatilNo ratings yet
- Reactphp For Beginners SampleDocument15 pagesReactphp For Beginners SampleĐỗHuyHoàngNo ratings yet
- Setting Up Eclipse:: Codelab 1 Introduction To The Hadoop Environment (Version 0.17.0)Document9 pagesSetting Up Eclipse:: Codelab 1 Introduction To The Hadoop Environment (Version 0.17.0)K V D SagarNo ratings yet
- Big Data - ASSIGNMENT 2Document15 pagesBig Data - ASSIGNMENT 2DHARSHANA C PNo ratings yet
- Introduction To Hadoop - Part Two: 1 Hadoop and Comma Separated Values (CSV) Files 1Document38 pagesIntroduction To Hadoop - Part Two: 1 Hadoop and Comma Separated Values (CSV) Files 1Sadikshya khanalNo ratings yet
- Spring ORM Using JavaConfigAndMavenDocument12 pagesSpring ORM Using JavaConfigAndMavenSurendraNo ratings yet
- Default - Parallel: You Can Set The Number of Reducers For A Map Job by Passing Any Whole Number As ADocument6 pagesDefault - Parallel: You Can Set The Number of Reducers For A Map Job by Passing Any Whole Number As AVijay YenchilwarNo ratings yet
- MapReduce Word Count ProgramDocument6 pagesMapReduce Word Count ProgramshaliniiiiNo ratings yet
- Installation of Apache Hadoop 2. Word Count ProgramDocument25 pagesInstallation of Apache Hadoop 2. Word Count Programnecn cse-b 2nd-yearNo ratings yet
- UntitledDocument39 pagesUntitledSai HareenNo ratings yet
- Prerequisites: Single Node Setup Cluster SetupDocument5 pagesPrerequisites: Single Node Setup Cluster Setupmartha quingaNo ratings yet
- Java Package Mastery: 100 Knock Series - Master Java in One Hour, 2024 EditionFrom EverandJava Package Mastery: 100 Knock Series - Master Java in One Hour, 2024 EditionNo ratings yet
- A Succinct Competence Profile of an Experienced Data Analytics ProfessionalDocument13 pagesA Succinct Competence Profile of an Experienced Data Analytics ProfessionalkumarNo ratings yet
- BigData - Course ContentDocument5 pagesBigData - Course ContentkumarNo ratings yet
- Cs341 HiveDocument30 pagesCs341 HiveShivaprasadNo ratings yet
- Advanced Pig Programming 2:30-3:30pmDocument52 pagesAdvanced Pig Programming 2:30-3:30pmkumarNo ratings yet
- FS Jecintha-Paulin - VincentDocument2 pagesFS Jecintha-Paulin - VincentkumarNo ratings yet
- Course Content - SparkScalaDocument1 pageCourse Content - SparkScalakumarNo ratings yet
- Distribución Probab NormalDocument2 pagesDistribución Probab NormalDeyver Jandwer Chavez CordovaNo ratings yet
- S. No. Particulars Applicability RemarksDocument2 pagesS. No. Particulars Applicability RemarkskumarNo ratings yet
- 0-Lec10 1 PDFDocument47 pages0-Lec10 1 PDFsureshrockzNo ratings yet
- Hadoop For DummiesDocument67 pagesHadoop For DummiesKiran100% (2)
- Server - Based Work Ow Engine: OozieDocument25 pagesServer - Based Work Ow Engine: OoziekumarNo ratings yet
- Iterator Enumeraton: Concurrentmodificationexception Fail Safe - Don'T Throw ExceptionDocument2 pagesIterator Enumeraton: Concurrentmodificationexception Fail Safe - Don'T Throw ExceptionkumarNo ratings yet
- FS Jecintha-Paulin - VincentDocument2 pagesFS Jecintha-Paulin - VincentkumarNo ratings yet
- HIVE - ImpalaDocument1 pageHIVE - ImpalakumarNo ratings yet
- Import Org - Apache.Hadoop - Filecache.DistributedcacheDocument2 pagesImport Org - Apache.Hadoop - Filecache.DistributedcachekumarNo ratings yet
- The Key Components of Hbase Are Zookeeper, Regionserver, Region, Catalog Tables and Hbase MasterDocument5 pagesThe Key Components of Hbase Are Zookeeper, Regionserver, Region, Catalog Tables and Hbase MasterkumarNo ratings yet
- An Introduction To The Togaf Standard, Version 9.2: A White Paper byDocument22 pagesAn Introduction To The Togaf Standard, Version 9.2: A White Paper byKAYRA272530No ratings yet
- The Architecture Development Method: Personal PDF EditionDocument18 pagesThe Architecture Development Method: Personal PDF Editionkumar100% (1)
- Application ArchitectureDocument1 pageApplication ArchitecturekumarNo ratings yet
- Text Evaluate (Text STR, Stripchars) (: Class X Extens Uds PublicDocument1 pageText Evaluate (Text STR, Stripchars) (: Class X Extens Uds PublickumarNo ratings yet
- Logging in Hive: Hive - Root.logger WARN, DRFA Hive - Log.dir /TMP/$ (User - Name) Hive - Log.file Hive - Log Log4j.threshhold WARNDocument3 pagesLogging in Hive: Hive - Root.logger WARN, DRFA Hive - Log.dir /TMP/$ (User - Name) Hive - Log.file Hive - Log Log4j.threshhold WARNkumarNo ratings yet
- Lin1 2. Line2 3. Line3 Parallelism in Executing The Tasks File L5 L6 L6Document2 pagesLin1 2. Line2 3. Line3 Parallelism in Executing The Tasks File L5 L6 L6kumarNo ratings yet
- TOGAF 9.2 OverviewDocument16 pagesTOGAF 9.2 Overviewcris100% (1)
- Technology ArchitectureDocument1 pageTechnology ArchitecturekumarNo ratings yet
- Data ArchitectureDocument1 pageData ArchitecturekumarNo ratings yet
- Target Architecture Eliminated Services Baseline ArchitectureDocument1 pageTarget Architecture Eliminated Services Baseline ArchitecturekumarNo ratings yet
- Bank Account Opening ProcessDocument1 pageBank Account Opening ProcesskumarNo ratings yet
- Togaf 9.2 - RecapDocument7 pagesTogaf 9.2 - RecapkumarNo ratings yet
- Business Value AssessmentDocument1 pageBusiness Value AssessmentkumarNo ratings yet
- Sony CorporationDocument9 pagesSony CorporationSachin RaoNo ratings yet
- SC500 Programming ManualDocument165 pagesSC500 Programming ManualCAANo ratings yet
- C++ Functions Chapter SummaryDocument23 pagesC++ Functions Chapter SummaryGeethaa MohanNo ratings yet
- Java Jakarta Ee App Server CheatsheetDocument1 pageJava Jakarta Ee App Server CheatsheetKarol BaranNo ratings yet
- Life Cycle Cost Analysis HandbookDocument35 pagesLife Cycle Cost Analysis HandbookAlemayehu DargeNo ratings yet
- Best Practices For Journalists On Facebook: by Vadim Lavrusik, Journalism Program Manager at FacebookDocument15 pagesBest Practices For Journalists On Facebook: by Vadim Lavrusik, Journalism Program Manager at FacebookArlan PratamaNo ratings yet
- 5 1 2Document5 pages5 1 2api-196541959No ratings yet
- 1.1 Solution PDFDocument165 pages1.1 Solution PDFcoolboyasifNo ratings yet
- Actuarial angle symbol package documentationDocument11 pagesActuarial angle symbol package documentationVicente JorgeNo ratings yet
- TTRA PC Software Log Rev 13.8Document4 pagesTTRA PC Software Log Rev 13.8Hữu Thắng Ngô100% (1)
- Decision TREEDocument3 pagesDecision TREEWHITE YT100% (1)
- Use Visual MODFLOW to Simulate Groundwater FlowDocument4 pagesUse Visual MODFLOW to Simulate Groundwater FlowAbdul MoeedNo ratings yet
- Approval Sheet 1Document9 pagesApproval Sheet 1Faye AlonzoNo ratings yet
- Long Intl Considerations For Identifying and Analyzing The Critical PathDocument18 pagesLong Intl Considerations For Identifying and Analyzing The Critical PathABDEL RAHMAN BADRANNo ratings yet
- Integrasi KP Medan 2021Document101 pagesIntegrasi KP Medan 2021Aris van RaiserNo ratings yet
- Dyslexia Deep Clustering Using Webcam-Based Eye TrackingDocument9 pagesDyslexia Deep Clustering Using Webcam-Based Eye TrackingIAES IJAINo ratings yet
- Controls & Accessories: Air Conditioning TechnologiesDocument20 pagesControls & Accessories: Air Conditioning TechnologiesSyedimamNo ratings yet
- Understanding the IEC 62056 Standard for Electricity Meter Data ExchangeDocument3 pagesUnderstanding the IEC 62056 Standard for Electricity Meter Data ExchangeThiru93456No ratings yet
- Process Question BankDocument23 pagesProcess Question BankSteven skylerNo ratings yet
- Segmented Pricing: Using Price Fences To Segment Markets and Capture ValueDocument3 pagesSegmented Pricing: Using Price Fences To Segment Markets and Capture ValueEmad RashidNo ratings yet
- CSE 5382 Secure Programming Spring 2015Document5 pagesCSE 5382 Secure Programming Spring 2015hemNo ratings yet
- How To Add Recurring Text To All The Slides in Your PowerPoint PresentationDocument1 pageHow To Add Recurring Text To All The Slides in Your PowerPoint PresentationLuc Dhaerron Dhaenna LucetteNo ratings yet
- Enterprise Item Number Management - v3.5 - 20210122Document42 pagesEnterprise Item Number Management - v3.5 - 20210122Nikola Bojke BojovicNo ratings yet
- AXIS Camera Setup and TroublshootingDocument4 pagesAXIS Camera Setup and TroublshootingShadab QureshiNo ratings yet
- ANSYS TCL TK Legacy Training 2013-02-01Document61 pagesANSYS TCL TK Legacy Training 2013-02-01Sharan AnnapuraNo ratings yet
- Job Description PDFDocument3 pagesJob Description PDFSateNo ratings yet
- FC 301 PDFDocument2 pagesFC 301 PDFChristopherNo ratings yet
- ABAP TrainingDocument132 pagesABAP TrainingAleks KoporgeNo ratings yet
- Fast Lane - RH-RH294 PDFDocument2 pagesFast Lane - RH-RH294 PDFMOHIT JANGIRNo ratings yet
- Fast Track Troubleshooting for UN55ES7500FXZADocument5 pagesFast Track Troubleshooting for UN55ES7500FXZAJeffry Saddoy100% (1)