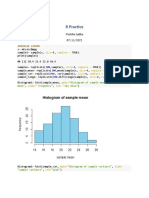
You might also like
- MathsDocument164 pagesMathsKoustavGhosh33% (6)
- Retail Credit ScoringDocument9 pagesRetail Credit ScoringRohan MishraNo ratings yet
- The Dynamics of Mooring Systems PDFDocument141 pagesThe Dynamics of Mooring Systems PDFMirsoNo ratings yet
- Solucionario Introducao A Fisica Estatistica Silvio SalinasDocument91 pagesSolucionario Introducao A Fisica Estatistica Silvio SalinasLucas RibeiroNo ratings yet
- Assignment 1Document12 pagesAssignment 1Andalib ShamsNo ratings yet
- Module 5Document17 pagesModule 5Nacho PuertasNo ratings yet
- Lab10 Regression Evaluation MethodsDocument5 pagesLab10 Regression Evaluation Methodsiffi khanNo ratings yet
- Introduction To Basics of R - Assignment: Log2 (2 5) Log (Exp (1) Exp (2) )Document10 pagesIntroduction To Basics of R - Assignment: Log2 (2 5) Log (Exp (1) Exp (2) )optimistic_harishNo ratings yet
- Using The MarkowitzR PackageDocument12 pagesUsing The MarkowitzR PackageAlmighty59No ratings yet
- R Studio Practicals-1Document29 pagesR Studio Practicals-1rajshukla7748No ratings yet
- Statistical Inference Project Part 1Document5 pagesStatistical Inference Project Part 1omkar pathareNo ratings yet
- R CommandsDocument18 pagesR CommandsKhizra AmirNo ratings yet
- All All: % (A) Construct Side-By-Side Stem-And-Leaf PlotsDocument34 pagesAll All: % (A) Construct Side-By-Side Stem-And-Leaf PlotsJASHWIN GAUTAMNo ratings yet
- A1Document8 pagesA1DASHPAGALNo ratings yet
- Nthu BacshwDocument8 pagesNthu Bacshw黃淑菱No ratings yet
- Rstudio Study Notes For PA 20181126Document6 pagesRstudio Study Notes For PA 20181126Trong Nghia VuNo ratings yet
- H-311 Linear Regression Analysis With RDocument71 pagesH-311 Linear Regression Analysis With RNat Boltu100% (1)
- Nomor 3 UtsDocument6 pagesNomor 3 UtsNita FerdianaNo ratings yet
- Module V 1Document7 pagesModule V 1Animesh MandalNo ratings yet
- LabNote 3Document3 pagesLabNote 3CHAI TZE ANNNo ratings yet
- Computational Techniques in Statistics: Exercise 1Document5 pagesComputational Techniques in Statistics: Exercise 1وجدان الشداديNo ratings yet
- Control Flow - LoopingDocument18 pagesControl Flow - LoopingNur SyazlianaNo ratings yet
- Genetica CuantitativaDocument120 pagesGenetica CuantitativaAlexis Josue Vallecillo GodoyNo ratings yet
- HW3 張晏壬 R26104047Document11 pagesHW3 張晏壬 R26104047Yen-Jen ChangNo ratings yet
- Cluster Analysis in R TMLDocument5 pagesCluster Analysis in R TMLRajyaLakshmiNo ratings yet
- SetBDocument7 pagesSetBFenil ThummarNo ratings yet
- Programming With R Test 2Document5 pagesProgramming With R Test 2KamranKhan50% (2)
- Module - 4 (R Training) - Basic Stats & ModelingDocument15 pagesModule - 4 (R Training) - Basic Stats & ModelingRohitGahlanNo ratings yet
- Bs at HSW: Victor Omondi 7/27/2021 #Stem Majors ChisquareDocument12 pagesBs at HSW: Victor Omondi 7/27/2021 #Stem Majors ChisquareomondivkeyNo ratings yet
- 20BCE1205 Lab4Document7 pages20BCE1205 Lab4SHUBHAM OJHANo ratings yet
- R AssignmentDocument8 pagesR AssignmentTunaNo ratings yet
- Count Models in JAGSDocument16 pagesCount Models in JAGS18rosa18No ratings yet
- Tarea 1 RDocument6 pagesTarea 1 RAllison MeroNo ratings yet
- SME 1013 Programming For Engineers: ArraysDocument9 pagesSME 1013 Programming For Engineers: Arraysjfl2096No ratings yet
- Assignments Walkthroughs and R Demo: W4290 Statistical Methods in Finance - Spring 2010 - Columbia UniversityDocument38 pagesAssignments Walkthroughs and R Demo: W4290 Statistical Methods in Finance - Spring 2010 - Columbia UniversitytsitNo ratings yet
- 20BCE1205 Lab4Document7 pages20BCE1205 Lab4SHUBHAM OJHANo ratings yet
- Exercise DispersionDocument10 pagesExercise DispersionMohsin AliNo ratings yet
- 7 StatisticsDocument13 pages7 StatisticsNor Hanina90% (10)
- Kickstarter Success PredictionDocument17 pagesKickstarter Success PredictionTianhui XuNo ratings yet
- Variosalgoritmos - Jupyter NotebookDocument9 pagesVariosalgoritmos - Jupyter NotebookPAULO CESAR CALDERON BERMUDO100% (1)
- Lab 3. Linear Regression 230223Document7 pagesLab 3. Linear Regression 230223ruso100% (1)
- ML Practical Journal With WriteupsDocument46 pagesML Practical Journal With Writeupssakshi mishraNo ratings yet
- MATLAB 4 Numerical ComputationsDocument53 pagesMATLAB 4 Numerical ComputationsVASUDEVA NAIDUNo ratings yet
- Welcome To Cmpe140 Final Exam: StudentidDocument21 pagesWelcome To Cmpe140 Final Exam: Studentidtunahan küçükerNo ratings yet
- CH 03Document42 pagesCH 03Xiaoxu WuNo ratings yet
- Statistical Analysis Measure of VariationDocument14 pagesStatistical Analysis Measure of VariationJohn Paul RamosNo ratings yet
- DataframepptuDocument73 pagesDataframepptubrykymaNo ratings yet
- Grid Search For SVMDocument9 pagesGrid Search For SVMkPrasad8No ratings yet
- AFTERMIDCODEDocument12 pagesAFTERMIDCODERamesh DhamiNo ratings yet
- Topic 3 Measures of DispersionDocument5 pagesTopic 3 Measures of DispersionEll VNo ratings yet
- Logistic RegressionDocument10 pagesLogistic RegressionChichi Jnr100% (1)
- Data AnalyticsDocument31 pagesData AnalyticsSandeep TanwarNo ratings yet
- Muthayammal College of Arts and Science Rasipuram: Assignment No - 3Document8 pagesMuthayammal College of Arts and Science Rasipuram: Assignment No - 3Gopi BalakrishnanNo ratings yet
- Introduction To Data Science With R ProgrammingDocument14 pagesIntroduction To Data Science With R ProgrammingVimal KumarNo ratings yet
- R PracticeDocument38 pagesR PracticeyoshitaNo ratings yet
- Fyybsc - CS Sem 1 FMS JournalDocument43 pagesFyybsc - CS Sem 1 FMS Journalhemroid863No ratings yet
- R - (2017) Understanding and Applying Basic Statistical Methods Using R (Wilcox - R - R) (Sols.)Document91 pagesR - (2017) Understanding and Applying Basic Statistical Methods Using R (Wilcox - R - R) (Sols.)David duranNo ratings yet
- Capital GainsDocument8 pagesCapital Gainshariprasanna951No ratings yet
- HW 1 Math 380 R CodeDocument4 pagesHW 1 Math 380 R CodeTyrome MadkinsNo ratings yet
- Homework 2Document14 pagesHomework 2Juan Pablo Madrigal Cianci100% (1)
- DSM 3Document6 pagesDSM 3no0r32200No ratings yet
- Logistic Regression in RDocument19 pagesLogistic Regression in RRenukaNo ratings yet
- JAMB Mathematics Past Questions EduNgr Sample PDFDocument55 pagesJAMB Mathematics Past Questions EduNgr Sample PDFDiya Ali BarnabasNo ratings yet
- Using Drop Down Lists in Your Excel Spreadsheet To Select DataDocument7 pagesUsing Drop Down Lists in Your Excel Spreadsheet To Select DataRatsiam Yai-aroonNo ratings yet
- Rangka Kursus (Course Outline) : (Process Dynamics and Control)Document3 pagesRangka Kursus (Course Outline) : (Process Dynamics and Control)PY YouNo ratings yet
- LSE MA100 Background CheckDocument5 pagesLSE MA100 Background CheckAlternative EgoNo ratings yet
- 9 ChapDocument5 pages9 ChapNandgulabDeshmukhNo ratings yet
- Thèse de David Becerra Sur Le Jeu Du Démineur Et Les AlgorithmesDocument41 pagesThèse de David Becerra Sur Le Jeu Du Démineur Et Les AlgorithmesOUAAAAAAHNo ratings yet
- JEE 2022 - MergedDocument9 pagesJEE 2022 - MergedSwastik PandeyNo ratings yet
- Pre Ap Algebra 1 Pacing CalendarDocument1 pagePre Ap Algebra 1 Pacing CalendarSmita NagNo ratings yet
- CT4145 CT2031 Mechanics of Structures Module Introduction Into Continuum MechanicsDocument80 pagesCT4145 CT2031 Mechanics of Structures Module Introduction Into Continuum MechanicsMarcoNo ratings yet
- Control Systems With ScilabDocument65 pagesControl Systems With ScilabAniruddha KanheNo ratings yet
- Q1: Encircle The Correct Answer For The Following Multiple Choice Questions. (10) 1. 1. 2. 3Document1 pageQ1: Encircle The Correct Answer For The Following Multiple Choice Questions. (10) 1. 1. 2. 3Irfan AliNo ratings yet
- Basic Operations English 76 PDFDocument9 pagesBasic Operations English 76 PDFPuspraj JayswalNo ratings yet
- Common Correlated Effects Estimation For Dynamic Heterogeneous Panels With Non-Stationary Multi-Factor Error StructuresDocument27 pagesCommon Correlated Effects Estimation For Dynamic Heterogeneous Panels With Non-Stationary Multi-Factor Error StructuresLeandro AndradeNo ratings yet
- Universal Volume Bounds in Riemannian ManifoldsDocument34 pagesUniversal Volume Bounds in Riemannian ManifoldsOmaguNo ratings yet
- ESci 110 - N046 - Lesson 8.2 AssessmentDocument12 pagesESci 110 - N046 - Lesson 8.2 AssessmentIvy PerezNo ratings yet
- Math Practice TestDocument12 pagesMath Practice TestJake MoralesNo ratings yet
- Relations and Functions Class 12Document18 pagesRelations and Functions Class 12bandanasabar2006No ratings yet
- HW2 PDFDocument1 pageHW2 PDFymtsangNo ratings yet
- Group Project Report MathDocument23 pagesGroup Project Report MathjajaNo ratings yet
- 3.applications of Fourier TransformDocument24 pages3.applications of Fourier TransformManpreet SinghNo ratings yet
- M23 1st LE Sample, 1st Sem 19-20 (Final Copy) PDFDocument1 pageM23 1st LE Sample, 1st Sem 19-20 (Final Copy) PDFAnonymous nlOXePRBANo ratings yet
- Wednesday 12 June 2019: Statistics S1Document24 pagesWednesday 12 June 2019: Statistics S1Rahyan AshrafNo ratings yet
- Math Answer Key PDFDocument1 pageMath Answer Key PDFAnonymous Tks4fcWLNo ratings yet
- Maths Grade 12 RevisionDocument7 pagesMaths Grade 12 RevisionKamil AliNo ratings yet
- Solomon I QP - C1 OCRDocument3 pagesSolomon I QP - C1 OCRMuhammad MuhammadNo ratings yet
- Certified Data Scientist: Program BrochureDocument14 pagesCertified Data Scientist: Program BrochureAshner NovillaNo ratings yet
- 15 Multiple Choices Simplification A (B+C) Expansion A (B+C) Easy A B C DDocument5 pages15 Multiple Choices Simplification A (B+C) Expansion A (B+C) Easy A B C DMai AnhNo ratings yet