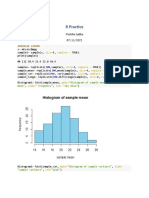
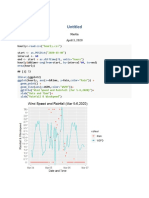
You might also like
- Practica 2 TemperaturaDocument11 pagesPractica 2 TemperaturaJilmeNo ratings yet
- R FourierDocument18 pagesR FourierNUR ARZILAH ISMAILNo ratings yet
- Examen-Regresion MiguelEsparzaDocument9 pagesExamen-Regresion MiguelEsparzamaesparza2307No ratings yet
- Bioestadistica: Clara Carner 2023-05-29Document4 pagesBioestadistica: Clara Carner 2023-05-29Clara CarnerNo ratings yet
- R Code Default Data PDFDocument10 pagesR Code Default Data PDFShubham Wadhwa 23No ratings yet
- 20BCE1205 Lab6Document12 pages20BCE1205 Lab6SHUBHAM OJHANo ratings yet
- R PracticeDocument38 pagesR PracticeyoshitaNo ratings yet
- R Intro STAT5000Document17 pagesR Intro STAT5000vinay kumarNo ratings yet
- R HomeworkDocument13 pagesR HomeworkTesta MestaNo ratings yet
- Final Predictive Vaibhav 2020Document101 pagesFinal Predictive Vaibhav 2020sristi agrawalNo ratings yet
- Panel 2Document26 pagesPanel 2tilfaniNo ratings yet
- R CommandsDocument18 pagesR CommandsKhizra AmirNo ratings yet
- Downloading and Exploring FTS Data R CodeDocument11 pagesDownloading and Exploring FTS Data R CodeBevNo ratings yet
- Modelos Lineales y Modelos Lineales GeneralizadosDocument5 pagesModelos Lineales y Modelos Lineales Generalizadosanita34621No ratings yet
- Nthu BacshwDocument8 pagesNthu Bacshw黃淑菱No ratings yet
- K5 (20) - GLM - PC - B: 1. Logistic RegressionDocument15 pagesK5 (20) - GLM - PC - B: 1. Logistic RegressionKornelija JanušytėNo ratings yet
- StaticsTestDocument6 pagesStaticsTestSOWMIA R 2248056No ratings yet
- Kinh tế lượng code RDocument10 pagesKinh tế lượng code RNgọc Quỳnh Anh NguyễnNo ratings yet
- Entregable1: Leidy Naranjo - Juan Pablo Pelaez 2022-03-17Document7 pagesEntregable1: Leidy Naranjo - Juan Pablo Pelaez 2022-03-17eduardoNo ratings yet
- Name: Reg. No.: Lab Exercise:: Shivam Batra 19BPS1131Document10 pagesName: Reg. No.: Lab Exercise:: Shivam Batra 19BPS1131Shivam Batra100% (1)
- LabNote 3Document3 pagesLabNote 3CHAI TZE ANNNo ratings yet
- Machine LeaarningDocument32 pagesMachine LeaarningLuis Eduardo Calderon CantoNo ratings yet
- Dam CheatsheetDocument4 pagesDam CheatsheetMradulNo ratings yet
- Data Science Comp 2Document13 pagesData Science Comp 2tobiasNo ratings yet
- Home ConstructionDocument8 pagesHome Constructionphatakpriya108No ratings yet
- Taller RDocument37 pagesTaller RHuevo SapeNo ratings yet
- H-311 Linear Regression Analysis With RDocument71 pagesH-311 Linear Regression Analysis With RNat Boltu100% (1)
- Cia DoeDocument2 pagesCia Doeshathriya.narayananNo ratings yet
- Ancova: R MarkdownDocument6 pagesAncova: R Markdownapi-285833118No ratings yet
- Control Flow - LoopingDocument18 pagesControl Flow - LoopingNur SyazlianaNo ratings yet
- Individual Variable Data Analysis: WarningDocument38 pagesIndividual Variable Data Analysis: WarningNikhil YadatiNo ratings yet
- Multiple Linear RegressionDocument14 pagesMultiple Linear RegressionNamdev100% (1)
- Chapter 9 Cox Proportional Hazards: Library (Survival)Document10 pagesChapter 9 Cox Proportional Hazards: Library (Survival)Yosef GUEVARA SALAMANCANo ratings yet
- Image ClassifactionDocument17 pagesImage Classifactionmk10octNo ratings yet
- Shivam Batra (19BPS1131) 21/01/2022: ListDocument5 pagesShivam Batra (19BPS1131) 21/01/2022: ListShivam BatraNo ratings yet
- ch12bt20 GDP-updateDocument15 pagesch12bt20 GDP-updateNguyễn OanhNo ratings yet
- A1Document8 pagesA1DASHPAGALNo ratings yet
- Writing Efficient R CodeDocument5 pagesWriting Efficient R CodeOctavio FloresNo ratings yet
- Ex 10 - Decision Tree With Rpart and Fancy Plot and Cardio DataDocument4 pagesEx 10 - Decision Tree With Rpart and Fancy Plot and Cardio DataNopeNo ratings yet
- PlottingDocument21 pagesPlottingTonyNo ratings yet
- Coding Analisis SpasialDocument9 pagesCoding Analisis SpasialRochmanto_HaniNo ratings yet
- Chemo Mortality AnalysisDocument5 pagesChemo Mortality AnalysisAyu HutamiNo ratings yet
- PCA and FA CommandsDocument13 pagesPCA and FA CommandsNguyễn OanhNo ratings yet
- Clustering On Boston DatasetDocument3 pagesClustering On Boston Datasetanubhav582No ratings yet
- Assignment-1 80501Document6 pagesAssignment-1 80501rishabh7aroraNo ratings yet
- PracticalDocument22 pagesPractical786chetanNo ratings yet
- Practical Machine LearningDocument11 pagesPractical Machine Learningminhajur rahmanNo ratings yet
- 20BCE1205 Lab4Document7 pages20BCE1205 Lab4SHUBHAM OJHANo ratings yet
- Bda AssignDocument15 pagesBda AssignAishwarya BiradarNo ratings yet
- 20BCE1205 Lab4Document7 pages20BCE1205 Lab4SHUBHAM OJHANo ratings yet
- 20BCE1205 Lab3Document9 pages20BCE1205 Lab3SHUBHAM OJHANo ratings yet
- Assignment 11-17-15: Michael Petzold November 19, 2015Document4 pagesAssignment 11-17-15: Michael Petzold November 19, 2015mikey pNo ratings yet
- Lab-9 RMDDocument5 pagesLab-9 RMDMaira SulaimanovaNo ratings yet
- Antlion bs2460Document3 pagesAntlion bs2460calvinleow1205No ratings yet
- STA2050 Assignment 2Document10 pagesSTA2050 Assignment 2gugugagaNo ratings yet
- Kickstarter Success PredictionDocument17 pagesKickstarter Success PredictionTianhui XuNo ratings yet
- MBA19141Document14 pagesMBA19141Ankur TulsyanNo ratings yet
- Count Models in JAGSDocument16 pagesCount Models in JAGS18rosa18No ratings yet
- Shark Tank Deal Prediction - Uudhya - Dec 2019Document16 pagesShark Tank Deal Prediction - Uudhya - Dec 2019usoramaNo ratings yet
- Bs at HSW: Victor Omondi 7/27/2021 #Stem Majors ChisquareDocument12 pagesBs at HSW: Victor Omondi 7/27/2021 #Stem Majors ChisquareomondivkeyNo ratings yet
- How The Capacities and Impacts of Growing Degrees of Ground Automation Can Be Communicated To and Understood by The General PublicDocument6 pagesHow The Capacities and Impacts of Growing Degrees of Ground Automation Can Be Communicated To and Understood by The General PublicomondivkeyNo ratings yet
- Global Sustainability and Biodiversity ConservationDocument3 pagesGlobal Sustainability and Biodiversity ConservationomondivkeyNo ratings yet
- Osteoporosis FinalDocument11 pagesOsteoporosis FinalomondivkeyNo ratings yet
- Sample EssayDocument3 pagesSample EssayomondivkeyNo ratings yet
- Destination Marketing Organization Response (DMO) To COVID-19 Pandemic: New York CityDocument6 pagesDestination Marketing Organization Response (DMO) To COVID-19 Pandemic: New York CityomondivkeyNo ratings yet
- Untitled: Martin April 3, 2020Document3 pagesUntitled: Martin April 3, 2020omondivkeyNo ratings yet
- 974daaaf4a1c333f53d029d9b9aa17b5_78e5d5d94369f2cd630818f4d9ebb80bDocument3 pages974daaaf4a1c333f53d029d9b9aa17b5_78e5d5d94369f2cd630818f4d9ebb80bomondivkeyNo ratings yet
- JG HG J HHGH 76765776Document12 pagesJG HG J HHGH 76765776GlobalStrategyNo ratings yet
- NFLPPG: R MarkdownDocument4 pagesNFLPPG: R MarkdownomondivkeyNo ratings yet
- Principles of Engineering Thermodynamics - SI Version 8th EditionDocument47 pagesPrinciples of Engineering Thermodynamics - SI Version 8th EditionanabNo ratings yet
- Eclipse Ring Planning Guide - Any To AnyDocument8 pagesEclipse Ring Planning Guide - Any To AnyAnsar ShafiiNo ratings yet
- Engine Bearing: Website Email Tel: Fax: 0086-577-86755433 0086-577-86755422Document27 pagesEngine Bearing: Website Email Tel: Fax: 0086-577-86755433 0086-577-86755422Суханов КонстантинNo ratings yet
- Penurunan Waktu Tunggu Operasi Elektif Dengan Membuat Standar Prosedur Operasional Di Rumah Sakit Umum Karsa Husada BatuDocument8 pagesPenurunan Waktu Tunggu Operasi Elektif Dengan Membuat Standar Prosedur Operasional Di Rumah Sakit Umum Karsa Husada BaturirisNo ratings yet
- BAH Series 6000 Manguard - 113534-91Document40 pagesBAH Series 6000 Manguard - 113534-91AhmedNo ratings yet
- Quality Assurance Measures For Procurement of Purchased PartsDocument26 pagesQuality Assurance Measures For Procurement of Purchased Partssakshi patilNo ratings yet
- Stuart Hall - Who Dares, FailsDocument3 pagesStuart Hall - Who Dares, FailsdNo ratings yet
- Homework 3Document4 pagesHomework 3sdphysicsNo ratings yet
- GGFHJDocument1 pageGGFHJanon_791172439No ratings yet
- 5 OPERATIVE Dentistry-Fifth year-FIFTH lect-16-4-2020-FAILURE OF RESTORATIONDocument24 pages5 OPERATIVE Dentistry-Fifth year-FIFTH lect-16-4-2020-FAILURE OF RESTORATIONIna YaNo ratings yet
- MBSImP Assignment RubricDocument3 pagesMBSImP Assignment RubricmahdislpNo ratings yet
- Conditions For Effective Innovation On The MacroDocument3 pagesConditions For Effective Innovation On The MacroWinesha U. Smith100% (2)
- Principles of PaleontologyDocument10 pagesPrinciples of Paleontologyvitrinite50% (2)
- Crafting The Service Environment: Text Book Chapter 10Document25 pagesCrafting The Service Environment: Text Book Chapter 10Sneha DussaramNo ratings yet
- SMPS FundamentalsDocument53 pagesSMPS FundamentalsRahul Gupta100% (2)
- OutputDocument5 pagesOutputCarlos FazNo ratings yet
- STS Module 9Document14 pagesSTS Module 9Claire Jacynth FloroNo ratings yet
- A Simple Guide To Energy Budgets: Number 167 WWW - Curriculum-Press - Co.ukDocument4 pagesA Simple Guide To Energy Budgets: Number 167 WWW - Curriculum-Press - Co.ukKamaria ThomasNo ratings yet
- Contrastive Morphology The Morpheme Is The Smallest Unit of A Language That Has A Binary Nature (That CanDocument6 pagesContrastive Morphology The Morpheme Is The Smallest Unit of A Language That Has A Binary Nature (That CanIrynaNo ratings yet
- GBP Statement: Beatriz Manchado FloresDocument2 pagesGBP Statement: Beatriz Manchado Floresmr.laravelNo ratings yet
- Chap 16Document53 pagesChap 16EveNo ratings yet
- PokeDex ChecklistDocument7 pagesPokeDex ChecklistJosh StrıkeNo ratings yet
- S1-1054/2 10kV Digital Insulation Tester: User ManualDocument24 pagesS1-1054/2 10kV Digital Insulation Tester: User ManualHoracio BobedaNo ratings yet
- PCR TechniqueDocument28 pagesPCR TechniqueSagar Das ChoudhuryNo ratings yet
- Remote Sensing GeologyDocument438 pagesRemote Sensing GeologyStalin Bryan100% (2)
- Instruction Manual FisherDocument20 pagesInstruction Manual FisherPrado_MoisesNo ratings yet
- Triangulation Research PaperDocument3 pagesTriangulation Research PaperCharmaine Montimor OrdonioNo ratings yet
- THESISDocument21 pagesTHESISMell Heiston GensonNo ratings yet
- 2 Unit2Document28 pages2 Unit2BrahimeNo ratings yet
- Solidworks Inspection Data SheetDocument3 pagesSolidworks Inspection Data Sheetradule021No ratings yet