You might also like
- Review of Prognosis Methods for Rolling Element BearingsDocument7 pagesReview of Prognosis Methods for Rolling Element BearingsSindhu KamathNo ratings yet
- Estimation of Remaining Useful Life of Bearings Based On Support Vector RegressionDocument7 pagesEstimation of Remaining Useful Life of Bearings Based On Support Vector RegressionAnonymous OFwyjaMyNo ratings yet
- Mechanical Systems and Signal ProcessingDocument23 pagesMechanical Systems and Signal ProcessingHARIPRASATHNo ratings yet
- Complex system health management using condition monitoring and test dataDocument15 pagesComplex system health management using condition monitoring and test dataচারুলতা নীর সেনNo ratings yet
- Sensors 22 05858 v2Document24 pagesSensors 22 05858 v2RAIZA ARANZAEZ QUINTANANo ratings yet
- A Particle Filtering-Based Approach For Remaining Useful Life Predication of Rolling Element BearingsDocument8 pagesA Particle Filtering-Based Approach For Remaining Useful Life Predication of Rolling Element BearingsPradeep KunduNo ratings yet
- How To Evaluate BoatsDocument14 pagesHow To Evaluate BoatsJuniorJavier Olivo FarreraNo ratings yet
- 1 s2.0 S1877705814033979 MainDocument12 pages1 s2.0 S1877705814033979 Main20bme094No ratings yet
- Machines 10 00927 v2Document15 pagesMachines 10 00927 v2Ariel CespedNo ratings yet
- 1 Applsci-13-07186Document17 pages1 Applsci-13-07186Clovis NetoNo ratings yet
- Measurement: Akhand Rai, Jong-Myon KimDocument11 pagesMeasurement: Akhand Rai, Jong-Myon KimDEEPESH KUMARNo ratings yet
- Classification of Ball Bearing Faults Using Vibro Acoustic Sensor Data FusionDocument9 pagesClassification of Ball Bearing Faults Using Vibro Acoustic Sensor Data FusionHanifNo ratings yet
- BrazilianDocument16 pagesBrazilianNeerajNo ratings yet
- Neurocomputing: P.K. Kankar, Satish C. Sharma, S.P. HarshaDocument8 pagesNeurocomputing: P.K. Kankar, Satish C. Sharma, S.P. Harshaharim_meNo ratings yet
- Soualhi 23769 2Document16 pagesSoualhi 23769 2Max PainNo ratings yet
- Bearing DefectsDocument13 pagesBearing Defectsjoshibec100% (1)
- Novel Method For Rolling Element Bearing Health Assessment-A Tachometer-Lesssynchronously Averaged Envelope Feature Extraction TechniqueDocument15 pagesNovel Method For Rolling Element Bearing Health Assessment-A Tachometer-Lesssynchronously Averaged Envelope Feature Extraction Techniquejun005No ratings yet
- Wind Turbine Condition Monitoring Based On SCADA Data Using Normal Behavior Models Part 1 System DescriptionDocument12 pagesWind Turbine Condition Monitoring Based On SCADA Data Using Normal Behavior Models Part 1 System Descriptionbendiazz3430No ratings yet
- Rotate Vector Reducer Fault Diagnosis Model Based PDFDocument17 pagesRotate Vector Reducer Fault Diagnosis Model Based PDFAishwaryaNo ratings yet
- Remaining Useful Life Prediction of Ball-Bearings Based On High-Frequency Vibration FeaturesDocument12 pagesRemaining Useful Life Prediction of Ball-Bearings Based On High-Frequency Vibration FeaturesangeloNo ratings yet
- Access 2017 2773460Document16 pagesAccess 2017 2773460captain americaNo ratings yet
- Measurement: Changqing Shen, Dong Wang, Fanrang Kong, Peter W. TseDocument14 pagesMeasurement: Changqing Shen, Dong Wang, Fanrang Kong, Peter W. TsePradeep KunduNo ratings yet
- Ijcsa 030306Document13 pagesIjcsa 030306Anonymous lVQ83F8mCNo ratings yet
- Sensors 23 09082Document35 pagesSensors 23 09082Y SNo ratings yet
- Vishal NewDocument5 pagesVishal NewVarasidhi vinay DommetiNo ratings yet
- Estimating Rotor Unbalance From A Single Run-Up and Using Reduced SensorsDocument14 pagesEstimating Rotor Unbalance From A Single Run-Up and Using Reduced SensorsAgustín Erasmo Juárez MartínezNo ratings yet
- 1 s2.0 S0888327016303144 MainDocument14 pages1 s2.0 S0888327016303144 MainDobrescu Morariu MirceaNo ratings yet
- Machines 11 00341Document16 pagesMachines 11 00341Sandro Marcos de GouveiaNo ratings yet
- Sensors: Naive Bayes Bearing Fault Diagnosis Based On Enhanced Independence of DataDocument17 pagesSensors: Naive Bayes Bearing Fault Diagnosis Based On Enhanced Independence of DataSérgio CustódioNo ratings yet
- Preprocessing-Free Gear Fault Diagnosis Using Small Datasets With Deep Convolutional Neural Network-Based Transfer LearningDocument13 pagesPreprocessing-Free Gear Fault Diagnosis Using Small Datasets With Deep Convolutional Neural Network-Based Transfer LearningCesar Vargas ArayaNo ratings yet
- Main PaperDocument13 pagesMain PapermdkNo ratings yet
- Ijnsa 050308Document13 pagesIjnsa 050308AIRCC - IJNSANo ratings yet
- A New Enhanced Feature Extraction Strategy For Bearing Remaining Useful Life EstimationDocument6 pagesA New Enhanced Feature Extraction Strategy For Bearing Remaining Useful Life EstimationPradeep KunduNo ratings yet
- Sciencedirect: Context Driven Remaining Useful Life EstimationDocument5 pagesSciencedirect: Context Driven Remaining Useful Life EstimationBlan JoesNo ratings yet
- 01 Wirtz GearTransmissionMonitoringDocument14 pages01 Wirtz GearTransmissionMonitoringdusan cincarNo ratings yet
- Research ArticleDocument14 pagesResearch Article8c354be21dNo ratings yet
- Mechanical Systems and Signal Processing: R.A. Saeed, A.N. Galybin, V. PopovDocument18 pagesMechanical Systems and Signal Processing: R.A. Saeed, A.N. Galybin, V. PopovDamarla KiranNo ratings yet
- Sensors: A Novel Method For Determining Angular Speed and Acceleration Using Sin-Cos EncodersDocument21 pagesSensors: A Novel Method For Determining Angular Speed and Acceleration Using Sin-Cos EncodersName24122021No ratings yet
- Applmech 04 00020Document15 pagesApplmech 04 00020jose manuel gomez jimenezNo ratings yet
- Frequency Phase Space Empirical Wavelet Transform For Rolling Bearings Fault DiagnosisDocument13 pagesFrequency Phase Space Empirical Wavelet Transform For Rolling Bearings Fault DiagnosisPraveen kumarNo ratings yet
- An Improved Exponential Model For Predicting Remaining Useful Life of Rolling Element BearingsDocument12 pagesAn Improved Exponential Model For Predicting Remaining Useful Life of Rolling Element BearingsPradeep KunduNo ratings yet
- Fault AnalysisDocument10 pagesFault Analysissusheela bhatNo ratings yet
- Fault Diagnosis of Automobile Gearbox Using Artificial Neural NetworkDocument8 pagesFault Diagnosis of Automobile Gearbox Using Artificial Neural NetworkGovindraj ChittapurNo ratings yet
- Gear Fault Diagnosis and Classification Using Data Vibration: October 2017Document10 pagesGear Fault Diagnosis and Classification Using Data Vibration: October 2017Ashwin MahoneyNo ratings yet
- Equipment Operational Reliability Evaluation MethoDocument9 pagesEquipment Operational Reliability Evaluation MethoMi doremiNo ratings yet
- A Comprehensive Prognostics Approach For Predicting Gas Turbine Engine Bearing LifeDocument10 pagesA Comprehensive Prognostics Approach For Predicting Gas Turbine Engine Bearing LifefarismohNo ratings yet
- Study of Inertial Measurement Unit SensorDocument4 pagesStudy of Inertial Measurement Unit SensorĐinh Hữu KiênNo ratings yet
- 2013 01 90411 PDFDocument11 pages2013 01 90411 PDFhurshawNo ratings yet
- Condition Monitoring of Helical Gears Using Automated Selection of Features and Sensors PDFDocument14 pagesCondition Monitoring of Helical Gears Using Automated Selection of Features and Sensors PDFPradeep KunduNo ratings yet
- A Deep Learning Model For Remaining UsefDocument16 pagesA Deep Learning Model For Remaining UsefSana NNo ratings yet
- Applied Sciences: Early Warning Signals For Bearing Failure Using Detrended Fluctuation AnalysisDocument16 pagesApplied Sciences: Early Warning Signals For Bearing Failure Using Detrended Fluctuation AnalysisEQ GMNo ratings yet
- An Algorithm For Fault Node Recovery of Wireless Sensor NetworkDocument4 pagesAn Algorithm For Fault Node Recovery of Wireless Sensor NetworkInternational Journal of Research in Engineering and TechnologyNo ratings yet
- 158 Ijmperdjun2019158Document14 pages158 Ijmperdjun2019158TJPRC PublicationsNo ratings yet
- Obteniendo La Vida Útil de Un ComponenteDocument11 pagesObteniendo La Vida Útil de Un ComponenteAnthony Alexander Alarcón MorenoNo ratings yet
- J Measurement 2017 04 011Document9 pagesJ Measurement 2017 04 011Rushikesh SadavarteNo ratings yet
- 1 s2.0 S0263224121002402 MainDocument19 pages1 s2.0 S0263224121002402 Mainvikas sharmaNo ratings yet
- 02chapter1 PDFDocument9 pages02chapter1 PDFmghgolNo ratings yet
- Materials: Prediction of Tool Wear Using Artificial Neural Networks During Turning of Hardened SteelDocument15 pagesMaterials: Prediction of Tool Wear Using Artificial Neural Networks During Turning of Hardened Steelrub786No ratings yet
- Seminar III Report FinalDocument39 pagesSeminar III Report Finalganesh gundNo ratings yet
- Energy Management in Wireless Sensor NetworksFrom EverandEnergy Management in Wireless Sensor NetworksRating: 4 out of 5 stars4/5 (1)
- Thermal Process Calculations Using Arti®cial Neural Network ModelsDocument11 pagesThermal Process Calculations Using Arti®cial Neural Network ModelsMario CalderonNo ratings yet
- Data Driven Remaining Useful Life Prediction Via MDocument10 pagesData Driven Remaining Useful Life Prediction Via MAlex vilcaNo ratings yet
- The Evaluation of Grinding Process Using ArtificiaDocument8 pagesThe Evaluation of Grinding Process Using ArtificiaAlex vilcaNo ratings yet
- DEM Modelling of Liner Evolution and Its Influence On Grinding Rate in Ball MillsDocument11 pagesDEM Modelling of Liner Evolution and Its Influence On Grinding Rate in Ball MillsAlex vilcaNo ratings yet
- Nuevo Documento de TextoDocument1 pageNuevo Documento de TextoAlex vilcaNo ratings yet
- Gamma LDocument21 pagesGamma LAlex vilcaNo ratings yet
- Medidor de VibracionesDocument4 pagesMedidor de VibracionesAlex vilcaNo ratings yet
- Cable RojoDocument2 pagesCable RojoAlex vilcaNo ratings yet
- Okonite Cable NegroDocument2 pagesOkonite Cable NegroAlex vilcaNo ratings yet
- DBL Co Produktuebersicht Stommesszangen Englisch PDFDocument48 pagesDBL Co Produktuebersicht Stommesszangen Englisch PDFAlex vilcaNo ratings yet
- Esquemas Electricos CATDocument17 pagesEsquemas Electricos CATAlex vilcaNo ratings yet
- Calentador Fostoria FES 1024 1CADocument12 pagesCalentador Fostoria FES 1024 1CAAlex vilca100% (1)
- Removing Base Pan and Servicing MotorDocument3 pagesRemoving Base Pan and Servicing Motorrizki arfi100% (2)
- Bearing Pad Design ExampleDocument16 pagesBearing Pad Design ExampleAhirul Yahya100% (1)
- Generator SpecificationsDocument20 pagesGenerator SpecificationsjdanastasNo ratings yet
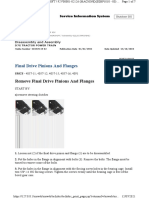
- Remove Final Drive Pinions and FlangesDocument7 pagesRemove Final Drive Pinions and Flangesrapha raphaNo ratings yet
- Troubleshoot Clutch IssuesDocument13 pagesTroubleshoot Clutch IssuesNam TranNo ratings yet
- XE301P Service ManualDocument77 pagesXE301P Service ManualJohn Holding100% (1)
- Hydrocarbon Processing 01 2012Document95 pagesHydrocarbon Processing 01 2012Ionela PoenaruNo ratings yet
- Tpi 253 de enDocument20 pagesTpi 253 de enFilozófus ÖnjelöltNo ratings yet
- Timken Cylindrical Roller Bearing Catalog 10447Document108 pagesTimken Cylindrical Roller Bearing Catalog 10447Alexander BossioNo ratings yet
- paver-TM-153 MAIN SCH BRM (PBR-400R) PDFDocument28 pagespaver-TM-153 MAIN SCH BRM (PBR-400R) PDFYousef AlipourNo ratings yet
- Drag Conveyors: Learner GuideDocument21 pagesDrag Conveyors: Learner GuidehgNo ratings yet
- Boom Repair Kits - : But 35 F & GDocument5 pagesBoom Repair Kits - : But 35 F & GLechung NguyenNo ratings yet
- 120K CatDocument64 pages120K CatMarco Olivetto100% (4)
- Gear Pump PDFDocument50 pagesGear Pump PDFAnonymous CMS3dL1T100% (1)
- Manual T10A65 B PDFDocument36 pagesManual T10A65 B PDFHéctor José Muñoz RocaNo ratings yet
- EVM Vertical Multistage Pumps in Stainless SteelDocument17 pagesEVM Vertical Multistage Pumps in Stainless SteelJayakrishnan RadhakrishnanNo ratings yet
- Flow Measurement.: Flowmeters. Display and Processing UnitDocument24 pagesFlow Measurement.: Flowmeters. Display and Processing UnitStefas DimitriosNo ratings yet
- EXP Series - : Standard Chemical Process PumpsDocument6 pagesEXP Series - : Standard Chemical Process PumpsMohsen ParpinchiNo ratings yet
- Specialty Lubricants: MolykoteDocument2 pagesSpecialty Lubricants: MolykoteRildo CarvalhoNo ratings yet
- Rotordynamics Module V56!16!9Document57 pagesRotordynamics Module V56!16!9shubham patil100% (1)
- University of Vocational Technology Machine Design Lecture Notes on BearingsDocument24 pagesUniversity of Vocational Technology Machine Design Lecture Notes on BearingsJohn Milton100% (2)
- Customized Machined SealsDocument6 pagesCustomized Machined Sealsgrupa2904No ratings yet
- BR2 001 - Rex and Link Belt Spherical Roller Bearings - CatalogDocument159 pagesBR2 001 - Rex and Link Belt Spherical Roller Bearings - CatalogJoséMiguelSánchezGNo ratings yet
- TIMKEN Machacadora de ConoDocument2 pagesTIMKEN Machacadora de Conokev YNo ratings yet
- GATE - IES QuestionsDocument4 pagesGATE - IES QuestionsMahesh Chandrabhan ShindeNo ratings yet
- Design Calculation & AnalysisDocument13 pagesDesign Calculation & AnalysisAbel MeketaNo ratings yet
- SKF - 10000 EN - Page(s) 0420 To 0473 - Y-BearingsDocument54 pagesSKF - 10000 EN - Page(s) 0420 To 0473 - Y-Bearingsbdibujante89No ratings yet
- Bearing of BridgesDocument39 pagesBearing of BridgesAbhishek100% (1)
- Rod Install PDFDocument8 pagesRod Install PDFVeterano del Camino100% (1)
- 3406 - 376kVA@1500 Maintenance ScheduleDocument10 pages3406 - 376kVA@1500 Maintenance ScheduleNaditya's FamilyNo ratings yet