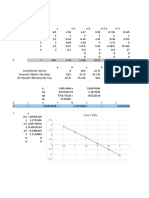
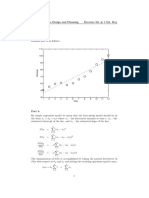
You might also like
- Business StatisticsDocument4 pagesBusiness StatisticskebNo ratings yet
- Simple Linear Regression (Solutions To Exercises)Document28 pagesSimple Linear Regression (Solutions To Exercises)blu runner1No ratings yet
- Butler Truck Ing CompanyDocument7 pagesButler Truck Ing CompanyHannah GallanoNo ratings yet
- Σy Ȳ Ȳ Ȳ Ȳ Ȳ Desviacion Estándar Ȳ Ȳ Ȳ Aσy-Bσxy Ȳ N- 2 ΣyDocument8 pagesΣy Ȳ Ȳ Ȳ Ȳ Ȳ Desviacion Estándar Ȳ Ȳ Ȳ Aσy-Bσxy Ȳ N- 2 Σyandrea delgadoNo ratings yet
- Catkul d3 081117Document6 pagesCatkul d3 081117Try Zivilians ZetiaNo ratings yet
- Catkul d3 081117Document6 pagesCatkul d3 081117Try Zivilians ZetiaNo ratings yet
- Driving Assignment (X-Xbar) 2 Miles Traveled (X) Travel Time (Y) X-Xbar (Mean) Y-Ybar (Mean)Document7 pagesDriving Assignment (X-Xbar) 2 Miles Traveled (X) Travel Time (Y) X-Xbar (Mean) Y-Ybar (Mean)Karen Kaye PasamonteNo ratings yet
- Engineering ManagementDocument4 pagesEngineering ManagementPHILIPANTHONY MASILANGNo ratings yet
- Regression SolutionDocument11 pagesRegression SolutionbangNo ratings yet
- w2 Chapter-02Document11 pagesw2 Chapter-02FirstX.No ratings yet
- Activity No 2 StatDocument5 pagesActivity No 2 StatIdris HermanNo ratings yet
- Statistical Techniques in Business and EconomicsDocument15 pagesStatistical Techniques in Business and EconomicsJesslyn Emmanuela Njoto PrawiroNo ratings yet
- Student Name: Zain Asim: Question 1 (Correlation Coefficient and Population Analysis)Document7 pagesStudent Name: Zain Asim: Question 1 (Correlation Coefficient and Population Analysis)Abass GblaNo ratings yet
- Examples RegressionDocument19 pagesExamples Regressionghania azharNo ratings yet
- Examen FinalDocument7 pagesExamen FinalFernando PedrazaNo ratings yet
- Homework - 1 MATLAB Exercises SolutionsDocument5 pagesHomework - 1 MATLAB Exercises Solutionsmanthan212No ratings yet
- Taller 11Document2 pagesTaller 11angie_varela8511No ratings yet
- Ishika ChapranaDocument5 pagesIshika ChapranaAshi Ashok ChaurasiaNo ratings yet
- Test Result Test Result: Quantitative QuantitativeDocument3 pagesTest Result Test Result: Quantitative QuantitativeLarentia S. Dela VegaNo ratings yet
- Multiple Linear Regression 1Document8 pagesMultiple Linear Regression 1crossline093No ratings yet
- Regression Solved ExampleDocument3 pagesRegression Solved ExampletauqeerahmedNo ratings yet
- STPM Physic Experiment 2 (Term 1, 2016) .Document2 pagesSTPM Physic Experiment 2 (Term 1, 2016) .Oh Yee YinNo ratings yet
- Simple Linear Regression EquationDocument7 pagesSimple Linear Regression Equationsuboor ahmedNo ratings yet
- UPDATED - Correlation WorksheetDocument5 pagesUPDATED - Correlation WorksheetMARION JUMAO-AS GORDONo ratings yet
- Sales (Yi) Income (Xi) : Model Unstandardized Coefficients Standardized Coefficients T Sig. Collinearity StatisticsDocument1 pageSales (Yi) Income (Xi) : Model Unstandardized Coefficients Standardized Coefficients T Sig. Collinearity StatisticsMaria SariNo ratings yet
- Correlation RegressionDocument14 pagesCorrelation Regressionaris budi santosoNo ratings yet
- MetnumDocument2 pagesMetnumpriscillyaNo ratings yet
- Taller 11Document2 pagesTaller 11angie_varela8511No ratings yet
- Diagrama de Dispercion: Semana Ventas PrecioDocument18 pagesDiagrama de Dispercion: Semana Ventas PrecioJuanCarlos MendozaNo ratings yet
- Correlation and Regression Activity - Answer KeyDocument22 pagesCorrelation and Regression Activity - Answer KeyLalaine Bautista LlabanNo ratings yet
- Naïve Approach: ForecastingDocument5 pagesNaïve Approach: Forecastingkuma;lNo ratings yet
- Assignment 2 - 20376005 - BTC507Document13 pagesAssignment 2 - 20376005 - BTC507SIM ProteinNo ratings yet
- Applied StastisticsDocument2 pagesApplied StastisticsReasat AzimNo ratings yet
- Assignment 6Document7 pagesAssignment 6Myo Thi HaNo ratings yet
- Statistic SPSS Working PaperDocument5 pagesStatistic SPSS Working PapergulsahguldaliggNo ratings yet
- Latihan Regresi SederhanaDocument7 pagesLatihan Regresi Sederhanafhj77thnm9No ratings yet
- METNUMDocument3 pagesMETNUMpriscillyaNo ratings yet
- SBST3203 Elementary Data Analysis MAY 2020: Name: Arif Soebah Id No: 830811125679001 Phone Number: 013-8880791 EmailDocument9 pagesSBST3203 Elementary Data Analysis MAY 2020: Name: Arif Soebah Id No: 830811125679001 Phone Number: 013-8880791 Emailanwar soebahNo ratings yet
- Ejercicio de Tablas Bivariados EstadísticaDocument6 pagesEjercicio de Tablas Bivariados EstadísticaNayaret SilvaNo ratings yet
- Solution ManualDocument30 pagesSolution ManualLakber MandNo ratings yet
- SM Sbe13e Chapter 03Document40 pagesSM Sbe13e Chapter 03VRUSHABH WALKENo ratings yet
- Anareg No.1 Full Variabel by Irene Jesica 13.7670Document18 pagesAnareg No.1 Full Variabel by Irene Jesica 13.7670apri ansNo ratings yet
- Tugas Metode Kuantitatif - Dicky WahyudiDocument9 pagesTugas Metode Kuantitatif - Dicky WahyudiDicky WahyudiNo ratings yet
- B ModuleDocument2 pagesB ModuleBhem CabalquintoNo ratings yet
- Calapiz Seatwork 4.2Document3 pagesCalapiz Seatwork 4.2Eydzey CalapizNo ratings yet
- Ejercicio 3analisisDocument32 pagesEjercicio 3analisisCERVANDO MUNDACA REYESNo ratings yet
- Mmworld Unit 2 Activity S2: StatiscsDocument3 pagesMmworld Unit 2 Activity S2: StatiscsSofia MarieNo ratings yet
- Topic 8: SPC: Mean Value of First Subgroup (Document4 pagesTopic 8: SPC: Mean Value of First Subgroup (Azlie AzizNo ratings yet
- Graf FuncionesDocument4 pagesGraf FuncionesNayly GallardoNo ratings yet
- Evaluasi Sumur GG-02: South SumatraDocument25 pagesEvaluasi Sumur GG-02: South SumatraYosua Pandapotan SihotangNo ratings yet
- Clase - Feb17-24 Simulac.Document18 pagesClase - Feb17-24 Simulac.leslymilenazapataNo ratings yet
- Assignment 1 Sol 2022Document4 pagesAssignment 1 Sol 2022Inès ChougraniNo ratings yet
- Exercise Set 1 Solution KeyDocument9 pagesExercise Set 1 Solution Keyelifatlgan25No ratings yet
- Latihan AndataDocument12 pagesLatihan AndataPSKM STIKES HI JAMBINo ratings yet
- Lab 1Document7 pagesLab 1Kashif hussainNo ratings yet
- (Yij - Y..) (Yi. - Y..) + (Yij - Yi.)Document17 pages(Yij - Y..) (Yi. - Y..) + (Yij - Yi.)safiraNo ratings yet
- Math Review AnswerDocument2 pagesMath Review AnswerashfiashaffaNo ratings yet
- Part 7-Forecasting PDFDocument14 pagesPart 7-Forecasting PDFJohn TentNo ratings yet
- Model Digital Signal ProcessingDocument4 pagesModel Digital Signal ProcessingnjmnjkNo ratings yet
- Chart Title: 8 9 F (X) 7.7211504037x + 0.050637123 R 0.9991358136Document2 pagesChart Title: 8 9 F (X) 7.7211504037x + 0.050637123 R 0.9991358136arifa nrNo ratings yet
- A Regression Analysis of Measurements of A Dependent Variable Y On An Independent Variable XDocument13 pagesA Regression Analysis of Measurements of A Dependent Variable Y On An Independent Variable Xblu runner1No ratings yet
- Chapter 12Document60 pagesChapter 12blu runner1No ratings yet
- Formula Sheet For Exam1Document3 pagesFormula Sheet For Exam1blu runner1No ratings yet
- Evaporative Cooling Systems:: How and Why They WorkDocument4 pagesEvaporative Cooling Systems:: How and Why They Workblu runner1No ratings yet
- Ayurvedic Management of Acute Food Induced Anaphylactic Reaction - A CaseDocument5 pagesAyurvedic Management of Acute Food Induced Anaphylactic Reaction - A CaseShivam TrivediNo ratings yet
- TOEFLDocument25 pagesTOEFLDiah Dwi UtamiNo ratings yet
- Benefit Availment ProceduresDocument1 pageBenefit Availment ProceduresJasper Allen B. BarrientosNo ratings yet
- 8.00bb3hhnat114a69.000 - 2022 09 21 - 15 49 43Document3 pages8.00bb3hhnat114a69.000 - 2022 09 21 - 15 49 43uriel granadosNo ratings yet
- BC557 Datasheet PDFDocument5 pagesBC557 Datasheet PDFArya WidyatmakaNo ratings yet
- Lab 4: Programming in Assembly Language-Part2Document5 pagesLab 4: Programming in Assembly Language-Part2ARNajeebNo ratings yet
- Tentative Final NotesDocument13 pagesTentative Final NotesRockNo ratings yet
- Landis+Gyr E650 - Landis+GyrDocument2 pagesLandis+Gyr E650 - Landis+Gyrazad jalalNo ratings yet
- PROPER HANDWASHING ScriptDocument1 pagePROPER HANDWASHING ScriptJin morarengNo ratings yet
- Philippine National Police Services: Gian Venci T. AlonzoDocument8 pagesPhilippine National Police Services: Gian Venci T. AlonzoChristianJohn NunagNo ratings yet
- Saep 58 PDFDocument38 pagesSaep 58 PDFRami ElloumiNo ratings yet
- Csat Comprehensive 2022Document5 pagesCsat Comprehensive 2022shailacNo ratings yet
- 10 Soal Degrees of Comparison Pilihan GandaDocument1 page10 Soal Degrees of Comparison Pilihan Gandaugiy_it75% (8)
- Clerkship ManualDocument132 pagesClerkship ManualasdfasdfNo ratings yet
- Illustration PortfolioDocument21 pagesIllustration PortfoliojordannobleNo ratings yet
- Retail Outlet Inspection Report: A. Sales & Stock 1. Totalizer ReadingsDocument6 pagesRetail Outlet Inspection Report: A. Sales & Stock 1. Totalizer ReadingsRajneesh JhoradNo ratings yet
- Modern Historical Sistematical Observations On Filioque Addition Summary: Today, OecumenicalDocument2 pagesModern Historical Sistematical Observations On Filioque Addition Summary: Today, OecumenicalbodoxxxNo ratings yet
- Strategic ManagementDocument13 pagesStrategic ManagementJanice KawiraNo ratings yet
- DR Harish GhootaDocument4 pagesDR Harish GhootasmoothcallNo ratings yet
- Distribution in A Services ContextDocument45 pagesDistribution in A Services ContextKirti GiyamalaniNo ratings yet
- Individual Daily Log and Accomplishment ReportDocument2 pagesIndividual Daily Log and Accomplishment ReportJe-ann H. GonzalesNo ratings yet
- Guide Book KNU - 2023 - Fall - EngDocument45 pagesGuide Book KNU - 2023 - Fall - EngSojida KarimovaNo ratings yet
- Bronchial Asthma PDFDocument32 pagesBronchial Asthma PDFArpitha YadavalliNo ratings yet
- Optimization of Fermentation Conditions For EthanoDocument9 pagesOptimization of Fermentation Conditions For Ethanovodachemicals20No ratings yet
- THE KINETICS OF PRECIPITATION FROM SUPERSATURATED SOLID SOLUTIONS - I. M. LIFSHITZ and V. V. SLYOZOV (1959) PDFDocument16 pagesTHE KINETICS OF PRECIPITATION FROM SUPERSATURATED SOLID SOLUTIONS - I. M. LIFSHITZ and V. V. SLYOZOV (1959) PDFWalter Sperandio SampaioNo ratings yet
- The Marketing Function's Main RolesDocument11 pagesThe Marketing Function's Main RolesNga Nga NguyenNo ratings yet
- Better HTML & CSS TutorialDocument101 pagesBetter HTML & CSS TutorialIrina Marinescu100% (3)
- Excel 5 Grade, Unit 1 - Home and AwayDocument8 pagesExcel 5 Grade, Unit 1 - Home and AwayYenlik Z100% (1)
- Siddaganga Institute of Technology, Tumakuru - 572 103: Usn 1 S I OE02Document2 pagesSiddaganga Institute of Technology, Tumakuru - 572 103: Usn 1 S I OE02S R GOWDANo ratings yet