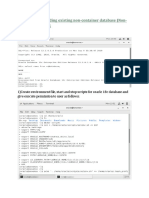
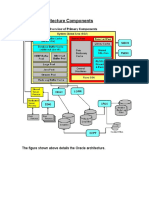
You might also like
- DRBD-Cookbook: How to create your own cluster solution, without SAN or NAS!From EverandDRBD-Cookbook: How to create your own cluster solution, without SAN or NAS!No ratings yet
- Oracle 11g R1/R2 Real Application Clusters EssentialsFrom EverandOracle 11g R1/R2 Real Application Clusters EssentialsRating: 5 out of 5 stars5/5 (1)
- Database Installation Guide LinuxDocument239 pagesDatabase Installation Guide Linuxotra dosNo ratings yet
- EDB Global Training CatalogueDocument55 pagesEDB Global Training Cataloguepush5No ratings yet
- Presentation Understanding Oracle RAC Internals - Part 1 - SlidesDocument48 pagesPresentation Understanding Oracle RAC Internals - Part 1 - Slidesjatin_meghaniNo ratings yet
- 52492-rc071 Postgresql PDFDocument11 pages52492-rc071 Postgresql PDFJedt3DNo ratings yet
- Data Guard Broker PDFDocument370 pagesData Guard Broker PDFjuberNo ratings yet
- Dataguard - MyunderstandingDocument3 pagesDataguard - Myunderstandingabdulgani11No ratings yet
- EDB High Availability Scalability v1.0Document23 pagesEDB High Availability Scalability v1.0Paohua ChuangNo ratings yet
- Study Guide For Oracle Certified MasterDocument132 pagesStudy Guide For Oracle Certified MasterpablovivasveNo ratings yet
- 12c To 18c UpgradeDocument45 pages12c To 18c UpgradeRavali SharmaNo ratings yet
- Oracle Goldengate Hands-On Tutorial: Version Date: 1 Oct, 2012 EditorDocument115 pagesOracle Goldengate Hands-On Tutorial: Version Date: 1 Oct, 2012 EditorTolulope AbiodunNo ratings yet
- Pro Oracle SQL Development: Best Practices for Writing Advanced QueriesFrom EverandPro Oracle SQL Development: Best Practices for Writing Advanced QueriesNo ratings yet
- Admin D78846GC30 sg1Document409 pagesAdmin D78846GC30 sg1Hồng Quân100% (1)
- Oracle Database 12c R2: Administration Workshop Ed 3: DurationDocument6 pagesOracle Database 12c R2: Administration Workshop Ed 3: Durationjackomito100% (1)
- Goldengate 12cDocument380 pagesGoldengate 12csumeguptNo ratings yet
- Upgrade To PostgreSQL11Document36 pagesUpgrade To PostgreSQL11leonard1971No ratings yet
- 21c Using Oracle ShardingDocument292 pages21c Using Oracle ShardingsuhaasNo ratings yet
- Java Programming With Oracle Database 19cDocument19 pagesJava Programming With Oracle Database 19cakbezawadaNo ratings yet
- ASM ScriptsDocument11 pagesASM ScriptskarthikNo ratings yet
- Oracle Data Guard 12cR2Document176 pagesOracle Data Guard 12cR2Rogério Pereira FalconeNo ratings yet
- AWR RPT Reading PDFDocument64 pagesAWR RPT Reading PDFharsshNo ratings yet
- Live Partition Mobility For Oracle RACDocument44 pagesLive Partition Mobility For Oracle RACgmarxouNo ratings yet
- Active Dataguard Database Using RMAN DUPLICATEDocument10 pagesActive Dataguard Database Using RMAN DUPLICATEZakir HossenNo ratings yet
- HVR User Manual 5.7.cec91698Document715 pagesHVR User Manual 5.7.cec91698Thaj MohaideenNo ratings yet
- Mysql For Beginners: Student GuideDocument12 pagesMysql For Beginners: Student GuidequelquneNo ratings yet
- MongoDB Manual MasterDocument1,117 pagesMongoDB Manual MastertonygmnNo ratings yet
- D74508GC10 AgDocument514 pagesD74508GC10 Agradhashyam naakNo ratings yet
- Oracle Acfs and Dbfs-PresentationDocument33 pagesOracle Acfs and Dbfs-PresentationbehanchodNo ratings yet
- Perform basic tasks in Oracle MultitenantDocument18 pagesPerform basic tasks in Oracle MultitenantVinod Kumar KannieboinaNo ratings yet
- Database Architecture Oracle DbaDocument41 pagesDatabase Architecture Oracle DbaImran ShaikhNo ratings yet
- Oracle GoldenGate NotesDocument9 pagesOracle GoldenGate NotesabishekvsNo ratings yet
- Book Oracle RACDocument124 pagesBook Oracle RACKamal Kumar100% (1)
- ASM ConfigDocument57 pagesASM ConfigkwagnyNo ratings yet
- Exadata PerformanceDocument35 pagesExadata Performancesdranga123No ratings yet
- Oracle9i Database - Advanced Backup and Recovery Using RMAN - Student GuideDocument328 pagesOracle9i Database - Advanced Backup and Recovery Using RMAN - Student Guideacsabo_14521769No ratings yet
- ASM CommandsDocument4 pagesASM CommandsHarish NaikNo ratings yet
- Cheatsheet: Postgresql Monitoring: More Info More InfoDocument2 pagesCheatsheet: Postgresql Monitoring: More Info More InfoCheck ATNo ratings yet
- Gridlink RacDocument21 pagesGridlink RacAngel Freire RamirezNo ratings yet
- Oracle - Exadata With RAC DBA CourseDocument4 pagesOracle - Exadata With RAC DBA CourseanshoeNo ratings yet
- Oracle PL/SQL Course - Learn Database ProgrammingDocument26 pagesOracle PL/SQL Course - Learn Database ProgrammingchensuriyanNo ratings yet
- Database Technology 1 Craig Shallahamer SQL Elapsed Time Analhysispdf1213Document32 pagesDatabase Technology 1 Craig Shallahamer SQL Elapsed Time Analhysispdf1213Felix Mateos MedranoNo ratings yet
- Quick Guide To MySQL WorkbenchDocument4 pagesQuick Guide To MySQL WorkbenchTubagus BondanNo ratings yet
- Using WebLogic Server Multitenant PDFDocument256 pagesUsing WebLogic Server Multitenant PDFFabian Cabrera0% (1)
- DB6 LUW DBA CockpitDocument244 pagesDB6 LUW DBA CockpitJonathan CarrilloNo ratings yet
- Oracle RAC Performance ManagementDocument35 pagesOracle RAC Performance ManagementKrishna8765No ratings yet
- Oracle DBA Fundamental 1 Exam Questions and Answers: Buffer Cache Redo Log in TheDocument17 pagesOracle DBA Fundamental 1 Exam Questions and Answers: Buffer Cache Redo Log in Theutagore58No ratings yet
- Oam11g Exam Study Guide 1933465Document17 pagesOam11g Exam Study Guide 1933465Murali PalepuNo ratings yet
- Oracle 11gR2 Core DBA Course-1Document84 pagesOracle 11gR2 Core DBA Course-1Kaleem KhanNo ratings yet
- Aix - 7.1 - Oracle - Requirements PDFDocument28 pagesAix - 7.1 - Oracle - Requirements PDFimenhidouriNo ratings yet
- Administering Oracle Database Classic Cloud Service PDFDocument425 pagesAdministering Oracle Database Classic Cloud Service PDFGanesh KaralkarNo ratings yet
- Ingres Command RefDocument292 pagesIngres Command Reframuyadav1100% (1)
- Oracle Database 12c: New FeaturesDocument89 pagesOracle Database 12c: New FeaturesamalkumarNo ratings yet
- Automatic Tools For High Availability in Postgresql: Camilo Andrés EcheverriDocument9 pagesAutomatic Tools For High Availability in Postgresql: Camilo Andrés EcheverriRegistro PersonalNo ratings yet
- Golden Gate Oracle ReplicationDocument3 pagesGolden Gate Oracle ReplicationCynthiaNo ratings yet
- Oracle DBA BrochureDocument15 pagesOracle DBA Brochuresmall_sat5337No ratings yet
- Agent Upgrade ErrorDocument2 pagesAgent Upgrade ErrorKoushikKc ChatterjeeNo ratings yet
- CFG VCP cfg4 Clone Workflow1Document3 pagesCFG VCP cfg4 Clone Workflow1KoushikKc ChatterjeeNo ratings yet
- Blackout Documentation in 12c OEMDocument18 pagesBlackout Documentation in 12c OEMKoushikKc ChatterjeeNo ratings yet
- Comic Con India: Hi Koushik ChatterjeeDocument2 pagesComic Con India: Hi Koushik ChatterjeeKoushikKc ChatterjeeNo ratings yet
- Oracle RunbookDocument198 pagesOracle RunbookKoushikKc ChatterjeeNo ratings yet
- Welcome To (Adventure Division of Hippie Soul Pvt. LTD.) : Isole' HimalayasDocument5 pagesWelcome To (Adventure Division of Hippie Soul Pvt. LTD.) : Isole' HimalayasKoushikKc ChatterjeeNo ratings yet
- Confirmed Hyderabad to Kolkata Flight BookingDocument2 pagesConfirmed Hyderabad to Kolkata Flight BookingKoushikKc ChatterjeeNo ratings yet
- Oracle Admin Vol2Document374 pagesOracle Admin Vol2KoushikKc ChatterjeeNo ratings yet
- Job Description - Camera Person JOB TITLE: Camera Person Experience Level Required: Key ResponsibilitiesDocument1 pageJob Description - Camera Person JOB TITLE: Camera Person Experience Level Required: Key ResponsibilitiesKoushikKc ChatterjeeNo ratings yet
- VM SetupDocument1 pageVM SetupKoushikKc ChatterjeeNo ratings yet
- AWS ML Enterprise GuideDocument17 pagesAWS ML Enterprise GuideyoyovohNo ratings yet
- Apache CassandraDocument166 pagesApache CassandraKoushikKc Chatterjee100% (1)
- GoldenGate PracsDocument130 pagesGoldenGate PracsKoushikKc ChatterjeeNo ratings yet
- COVID 19 Geographic Disbtribution Worldwide 2020-03-15Document228 pagesCOVID 19 Geographic Disbtribution Worldwide 2020-03-15KoushikKc ChatterjeeNo ratings yet
- Step Date Destinations Headings Paid in INR India - Cambodia Itinerary - 9 DaysDocument3 pagesStep Date Destinations Headings Paid in INR India - Cambodia Itinerary - 9 DaysKoushikKc ChatterjeeNo ratings yet
- The Wall Street Journal March 19 20 2022Document55 pagesThe Wall Street Journal March 19 20 2022KoushikKc ChatterjeeNo ratings yet
- Financial Times Uk February 16 2022Document22 pagesFinancial Times Uk February 16 2022KoushikKc ChatterjeeNo ratings yet
- Rimas Silkaitis: From Postgres To CassandraDocument95 pagesRimas Silkaitis: From Postgres To CassandraKoushikKc ChatterjeeNo ratings yet
- Modern Healthcare February 21 2022Document54 pagesModern Healthcare February 21 2022KoushikKc ChatterjeeNo ratings yet
- Model EngineersWorkshop February 2022Document70 pagesModel EngineersWorkshop February 2022KoushikKc Chatterjee100% (2)
- Kanchan Mohitey - Director, Cloud Services Marc Linster - SVP, Product DevelopmentDocument22 pagesKanchan Mohitey - Director, Cloud Services Marc Linster - SVP, Product DevelopmentKoushikKc ChatterjeeNo ratings yet
- Cassandra Certification Study Guide DataStaxDocument20 pagesCassandra Certification Study Guide DataStaxMahesh Reddy sayamolla13% (8)
- Intro To Cassandra For DevelopersDocument61 pagesIntro To Cassandra For DevelopersKoushikKc ChatterjeeNo ratings yet
- Model Boats Issue 855 February 2022Document86 pagesModel Boats Issue 855 February 2022KoushikKc ChatterjeeNo ratings yet
- Postgresql 14 New Features With Examples (Beta 1)Document86 pagesPostgresql 14 New Features With Examples (Beta 1)KoushikKc ChatterjeeNo ratings yet
- Post GR Esq L Notes For ProfessionalsDocument73 pagesPost GR Esq L Notes For ProfessionalsFede ConteNo ratings yet
- Choosingthe Right Sqldbfor Your Needs: Service Type Resource Model SLA Best ForDocument7 pagesChoosingthe Right Sqldbfor Your Needs: Service Type Resource Model SLA Best ForKoushikKc ChatterjeeNo ratings yet
- Azure Sentinel Deployment Best PracticesDocument71 pagesAzure Sentinel Deployment Best PracticesKoushikKc Chatterjee100% (1)
- Amazon Rds For Postgresql & Amazon Aurora PostgresqlDocument65 pagesAmazon Rds For Postgresql & Amazon Aurora PostgresqlKoushikKc ChatterjeeNo ratings yet
- Introduction To Companies - Flipkart and Meesho FlipkartDocument5 pagesIntroduction To Companies - Flipkart and Meesho FlipkartARNAV MISRANo ratings yet
- 050 Vacuum Pump Systems 2021Document190 pages050 Vacuum Pump Systems 2021Balamurugan ArumugamNo ratings yet
- Automata Homework SolutionsDocument5 pagesAutomata Homework Solutionsafmsxeghf100% (1)
- Alla Priser Anges Exkl. Moms. Kontakta Din Säljare Vid FrågorDocument46 pagesAlla Priser Anges Exkl. Moms. Kontakta Din Säljare Vid FrågorSamuelNo ratings yet
- 2106 Industry Placement Briefing - StudentDocument29 pages2106 Industry Placement Briefing - StudentArsalan JahaniNo ratings yet
- Shell Sort Algorithm Explained in DetailDocument8 pagesShell Sort Algorithm Explained in DetailLovely BeatsNo ratings yet
- Autocom Activator Keygen DownloadDocument2 pagesAutocom Activator Keygen Downloadkimmecanico13% (16)
- S1 Hyd Thrust T+answersDocument22 pagesS1 Hyd Thrust T+answersprabathiyaNo ratings yet
- IQ Range: Installation and Maintenance InstructionsDocument3 pagesIQ Range: Installation and Maintenance InstructionszeeshanNo ratings yet
- Faculty of Engineering, UNIMASDocument4 pagesFaculty of Engineering, UNIMASjohnNo ratings yet
- Cloud Strategy Tds ExtractDocument14 pagesCloud Strategy Tds ExtractkkNo ratings yet
- CIO Insights Special - Medical TechnologyDocument17 pagesCIO Insights Special - Medical TechnologyCarlos Alberto Chavez Aznaran IINo ratings yet
- Engg-Exam-December-2022-Odd (Main) - WDDocument35 pagesEngg-Exam-December-2022-Odd (Main) - WDNITEESH YANDRAPUDINo ratings yet
- Studi Pengaruh Waktu Pembakaran Terhadap Kuat Tekan BataDocument12 pagesStudi Pengaruh Waktu Pembakaran Terhadap Kuat Tekan BataIcha ChairunNo ratings yet
- Payan: Axle Jack PAYAN P/N: 2012Document38 pagesPayan: Axle Jack PAYAN P/N: 2012gmailNo ratings yet
- Business Analytics 705 v1 468Document468 pagesBusiness Analytics 705 v1 468Harty Robert100% (1)
- Ceiling Fan Laboratory Guidance ManualDocument35 pagesCeiling Fan Laboratory Guidance ManualSsdssddNo ratings yet
- Digital Learning Market in India WhitepaperDocument36 pagesDigital Learning Market in India WhitepaperBiswa Prakash NayakNo ratings yet
- 6 - Instructional Materials Development For ESPDocument12 pages6 - Instructional Materials Development For ESPMerren Monta100% (1)
- Working With Time - Lab Solutions Guide: Index Type Sourcetype Interesting FieldsDocument10 pagesWorking With Time - Lab Solutions Guide: Index Type Sourcetype Interesting FieldsPreet GadhiyaNo ratings yet
- Operator S Manual RED670 1.2Document134 pagesOperator S Manual RED670 1.2hari7077100% (1)
- Aditya CVDocument1 pageAditya CVDibyajyoti PrustyNo ratings yet
- Evaluacion Lin100final 2021Document2 pagesEvaluacion Lin100final 2021Lioney Ortiz TorrezNo ratings yet
- B2B Streamlined Bill Sample - Phone Bill Template FormDocument9 pagesB2B Streamlined Bill Sample - Phone Bill Template FormBrendon DrewNo ratings yet
- Quantitative Aptitude by SARVESH VERMADocument809 pagesQuantitative Aptitude by SARVESH VERMARajiv Ranjan0% (1)
- Avaya IP Office ContactCenter BrochureDocument87 pagesAvaya IP Office ContactCenter BrochureVicky NicNo ratings yet
- Digital Products Decommissioning Checklist: The Purpose of This Document Is ToDocument7 pagesDigital Products Decommissioning Checklist: The Purpose of This Document Is ToadiNo ratings yet
- Cortes Academy September Summative TestDocument2 pagesCortes Academy September Summative TestCortes AcademyNo ratings yet
- Release Mode Bundle ErrorDocument11 pagesRelease Mode Bundle ErrorRaman deepNo ratings yet
- Investor Customer'S Option To Receive Payments Through: No/Ledger Folio NoDocument3 pagesInvestor Customer'S Option To Receive Payments Through: No/Ledger Folio NoAnkur Bharat VermaNo ratings yet