You might also like
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Business Math Answer KeyDocument10 pagesBusiness Math Answer KeyCharlene DanaNo ratings yet
- More Minute Math Drills, Grades 1 - 3: Addition and SubtractionFrom EverandMore Minute Math Drills, Grades 1 - 3: Addition and SubtractionRating: 1 out of 5 stars1/5 (1)
- Qualifi Level 6 Diploma in Occupational Health and Safety Management Specification October 2019Document23 pagesQualifi Level 6 Diploma in Occupational Health and Safety Management Specification October 2019Saqlain Siddiquie100% (1)
- Ks3 d2 PW Complete AnswersDocument60 pagesKs3 d2 PW Complete AnswersDida Cowern100% (3)
- Instructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYFrom EverandInstructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYNo ratings yet
- Statistics For Business and Economics Revised 12th Edition Anderson Solutions Manual 1Document26 pagesStatistics For Business and Economics Revised 12th Edition Anderson Solutions Manual 1eldora100% (40)
- Ss1169 - Telecom Frameworx l1TMFDocument65 pagesSs1169 - Telecom Frameworx l1TMFPrince SinghNo ratings yet
- Krajewski 11e SM Ch08 Krajewski 11e SM Ch08: Operations management (경희대학교) Operations management (경희대학교)Document67 pagesKrajewski 11e SM Ch08 Krajewski 11e SM Ch08: Operations management (경희대학교) Operations management (경희대학교)natalos100% (1)
- Solutions Manual Production Operations Analysis 6th Edition Steven NahmiasDocument28 pagesSolutions Manual Production Operations Analysis 6th Edition Steven NahmiasAli Veli46% (13)
- (Template) SLOVINs FORMULADocument4 pages(Template) SLOVINs FORMULAAziil LiizaNo ratings yet
- Cinnamon Peelers in Sri Lanka: Shifting Labour Process and Reformation of Identity Post-1977Document8 pagesCinnamon Peelers in Sri Lanka: Shifting Labour Process and Reformation of Identity Post-1977Social Scientists' AssociationNo ratings yet
- SBST1303Document12 pagesSBST1303Inspire28No ratings yet
- MSDS Bisoprolol Fumarate Tablets (Greenstone LLC) (EN)Document10 pagesMSDS Bisoprolol Fumarate Tablets (Greenstone LLC) (EN)ANNaNo ratings yet
- Solutions Manual to accompany Introduction to Linear Regression AnalysisFrom EverandSolutions Manual to accompany Introduction to Linear Regression AnalysisRating: 1 out of 5 stars1/5 (1)
- Chapter 3-SolutionDocument29 pagesChapter 3-SolutionDevashishGuptaNo ratings yet
- Orca Share Media1579045586722Document4 pagesOrca Share Media1579045586722Teresa Marie Yap CorderoNo ratings yet
- Simplification Tricks - Easiest Way To Choose Simplification QuestionsDocument4 pagesSimplification Tricks - Easiest Way To Choose Simplification QuestionsAsjal HameedNo ratings yet
- Simplification Questions Moderate Level Part 1 Boost Up PdfsDocument12 pagesSimplification Questions Moderate Level Part 1 Boost Up PdfsKriti SinghaniaNo ratings yet
- FMS 2009 SolutionsDocument11 pagesFMS 2009 SolutionsrishikinraNo ratings yet
- Exercise 2B: 1 A 700 G, As This Is The Most Often Occurring. B 500 + 700 + 400 + 300 + 900 + 700 + 700 4200Document15 pagesExercise 2B: 1 A 700 G, As This Is The Most Often Occurring. B 500 + 700 + 400 + 300 + 900 + 700 + 700 4200drsus78No ratings yet
- SM Sbe13e Chapter 22Document19 pagesSM Sbe13e Chapter 22priyanka GayathriNo ratings yet
- Class 6 Maths Notes Knowing Your NumbersDocument15 pagesClass 6 Maths Notes Knowing Your NumbersRamarao ntNo ratings yet
- BA 2802 - Principles of Finance Solutions To Problems For Recitation #5Document7 pagesBA 2802 - Principles of Finance Solutions To Problems For Recitation #5Eda Nur EvginNo ratings yet
- Assessment of Selected Securities in Media Industry, India: Dr. Nalla Bala KalyanDocument9 pagesAssessment of Selected Securities in Media Industry, India: Dr. Nalla Bala KalyanTamanna YadavNo ratings yet
- Homework 1: Solution: A. Type of Data Is Cross-Section Data Because It Measures Different Person at The SameDocument7 pagesHomework 1: Solution: A. Type of Data Is Cross-Section Data Because It Measures Different Person at The SamePhương LinhNo ratings yet
- Business Statistics Canadian 3rd Edition Sharpe Solutions ManualDocument33 pagesBusiness Statistics Canadian 3rd Edition Sharpe Solutions Manualhymarbecurllzkit100% (19)
- TA112. BQA F.L Solution CMA September 2022 Exam.Document6 pagesTA112. BQA F.L Solution CMA September 2022 Exam.Mohammed Javed UddinNo ratings yet
- Preboard Exam XII Applied MathematicsDocument9 pagesPreboard Exam XII Applied MathematicsSmriti SaxenaNo ratings yet
- ks3 d2 SB Complete AnswersDocument191 pagesks3 d2 SB Complete AnswersEra Ersadata Br SaragihNo ratings yet
- Eco Sample Paper 1.Document19 pagesEco Sample Paper 1.aanyagaming680No ratings yet
- Dwnload Full Production and Operations Analysis 6th Edition Nahmias Solutions Manual PDFDocument35 pagesDwnload Full Production and Operations Analysis 6th Edition Nahmias Solutions Manual PDFsaabatmandearnestus100% (9)
- Class Notes Quant PDFDocument733 pagesClass Notes Quant PDFAnimesh Kumar100% (1)
- Assignments (Course Requirement) : Misamis University Graduate SchoolDocument7 pagesAssignments (Course Requirement) : Misamis University Graduate SchoolGraciously ElleNo ratings yet
- Ial Maths s1 CR3Document4 pagesIal Maths s1 CR3Martha MessinaNo ratings yet
- Σdemand ∈Previous Η Periods Η: Rosalijos, Reyman M. Bet-Mt2Document5 pagesΣdemand ∈Previous Η Periods Η: Rosalijos, Reyman M. Bet-Mt2reyman rosalijosNo ratings yet
- Ap 4Document5 pagesAp 4atharvavora2008No ratings yet
- F9 Mock Exam June 2020 - Answers PDFDocument9 pagesF9 Mock Exam June 2020 - Answers PDFNguyễn Quốc TuấnNo ratings yet
- Quant Updater - Set - 102 - Arun Singh RawatDocument38 pagesQuant Updater - Set - 102 - Arun Singh RawatSuraj DandotiyaNo ratings yet
- Quant Updater Set 122 Arun Singh RawatDocument36 pagesQuant Updater Set 122 Arun Singh RawatRoshan GuptaNo ratings yet
- Assignment 6 Regression Solution PDFDocument5 pagesAssignment 6 Regression Solution PDFlyriemaecutara0No ratings yet
- UM18MB502 QM-1 Unit 1 Practice ProblemsDocument3 pagesUM18MB502 QM-1 Unit 1 Practice ProblemschandrikaNo ratings yet
- Measure of Central Tendency and Dispersion (Solved)Document4 pagesMeasure of Central Tendency and Dispersion (Solved)Jupi BansodeNo ratings yet
- Grade7 218137 1181 9170Document11 pagesGrade7 218137 1181 9170Gbuarts Eleah PiamonteNo ratings yet
- COMM 4736 Practice Exam SolutionDocument5 pagesCOMM 4736 Practice Exam SolutionWenli FuNo ratings yet
- ASSIGNMENT 2 - Production Management - Đoàn Lê Ngọc Trâm - IELSIU19286Document6 pagesASSIGNMENT 2 - Production Management - Đoàn Lê Ngọc Trâm - IELSIU19286Cham ChamNo ratings yet
- SBE11E Chapter 22Document19 pagesSBE11E Chapter 22Anh DoNo ratings yet
- SM Sbe13e Chapter 03Document40 pagesSM Sbe13e Chapter 03VRUSHABH WALKENo ratings yet
- 0607 Worksheet2 PDFDocument2 pages0607 Worksheet2 PDFdora0% (1)
- Kelompok 6Document7 pagesKelompok 6Bervie RondonuwuNo ratings yet
- 11 Economics SP 01Document17 pages11 Economics SP 0110 Aryan AgarwalNo ratings yet
- Example For NumericalDocument9 pagesExample For Numericaltekalign yerangoNo ratings yet
- Grade 5 Multiplication inDocument16 pagesGrade 5 Multiplication inNamita GandotraNo ratings yet
- Week 6 Tutorial SolutionsDocument8 pagesWeek 6 Tutorial SolutionsManoaNo ratings yet
- Statistics For Business and Economics Revised 12th Edition Anderson Solutions ManualDocument27 pagesStatistics For Business and Economics Revised 12th Edition Anderson Solutions Manualchieverespectsew100% (25)
- Activity - Location DecisionsDocument2 pagesActivity - Location DecisionsMarissa C BautistaNo ratings yet
- Lahore School of EconomicsDocument10 pagesLahore School of EconomicsMahnoorNo ratings yet
- Lecture 01Document26 pagesLecture 01mohamed ezzatNo ratings yet
- Solution ManualDocument12 pagesSolution ManualReyna BaculioNo ratings yet
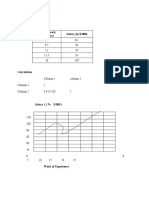
- Part A) Years of Work Experience Salary (In $'000)Document5 pagesPart A) Years of Work Experience Salary (In $'000)anamNo ratings yet
- Part A) Years of Work Experience Salary (In $'000)Document5 pagesPart A) Years of Work Experience Salary (In $'000)anamNo ratings yet
- Take n1 30f 30 0.75 23, n2 70+30f 70+30 0.75 93 (Round) : Hw4 - Computer System Simulation Fall 2023Document6 pagesTake n1 30f 30 0.75 23, n2 70+30f 70+30 0.75 93 (Round) : Hw4 - Computer System Simulation Fall 2023Mathabah OmerNo ratings yet
- Quant Checklist 85 PDF 2022 by Aashish AroraDocument78 pagesQuant Checklist 85 PDF 2022 by Aashish AroraBhav MathurNo ratings yet
- Ch24 AnswersDocument23 pagesCh24 Answersamisha2562585No ratings yet
- (Water Balance in Yom Basin) : KAED 6124280Document5 pages(Water Balance in Yom Basin) : KAED 6124280NICHANAT THONGJITNo ratings yet
- Ebook EDGEDocument48 pagesEbook EDGElandpookNo ratings yet
- Zomato: Presented By: Jatin Shenoy (J058)Document4 pagesZomato: Presented By: Jatin Shenoy (J058)DaiChi J3SNo ratings yet
- Real-Time Smart Home Surveillance SystemDocument11 pagesReal-Time Smart Home Surveillance SystemDaiChi J3SNo ratings yet
- Guide 3 - Geometry PDFDocument219 pagesGuide 3 - Geometry PDFm akhilaNo ratings yet
- Stat Introduction Units 1& 2Document108 pagesStat Introduction Units 1& 2DaiChi J3SNo ratings yet
- CHP - 51 - Cellular Manufacturing PDFDocument20 pagesCHP - 51 - Cellular Manufacturing PDFVinod ThakurNo ratings yet
- CHAPTER 2 SolutionDocument26 pagesCHAPTER 2 SolutionDaiChi J3SNo ratings yet
- Measureofskewness 180604161354Document13 pagesMeasureofskewness 180604161354chandrakanthatsNo ratings yet
- Daily Lives of Humans Are Directly Interconnected With Their Involvement in Handling Different Types of MachinesDocument3 pagesDaily Lives of Humans Are Directly Interconnected With Their Involvement in Handling Different Types of MachinesDaiChi J3SNo ratings yet
- Fact Pack Financial Services KenyaDocument12 pagesFact Pack Financial Services KenyaCatherineNo ratings yet
- Part A Plan: Simple Calculater Using Switch CaseDocument7 pagesPart A Plan: Simple Calculater Using Switch CaseRahul B. FereNo ratings yet
- 7933-Article Text-35363-1-10-20230724Document8 pages7933-Article Text-35363-1-10-20230724Ridho HidayatNo ratings yet
- Cara Membuat Motivation LetterDocument5 pagesCara Membuat Motivation LetterBayu Ade Krisna0% (1)
- Salva v. MakalintalDocument2 pagesSalva v. MakalintalGain DeeNo ratings yet
- Minas-A6 Manu e PDFDocument560 pagesMinas-A6 Manu e PDFJecson OliveiraNo ratings yet
- Erickson Transformer DesignDocument23 pagesErickson Transformer DesigndonscogginNo ratings yet
- Journalism Cover Letter TemplateDocument6 pagesJournalism Cover Letter Templateafaydebwo100% (2)
- Sec2 8 PDFDocument3 pagesSec2 8 PDFpolistaNo ratings yet
- Vylto Seed DeckDocument17 pagesVylto Seed DeckBear MatthewsNo ratings yet
- CEC Proposed Additional Canopy at Guard House (RFA-2021!09!134) (Signed 23sep21)Document3 pagesCEC Proposed Additional Canopy at Guard House (RFA-2021!09!134) (Signed 23sep21)MichaelNo ratings yet
- Gogte Institute of Technology: Karnatak Law Society'SDocument33 pagesGogte Institute of Technology: Karnatak Law Society'SjagaenatorNo ratings yet
- Ap06 - Ev04 Taller en Idioma Inglés Sobre Sistema de DistribuciónDocument9 pagesAp06 - Ev04 Taller en Idioma Inglés Sobre Sistema de DistribuciónJenny Lozano Charry50% (2)
- Channel System: Presented byDocument78 pagesChannel System: Presented bygrace22mba22No ratings yet
- CPM W1.1Document19 pagesCPM W1.1HARIJITH K SNo ratings yet
- DFUN Battery Monitoring Solution Project Reference 2022 V5.0Document50 pagesDFUN Battery Monitoring Solution Project Reference 2022 V5.0A Leon RNo ratings yet
- 11 TR DSU - CarrierDocument1 page11 TR DSU - Carriercalvin.bloodaxe4478100% (1)
- Pie in The Sky 3Document5 pagesPie in The Sky 3arsi_yaarNo ratings yet
- Province of Camarines Sur vs. CADocument8 pagesProvince of Camarines Sur vs. CACrisDBNo ratings yet
- S200 For Sumber RezekiDocument2 pagesS200 For Sumber RezekiIfan JayusdianNo ratings yet
- SDM Case AssignmentDocument15 pagesSDM Case Assignmentcharith sai t 122013601002No ratings yet
- Theories of Economic Growth ReportDocument5 pagesTheories of Economic Growth ReportAubry BautistaNo ratings yet
- BS As On 23-09-2023Document28 pagesBS As On 23-09-2023Farooq MaqboolNo ratings yet
- Ahakuelo IndictmentDocument24 pagesAhakuelo IndictmentHNNNo ratings yet
- Business-Model Casual Cleaning ServiceDocument1 pageBusiness-Model Casual Cleaning ServiceRudiny FarabyNo ratings yet
- Flyer Manuale - CON WATERMARK PAGINE SINGOLEDocument6 pagesFlyer Manuale - CON WATERMARK PAGINE SINGOLEjscmtNo ratings yet