You might also like
- Difference Equations in Normed Spaces: Stability and OscillationsFrom EverandDifference Equations in Normed Spaces: Stability and OscillationsNo ratings yet
- Lecturer 4 Regression AnalysisDocument29 pagesLecturer 4 Regression AnalysisShahzad Khan100% (1)
- Unit 5Document104 pagesUnit 5downloadjain123No ratings yet
- Applied Statistics II-SLRDocument23 pagesApplied Statistics II-SLRMagnifico FangaWoro100% (1)
- Lesson 7 - Linear Correlation and Simple Linear RegressionDocument8 pagesLesson 7 - Linear Correlation and Simple Linear Regressionchloe frostNo ratings yet
- 12 Bivariate Data Analysis: Regression and Correlation MethodsDocument22 pages12 Bivariate Data Analysis: Regression and Correlation MethodsYash TripathiNo ratings yet
- Simple Linear RegressionDocument42 pagesSimple Linear RegressionBlessingNo ratings yet
- Simple Linear Regression and Correlation PDFDocument7 pagesSimple Linear Regression and Correlation PDFcdqh7224g4No ratings yet
- Topic03 - RegressionDocument24 pagesTopic03 - RegressionsupergioNo ratings yet
- Simple Regression and Simple Correlation: MA261 Statistical and Numerical Techniques March 24, 2022Document52 pagesSimple Regression and Simple Correlation: MA261 Statistical and Numerical Techniques March 24, 2022Harshal jethwaNo ratings yet
- Lec - 00 7 - The CorrelationDocument43 pagesLec - 00 7 - The CorrelationTiee TieeNo ratings yet
- Institute: Uie (Ait-Cse) : CST-229 Lecture - 2.5Document40 pagesInstitute: Uie (Ait-Cse) : CST-229 Lecture - 2.5Sarthak AgarwalNo ratings yet
- Regression: Dr. Agustinus Suryantoro, M.SDocument31 pagesRegression: Dr. Agustinus Suryantoro, M.SVikha Suryo KharismawanNo ratings yet
- Unit 3 Simple Correlation and Regression Analysis1Document16 pagesUnit 3 Simple Correlation and Regression Analysis1Rhea MirchandaniNo ratings yet
- Review of Multiple RegressionDocument12 pagesReview of Multiple RegressionDavid SimanungkalitNo ratings yet
- Forecasting 2Document17 pagesForecasting 2Omer TunogluNo ratings yet
- Simple Linear RegressionDocument49 pagesSimple Linear RegressionAsif WarsiNo ratings yet
- TP05 Econometrics p1Document22 pagesTP05 Econometrics p1tommy.santos2No ratings yet
- Business Analytics: Advance: Simple & Multiple Linear RegressionDocument38 pagesBusiness Analytics: Advance: Simple & Multiple Linear RegressionKetan BhaleraoNo ratings yet
- STAT - Lec.3 - Correlation and RegressionDocument8 pagesSTAT - Lec.3 - Correlation and RegressionSalma HazemNo ratings yet
- Generalized Estimating Equations (Gees)Document40 pagesGeneralized Estimating Equations (Gees)r4adenNo ratings yet
- Regression and CorrelationDocument48 pagesRegression and CorrelationKelly Hoffman100% (1)
- Statistics: Basics: Aswath DamodaranDocument16 pagesStatistics: Basics: Aswath DamodaranRahmatullah MardanviNo ratings yet
- 3.0 ErrorVar and OLSvar-1Document42 pages3.0 ErrorVar and OLSvar-1Malik MahadNo ratings yet
- SST307 CompleteDocument72 pagesSST307 Completebranmondi8676No ratings yet
- 2017 Level II SS 3 Quantitative Methods (Lecture)Document10 pages2017 Level II SS 3 Quantitative Methods (Lecture)haoyuting426No ratings yet
- Engineering Apps: Session 4-Introduction To DADocument37 pagesEngineering Apps: Session 4-Introduction To DAMohamed Hesham GadallahNo ratings yet
- R: Linear RegressionDocument15 pagesR: Linear Regression育名No ratings yet
- Regression - Definition, Formula, Derivation, Application - EmbibeDocument10 pagesRegression - Definition, Formula, Derivation, Application - EmbibeSrishti ShivangNo ratings yet
- Correlation and RegressionDocument59 pagesCorrelation and RegressionKishenthi KerisnanNo ratings yet
- Appliedstat 2017 Chapter 12 13Document20 pagesAppliedstat 2017 Chapter 12 13Vivian HuNo ratings yet
- Chapter 1Document17 pagesChapter 1Getasew AsmareNo ratings yet
- Lesson 11 Simple Regression PDFDocument6 pagesLesson 11 Simple Regression PDFMarrick MbuiNo ratings yet
- Simple Resgression SimpleDocument6 pagesSimple Resgression SimplebiggykhairNo ratings yet
- INTRODocument7 pagesINTRONurul NajlaNo ratings yet
- 325unit 1 Simple Regression AnalysisDocument10 pages325unit 1 Simple Regression AnalysisutsavNo ratings yet
- CHP 3 Notes, GujaratiDocument4 pagesCHP 3 Notes, GujaratiDiwakar ChakrabortyNo ratings yet
- Linear Regression Analysis: Module - IvDocument10 pagesLinear Regression Analysis: Module - IvupenderNo ratings yet
- Chapter Eight 8 Simple Linear Regression and Correlation: N XY X Y N X XDocument5 pagesChapter Eight 8 Simple Linear Regression and Correlation: N XY X Y N X XtaysirbestNo ratings yet
- Lec29 StatsAndFits 2017Document28 pagesLec29 StatsAndFits 2017Tasneem MominNo ratings yet
- RegressionDocument55 pagesRegressionthinnapat.siriNo ratings yet
- 17 Regression AnalysisDocument10 pages17 Regression AnalysisDeepakNo ratings yet
- (2016) Pemodelan Regresi Berganda Dan GWR Pada Tingkat Pengangguran Terbuka Di Jawa Tengah PDFDocument15 pages(2016) Pemodelan Regresi Berganda Dan GWR Pada Tingkat Pengangguran Terbuka Di Jawa Tengah PDFSiswanto HarvardNo ratings yet
- GeeDocument40 pagesGeeHector GarciaNo ratings yet
- Chapter 2 Simple Linear RegressionDocument60 pagesChapter 2 Simple Linear RegressionChriss TwhNo ratings yet
- Chapter 16Document6 pagesChapter 16maustroNo ratings yet
- GEE AnnetteDocument40 pagesGEE Annettehubik38No ratings yet
- Characterising and Displaying Multivariate DataDocument15 pagesCharacterising and Displaying Multivariate DataR. Shyaam PrasadhNo ratings yet
- EconometricsDocument25 pagesEconometricsLynda Mega SaputryNo ratings yet
- Oversikt ECN402Document40 pagesOversikt ECN402Mathias VindalNo ratings yet
- Applied Statistics II Chapter 7 The Relationship Between Two VariablesDocument73 pagesApplied Statistics II Chapter 7 The Relationship Between Two VariablesJose Ruben Sorto BadaNo ratings yet
- Econometric Theory: Module - IiDocument8 pagesEconometric Theory: Module - IiVishnu VenugopalNo ratings yet
- Primera ClaseDocument48 pagesPrimera ClaseLino Ccarhuaypiña ContrerasNo ratings yet
- Chapter4 Regression ModelAdequacyCheckingDocument38 pagesChapter4 Regression ModelAdequacyCheckingAishat OmotolaNo ratings yet
- CorrelationDocument18 pagesCorrelationanandNo ratings yet
- Lecture 4Document60 pagesLecture 4Amine HadjiNo ratings yet
- Chapter12 Anova Analysis CovarianceDocument14 pagesChapter12 Anova Analysis CovariancemanopavanNo ratings yet
- Chapter 9Document14 pagesChapter 9beshahashenafe20No ratings yet
- Linear ModelsDocument92 pagesLinear ModelsCART11No ratings yet
- Quantitative Analysis: After Going Through The Chapter Student Shall Be Able To UnderstandDocument14 pagesQuantitative Analysis: After Going Through The Chapter Student Shall Be Able To UnderstandNirmal ShresthaNo ratings yet
- Pittig Et AlDocument9 pagesPittig Et AlmarianalfernNo ratings yet
- Petrocchi & CheliDocument16 pagesPetrocchi & ChelimarianalfernNo ratings yet
- The Polyvagal Perspective: Stephen W. PorgesDocument28 pagesThe Polyvagal Perspective: Stephen W. PorgesJohn BakalisNo ratings yet
- Duarte & Pinto-Gouveia, 2017Document6 pagesDuarte & Pinto-Gouveia, 2017marianalfernNo ratings yet
- Gilbert, 2010Document246 pagesGilbert, 2010marianalfernNo ratings yet
- Beauchaine & Thayer, 2015Document13 pagesBeauchaine & Thayer, 2015marianalfernNo ratings yet
- Di Bello Et Al., 2020Document10 pagesDi Bello Et Al., 2020marianalfernNo ratings yet
- Compliance Pack Matrix To 21CFR Part 11 - EcoStruxure Building OperationDocument11 pagesCompliance Pack Matrix To 21CFR Part 11 - EcoStruxure Building OperationmubarakelkadyNo ratings yet
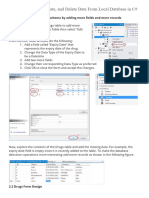
- C - Sharp - Connecting - 2 - Insert, Update, and Delete Data From Local DatabaseDocument9 pagesC - Sharp - Connecting - 2 - Insert, Update, and Delete Data From Local Databaseló MenekülőNo ratings yet
- Handson PLSQLDocument4 pagesHandson PLSQLKeshav100% (2)
- Solutions For The Extra Problems in Module 4Document3 pagesSolutions For The Extra Problems in Module 4Dev HalvawalaNo ratings yet
- Gujarat Technological University: Overview of Python and Data StructuresDocument4 pagesGujarat Technological University: Overview of Python and Data StructuresNiik StarNo ratings yet
- 1) DCL Stands For: Answer - Click HereDocument7 pages1) DCL Stands For: Answer - Click Heremoges tesfayeNo ratings yet
- Sepm Updated 6Document11 pagesSepm Updated 6Hanumanth Rao MareeduNo ratings yet
- Amazon Redshift Interview QuestionsDocument4 pagesAmazon Redshift Interview QuestionshemrajscitNo ratings yet
- Snake Game Using Gui: Project Report ForDocument10 pagesSnake Game Using Gui: Project Report ForSatyam100% (4)
- Rdms Chapter 5Document26 pagesRdms Chapter 5vibhav thakurNo ratings yet
- D77758GC10 - 51 - E Oracle Database 12c New Features For AdministratorsDocument6 pagesD77758GC10 - 51 - E Oracle Database 12c New Features For AdministratorskamuniasNo ratings yet
- Threat Graph: Breach Prevention EngineDocument3 pagesThreat Graph: Breach Prevention EngineshaiehwNo ratings yet
- 4-Mid Term Exam-06-07-2023Document35 pages4-Mid Term Exam-06-07-2023SARTHAK GOYALNo ratings yet
- Analytical Tools For BlockchainDocument8 pagesAnalytical Tools For BlockchainSumit KumarNo ratings yet
- NosrDocument14 pagesNosrDavid Materan PrietoNo ratings yet
- SQL For Data AnalysisDocument14 pagesSQL For Data AnalysisSarah ZarrougNo ratings yet
- ND White Paper - FaceReader Methodology ScreenDocument6 pagesND White Paper - FaceReader Methodology ScreenFabricio VincesNo ratings yet
- Foundation of Information Management Systems-Chapter2Document19 pagesFoundation of Information Management Systems-Chapter2Fuad KapitanNo ratings yet
- Directory - Database - List of Hospitals in India (.XLSX Excel Format) 8th EditionDocument2 pagesDirectory - Database - List of Hospitals in India (.XLSX Excel Format) 8th EditionRohanIngale0% (1)
- Assignment 2 QuestionDocument2 pagesAssignment 2 QuestionNur AinNo ratings yet
- MITS4003 Assessment 1Document6 pagesMITS4003 Assessment 1pmtacsqaNo ratings yet
- DataGrokr-Software Development Internship AssignmentDocument5 pagesDataGrokr-Software Development Internship Assignmentgreatsashi vardhanNo ratings yet
- Wonderware System Platform Cleanup GuideDocument10 pagesWonderware System Platform Cleanup GuideBen SahraouiNo ratings yet
- Database Programming With SQL 9-1: Using GROUP BY and HAVING Clauses Practice ActivitiesDocument2 pagesDatabase Programming With SQL 9-1: Using GROUP BY and HAVING Clauses Practice ActivitiesFlorin CatalinNo ratings yet
- Database Systems Homework SolutionsDocument6 pagesDatabase Systems Homework Solutionscfgf8j8j100% (1)
- Forti SIEMDocument7 pagesForti SIEMbenjaminNo ratings yet
- Structured Query Language (Part 2) : OutlineDocument29 pagesStructured Query Language (Part 2) : OutlineHoàng Vũ NguyễnNo ratings yet
- AZ 104T00A ENU PowerPoint - 10Document24 pagesAZ 104T00A ENU PowerPoint - 10Prakash Ray100% (1)
- SyedIbrahim1 6Document3 pagesSyedIbrahim1 6Manoj kumarNo ratings yet
- Linux&Unix Operation SupportDocument3 pagesLinux&Unix Operation Supportsubhakar madasuNo ratings yet